
数据去识别化是处理个人身份信息的医疗机构和组织必须实施的必要举措。在数据去识别软件的帮助下,掩盖可能使个人面临风险的个人数据变得更加容易。
去识别化数据可以更轻松地与第三方共享和重复用于各种目的,包括研究、人口普查、抽样等。根据 HIPAA 法屏蔽个人身份数据,其他框架(包括 GDPR、CCPA 和 CPRA)也有同样的指示。
我们列出了可用于内部数据脱敏流程的最佳数据去识别工具。继续阅读以了解更多信息。
可供选择的前 5 种数据去识别工具
HIPAA 和类似的数据保护框架确定了 18 个不应供公众访问的标识。其中包括姓名、地理标识符、日期、联系信息、社会安全号码、医疗记录、帐号、IP 地址,以及更多标识符。
这些工具可以通过四种方式帮助对数据进行去标识化:删除、屏蔽、聚合和假名化。在选择可用的数据去标识解决方案时,请确保它们可以帮助您屏蔽所有标识符并限制未经授权的访问。
1。 IBM InfoSphere Optim
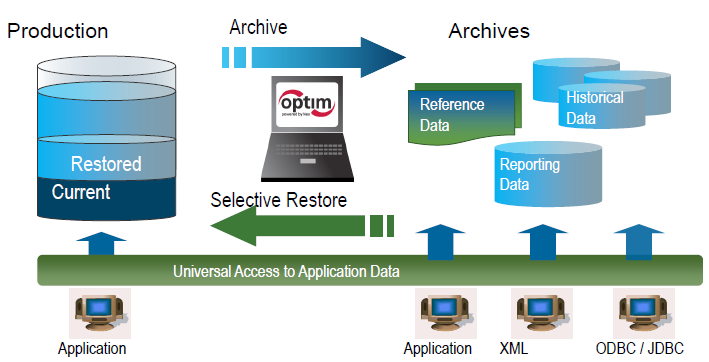
IBM InfoSphere Optim 专为医疗保健行业而设计,提供多种数据去识别选项。
主要特点:
- 轻松屏蔽复杂数据:它可以轻松对姓名、地址和医疗记录等 PII 进行匿名化处理,以保护患者隐私。
- 可以处理大型数据集:IBM InfoSphere 可以通过屏蔽和假名来对隐藏机密信息的大量数据进行去标识化。
- 合成数据生成:它可以创建用于研究和分析目的的人工但真实的数据。
需要改进的领域
- 对于技术水平较低的用户来说,该界面相当复杂,难以浏览。
2. Google 医疗保健 API
Google Healthcare API 允许在快速医疗保健互操作性资源 (FHIR) 中存储和管理数据,同时允许不同医疗保健系统之间进行数据交换。此外,借助这款支持 DICOM 的数据去识别软件,您可以将数据集与 Google Cloud 服务集成,以实现更快的数据分析。

主要特点:
- 操作灵活性:Google Healthcare API 在无服务器基础架构上运行,可以轻松扩展和处理大量数据。
- 基于人工智能的去识别化:使用医疗保健人工智能和机器学习来提高运营效率并进行更好的研究和分析。
需要改进的领域
- 缺乏文档:Google 没有提供足够的文档来设置和运行事物,这导致学习曲线陡峭。
3. AWS Comprehend 医疗
该解决方案可从非结构化临床记录、摘要、病例记录和测试结果中检测并返回有用的医疗信息。为了识别受保护的健康信息 (PHI),它使用自然语言处理功能。

AWS Comprehend Medical
主要特点:
- 识别和提取:AWS Comprehend Medical 符合 HIPAA 要求NLP 功能,使其能够更准确地识别医学敏感信息和个人信息。它还可以发现实体之间的联系,以揭示临床模式和趋势。
- 情绪分析:它可以通过录音、笔记和反馈来评估患者的情绪,以改善和个性化医疗服务。
需要改进的地方:
- 难以使用:界面可以改进以提供更好的用户体验。
4。夏普
使用 Shaip 体验人工数据去识别,因为它还将医疗保健 AI 解决方案与专家智能相结合。 Shaip 提供精确的数据去识别方法,以满足您的需求。集成 Shaip API 以实时访问其服务并按需访问所需信息。

主要功能:
- 有效数据安全:通过预先确定的策略控制数据安全,确保信息完整保存。
- 可扩展的去识别化:通过人类专业知识和人工智能功能,在没有任何阻力的情况下大规模处理和匿名化数据。
改进领域:
- 有学习曲线:如果没有人工干预或帮助,使用 Shaip 工具可能会很复杂。
5。私人人工智能
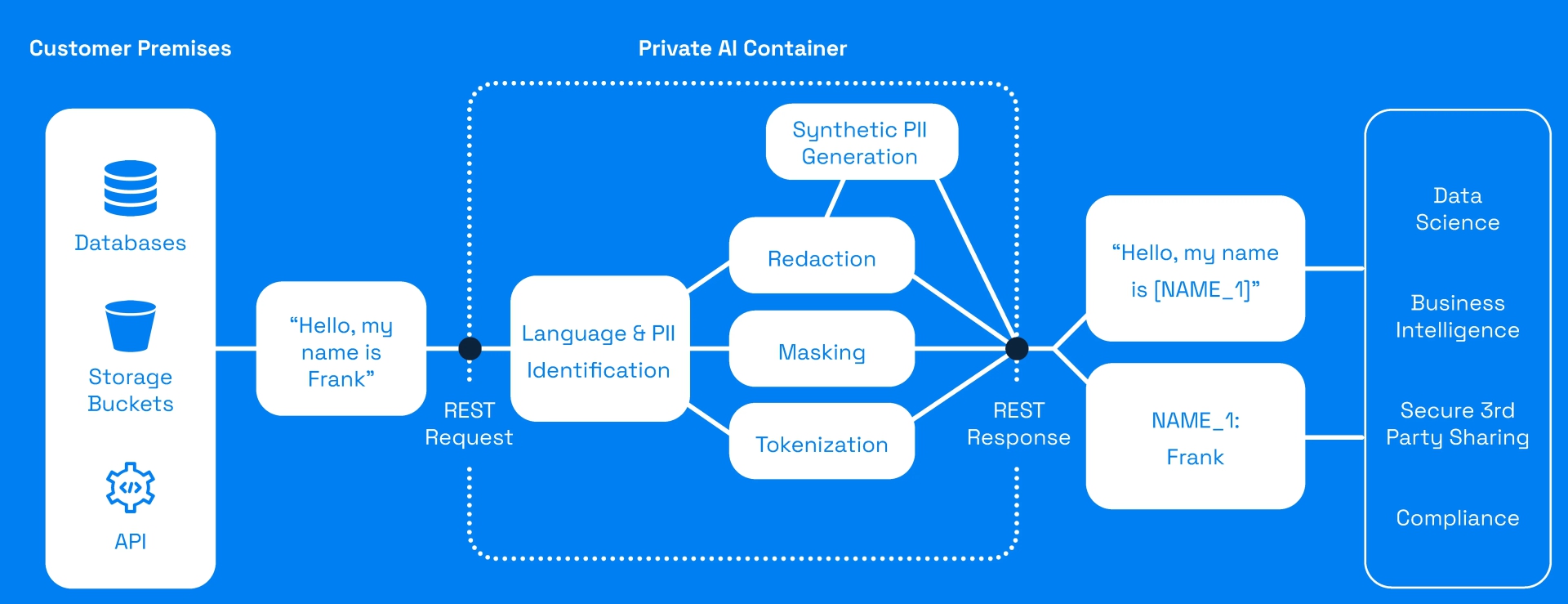
私人人工智能利用先进的机器学习系统来识别和编辑个人身份信息。使用此工具,您可以检测并删除涵盖 52 种语言的约 50 种医疗保健实体。
主要特点:
- 合成数据生成:借助 Private-AI,您可以创建人工数据来取代有效用于研究和测试目的的真实数据。
- 训练 AI 模型:借助保护隐私的机器学习功能,您可以针对敏感数据训练 AI 模型,以实现多种目的。
需要改进的领域
- 辅助功能和可用性:目前,Private AI 的学习曲线很陡峭,如果没有专家的帮助,每个人都很难使用该工具。
最佳数据去识别工具概述
|
工具名称 |
数据去标识化方法 |
支持的数据类型 |
合规性 |
部署 |
自动化 或者 人工监督< /strong> |
|
IBM InfoSphere Optim |
屏蔽
假名化
合成数据生成 |
医疗记录
财务数据
客户数据
一般数据集 |
HIPAA
GDPR |
本地部署和基于云 |
可通过自动化和人工干预进行配置
|
|
Google Healthcare API |
屏蔽
假名化 |
医疗记录
临床文件
索赔数据 |
HIPAA
HL7
FHIR < /td> |
基于云 |
可进行自动化专家评审 |
|
AWS Comprehend Medical |
实体识别
关系提取
情感分析 |
临床记录
报告
< p>摘要 |
HIPAA
21 CFR 第 11 部分 |
基于云
|
自动 |
|
Shaip |
屏蔽
匿名
编辑 < p> 标记化
假名化 |
医疗文本记录
电子健康记录
临床报告
图像 |
HIPAA
GDPR
特定自定义 |
基于云
|
自动化,人工参与循环 |
|
私人人工智能 |
屏蔽
合成数据生成
隐私保护机器学习 |
临床文本
图像
音频 |
GDPR
HIPAA
CPRA < /td> |
基于云
|
可通过自动化和人工审核进行配置。 |