

背景
关系型数据库在执行计数任务时,其执行效率会随着数据量级的增长而降低;当数据量达到亿级别时,计数任务的执行效率已经低到令人不忍直视。在闲鱼团队的关系系统中,我们采用了这样一种方式来实现亿级别数据的毫秒级计数。
挑战
闲鱼现有的业务场景中,用户收藏宝贝、关注他人的数据量,已经达到亿级别。传统的关系型数据库如mysql,在执行有条件的count命令时,效率较低,在数据量较大的场景下,无法有效支撑线上业务的要求。
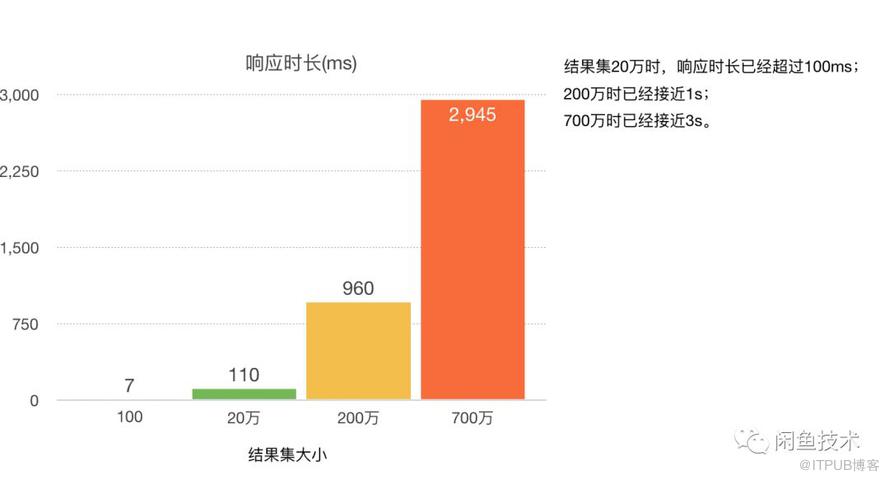
如上图,在亿级别数据量级的关系型数据库存储中按分表key执行count操作,光是响应时长这一个属性就已经远远无法满足线上业务的要求,更不要说频繁执行这种性能较低的查询语句对数据库性能的影响。业内针对海量数据的计数场景,通常采用的解决方案有计数器和定时离线计算两种。两种方式各有优劣:

本文提出了一种基于离线批处理+在线增量统计的设计方案,将复杂耗时的数据库计数操作,替换为多次KV存储的读取和对接操作,在线上业务场景中实现了QPS峰值时响应保持在毫秒级别(10ms以内),成功率也始终接近100%的效果,有力的支撑了业务的开展。
方案
本文提出的计数方案,简而言之,就是定时的将数据全量同步到离线库中进行批处理,实时在线上对增量数据保持统计,最终合并两者的结果得到精准计数值。
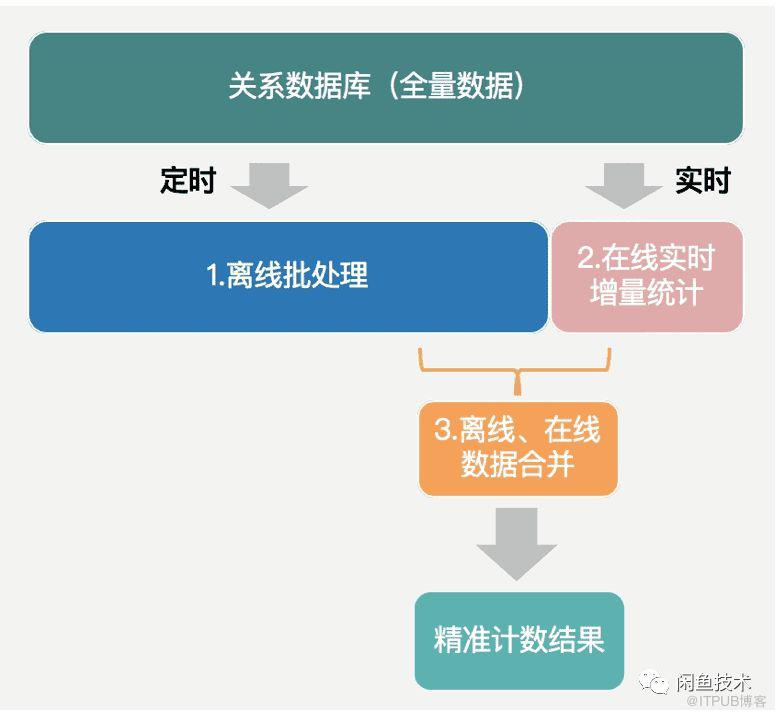
离线批处理
闲鱼目前存储关系数据的方式如下(省略与本文无关字段):
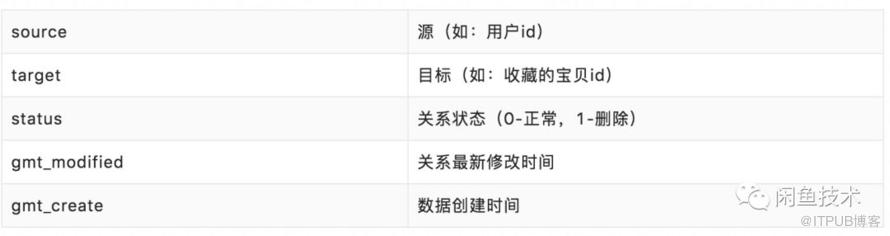
如果想要统计某个用户的某种关系数量,如A用户收藏宝贝数量,只需要获取到source为A且status为0的数据的总条数即可。借助数据离线处理能力,我们首先想到的方案是按时间点对数据进行切割,即:某个时间点(如每天凌晨0点)之前的数据同步到离线存储进行计算,之后再与今天的增量数据进行合并从而得到最终结果,如下图:
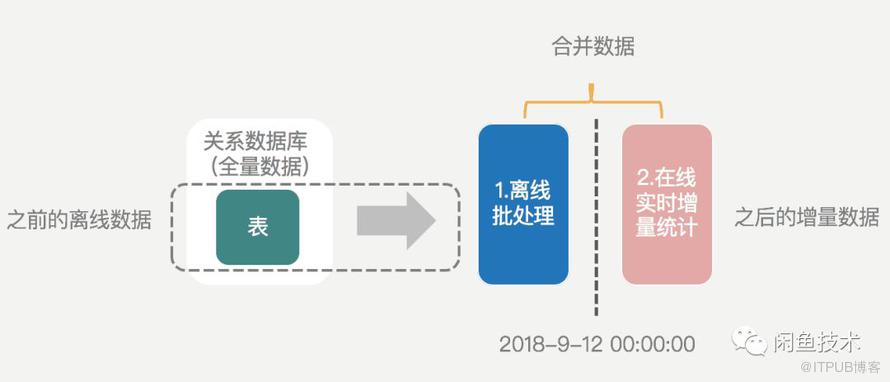
下文中将指定的切割时间点称为“预期快照读时间”。在执行上图中的离线数据同步任务时,闲鱼团队采用的阿里云ODPS离线同步任务,采用扫表的方式完成数据离线。在单表的场景下,借助于mysql的快照读机制可以准确的获取到某个时间点的快照,从而实现数据的离线、在线精准切割。
离线批处理的困境
在实际场景中,海量数据往往必须采用分库分表的方式进行存储。而分库分表后,为了降低对线上业务的影响,离线数据同步任务往往是分批执行,无法保证所有表执行快照读的时间一致,如下图:
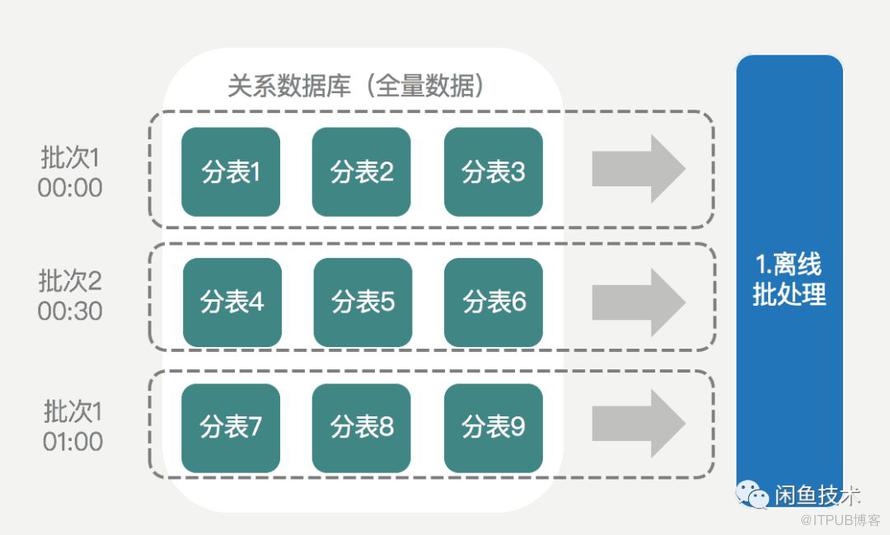
多个分表的快照读时间不一致的情况下,快照读的实际执行时间必然会和预期快照读时间之间存在偏差,如下图:
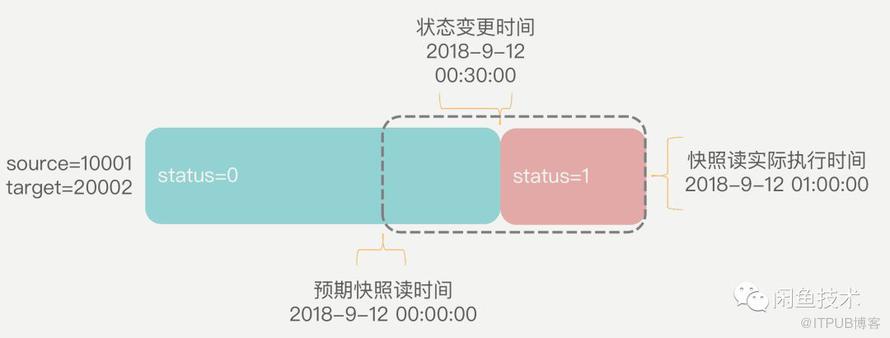
假设在预期快照读时间和快照读实际执行时间的间隔内产生了一条数据变化(在上图中,此变化具体是在凌晨30分时,该关系的状态从0变为了1),实际执行的快照读将无法读取到预期快照读时间的快照,而是最新的数据状态。换言之,当预期快照时间≠数据实际读取时间时,在预期快照读时间到快照读实际执行时间之间产生的数据变化将会污染统计结果。然而由于数据量级过大,必须采用分库分表的存储、分批执行离线任务,于是按照时间点对数据切割的思路就行不通了。
解决方案
为了规避这个问题,必须舍弃固定时间点的数据切割方式,改为将同步任务开始时间作为数据快照读时间,并依据此时间对数据进行切割。使用这样的同步方式,获取到的离线统计结果将如下图所示:
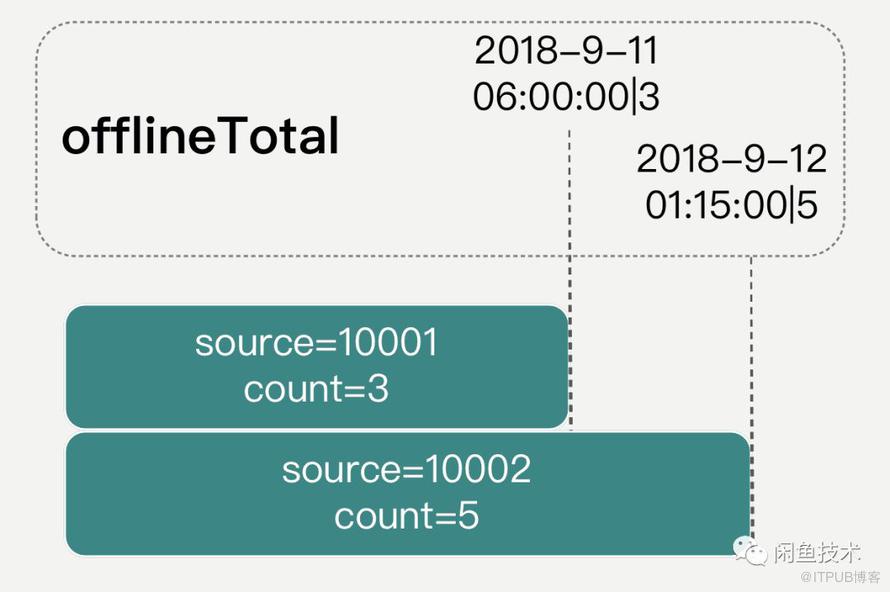
对不同source值计算后得到计数结果的同时,还可以得到该关系的最新更改时间,且不同关系的最新修改时间各不相同。本文将离线统计得到的包含该关系在某个时刻的最新计数值(所有关系中最新一条的修改时间+修改后的合计值),记做offlineTotal。与一般离线任务产出的结果不同的是,offlineTotal中额外包含了该关系的最新一条修改时间,下文中的在线增量数据统计方案,将基于此时间来完成数据的对接与合并。
在线实时增量统计
结合离线数据计数的结果,在线增量数据需要包含如下信息:
- 可以与离线计算结果匹配上的时间;
- 在该时间之后这个关系计数值的变化情况。
在闲鱼的实现中,我们采用KV存储的方式,来记录关系的变化情况。具体记录的值为:每一个source每一天的总增量dailyIncrTotal,以及每一次发生关系更新的那一时刻的增量modifiedTimeIncr,如下表:

统计计数值时,首先使用离线计数值offlineTotal加上当天的总增量dailyIncrTotal得到一个合计值,如下图:
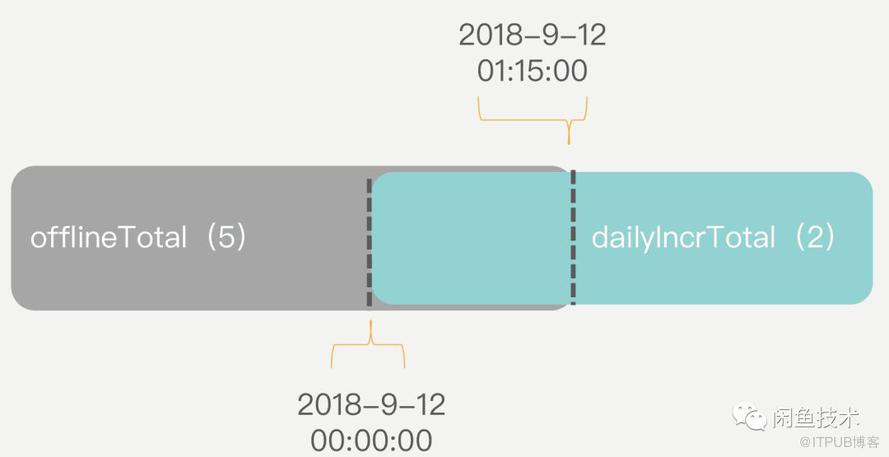
可以看到,由于离线任务统计的数据并不是严格按照时间点进行切割(通常离线任务会在每天凌晨0点至1点之间执行),离线计数值和当日增量之间会存在一些数据上的重合。此时,再根据离线计数值中的最新修改时间,取到在该时刻的增量,从合计值中去掉这部分数据即可:
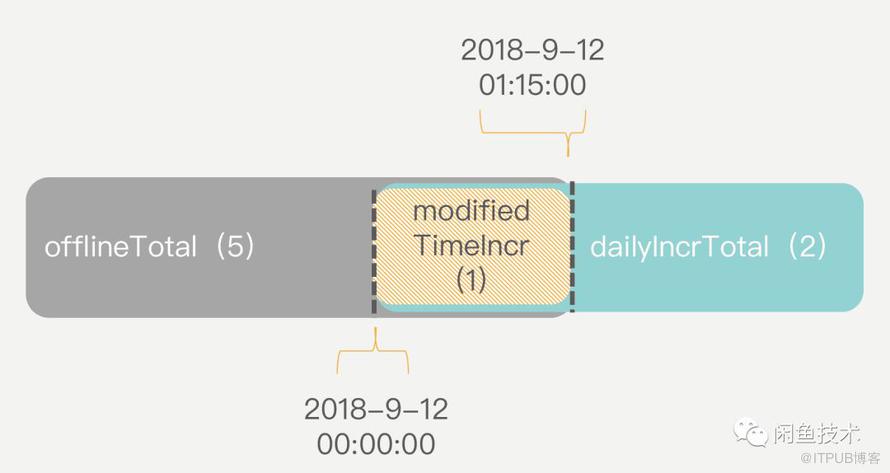

整理这段计算逻辑,可以得到如下公式:
注:ΣdailyIncrTotal表示从离线记录中得到的最新修改时间的日期一直到计数时的日期。
至此,一次完整的计数请求,被替换为2+N次KV存储的查询(N为离线计算结果距当前时间的日期差,一般不会超过一天)。本方案不仅拥有和实时计数器基本相同的响应速度,同时在遇到异常情况时也可以借助于离线批处理的能力,重复运行离线任务,滚动订正数据。
总结
本文介绍了一种在亿数据量级场景下实现快速精准计数的方案,采用离线批处理来减少线上压力、提高计算效率,同时使用KV存储实时记录增量数据快照,实现了计数结果毫秒级响应,且可依赖离线数据订正,希望能够给读者带来一些使用不同角度来思考问题的启发。有时候一些看似非常耗时、难以优化的场景,换个角度来思考,可能会有意想不到的收获。