
今天小编为大家分享一篇关于Go内存分配跟踪调优的文章,文中涉及到一些压测及跟踪分析的工具,以及问题查找方法,希望能对大家有所帮助。
Make it work, make it right, make it fast.
– Kent Beck
最近,我决定对我的一个开源的 Go 项目 Flipt 进行一下深入分析,看能不能找到一些容易获得成绩的点,来优化一下,从而获得性能方面的提升。因为在项目中,路由和中间件都是使用的开源的,所以在这个过程中,我也可以对一些流行的开源项目进行分析,进而可以发现一些它们存在的问题。最终,我的项目可以减少近100倍的内存分配,因此也减少了 GC 回收次数并提高了整体性能。那么来看下我是怎么做到的呢。
1
生成
在开始分析之前,需要先生成大量的网络请求,有了流量才能看到观察到项目中目前存在的问题。这就有个问题,因为我没有在生产环境的项目上使用过 Flipt,那也就没有真正的流量。所以,我使用一款多功能的 HTTP 压测工具, Vegeta,来生成模拟流量。
这个很符合我的需求,它可以在某段时间持续的产生请求,我就可以测量诸如堆分配、堆使用情况、goroutine以及 GC 耗费的时间之类的情况。
经过一些试验,最终得到以下命令:
echo 'POST http://localhost:8080/api/v1/evaluate' | vegeta attack -rate 1000 -duration 1m -body evaluate.json
这个命令以攻击模式来启动 vegeta,以1000次每秒的速率发送 HTTP POST 请求到 Flipt 的 REST API,持续一分钟。发送给 Flipt 用的 JSON 载荷可以不用关心,只要是 Flipt 服务器可以接收的包体即可。
我首先准备向 evaluate 这个接口开炮,因为它里面逻辑比较复杂,在后端有很多的复杂计算,所以应该更有可能暴露出问题。
2
测量
既然我们有解决了流量的问题,那么我们就需要测量,在项目运行时这些流量产生的实际结果。很幸运,Go 自身就提供了一套非常出色的标准工具,我们可以用 pprof 来衡量我们的 Go 应用的性能。关于 pprof 的详细信息,我们在此不深入讨论,后面可能会写相应的文章来单独介绍。
因为在 Flipt 中,我是使用了 go-chi/chi 作为 HTTP 路由,所以在项目中可以很简单的使用 Chi 的配置中间件,来启用 pprof。
我们再开启一个窗口来获取并查看堆的剖面信息:
pprof -http=localhost:9090 localhost:8080/debug/pprof/heap
这里我使用了 Google 的 pprof 工具,该工具可以直接在浏览器中可视化剖面数据。
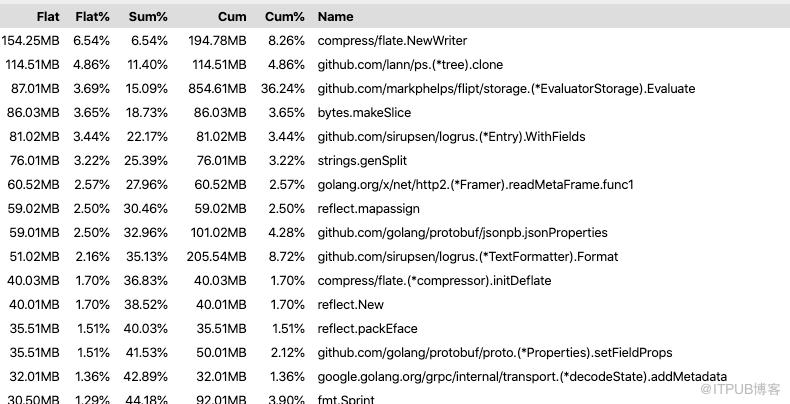
首先,我检查了 inuse_objects 和 inuse_space 来查看堆现场,但是并没有真正注意到太多内容。但是,当我切换到 alloc_objects 和 alloc_space 的时候,才真正勾起我的兴趣。
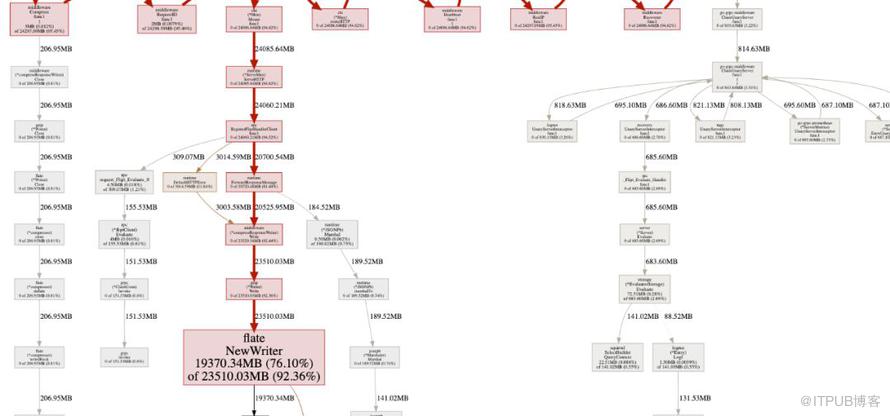
看起来好像是调用了 flate.NewWriter,并且在一分钟的时间内分配了 19370 MB的内存。已经超过 19G!很显然这其中发生了什么事情。但是呢?如果放大图并仔细查看,可以看到 flate.NewWriter 是从gzip.(* Writer).Write 调用的,而它是从 middleware.(* compressResponseWriter).Write 调用的。很快我意识到这与 Flipt 本身的代码无关,而是因为我使用了 Chi 的压缩中间件库,该库中提供的 API 响应的压缩。
// 没错,就是这一行
r.Use(middleware.Compress(gzip.DefaultCompression))我注释掉了上面的代码行,然后重新运行了一下性能测试,并且发现大量的内存分配已经消失了!
在寻求解决方案之前,我想对这些分配以及它是如何影响性能的(尤其是花在 GC 上的时间),有一个新的认识。我想到了 Go 有一个工具 trace 可以让我们查看某段时间内 Go 程序的执行情况,包括一些重要的统计信息,例如堆使用情况、正在运行的数量、网络和系统调用以及对我们最重要的 GC 耗时。
为了有效的捕获跟踪信息,我们需要降低 Vegeta 请求速率,因为经常得到服务器返回的 socket: too many open files 错误。可能是与我本地机器上的 ulimit 设置太小有关。
重新运行 Vegeta:
echo 'POST http://localhost:8080/api/v1/evaluate' | vegeta attack -rate 100 -duration 2m -body evaluate.json
相比较,现在每秒的请求数量是之前的1/10,但是时间更长,因此我们能够捕获有效的跟踪信息。
另外一个窗口:
wget 'http://localhost:8080/debug/pprof/trace?seconds=60' -O profile/trace
60秒生成一个跟踪信息文件,保存到我的本地机器上。可以使用以下方法检查跟踪信息:
go tool trace profile/trace
在浏览器中打开,可以更直观的查看。(关于 go tool trace 我们这儿也不详细介绍,有需要后续会写相应文章来介绍)
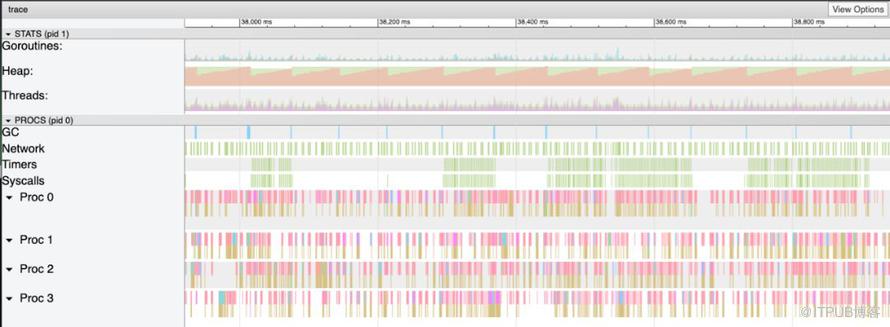
如上图所示,堆好像增长的很快并且伴随着 GC 频繁的出现迅速下降。还可以在 GC 通道中看到明显的蓝色条,表示在 GC 中花费的时间。
这就是我们要搜寻问题解决方案的有力证据。
3
修复
为了查找 flate.NewWriter 导致内存分配问题的原因,我需要查一下 Chi 的源码,首先看下在用版本。
➜ go list -m all | grep chi
github.com/go-chi/chi v3.3.4+incompatible在源码中最终定位到了该方法:
func encoderDeflate(w http.ResponseWriter, level int) io.Writer {
dw, err := flate.NewWriter(w, level)
if err != nil {
return nil
}
return dw
}通过进一步的检查,可以发现 flate.NewWriter 在每次通过中间件输出时都会被调用。这与之前以 1000 rps 请求 API 时看到的大量内存分配相对应。
因为不想失去 API 输出压缩,所以试着先升级下版本,看能不能解决问题,但是新版本中仍然存在。所以就去扒了下 issues/PR,发现作者有提及到重新中间件压缩库。作者提到:对于具有Reset(io.Writer)方法的编码器,使用 sync.Pool 可减少内存开销。
发文前已经将 PR 合并到了 master,简单升级后就解决了这个问题。
4
结果
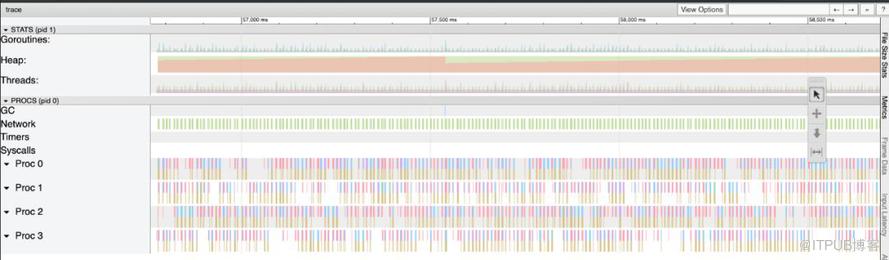
最后再进行一次运行负载测试和跟踪分析,可以验证确实修复了这个问题。
查看新的跟踪信息,可以看到堆以更稳定的速度增长,GC 的总量和 GC 的花费减少了:
总结
- 不要假设(即便是很流行的)开源库已经优化到极致了。
- 一个很小的问题可能会引起巨大的连锁反应,尤其是在高负载下。
- 合适的情况下使用 sync.Pool。
- 负载测试和性能分析是很好的工具。
以上就是本次分享的内容~
如果有什么改进建议,也可以在我们评论区留言,供大家参考学习。
- https://github.com/tsenart/vegeta/
- https://jvns.ca/blog/2017/09/24/profiling-go-with-pprof/
- https://github.com/go-chi/chi/
- https://making.pusher.com/go-tool-trace/