
我们在 Salesforce 中创建自定义应用程序,这些应用程序构建在 Salesforce 数据表中的客户或交易数据之上。编写高效的查询对于维护这些应用程序的性能并确保我们不会遇到 Salesforce 的限制至关重要。您需要遵循某些优化技术来提高查询效率。本文将阐明这些技术。
关于查询性能
很明显,查询的性能完全取决于生产组织中当前数据的复杂性。您可以编写在一种环境中有效但在不同环境中可能失败的高效查询。因此,了解生产环境中数据的当前状态非常重要。您还应该对生产数据的未来增长有一些了解,以便您可以相应地规划查询。将规划查询作为开发周期的一部分。制定例行程序来重新访问生产环境中的旧查询,以确保这些查询仍然有效。本文还将引导您了解可用于衡量 Salesforce 中查询性能的工具。
优化查询的第一步是在 WHERE 子句过滤器中使用索引字段。
索引
某些字段在 Salesforce 中是开箱即用的索引。编写查询时,请确保使用这些字段作为过滤器,以便优化您的查询。

除了默认的索引字段外,您还可以将自定义字段设置为索引。您需要联系 Salesforce 支持才能执行此操作。请注意,上面列表中的外部 ID 属于自定义索引类别。
如果索引是可行的方法,那么将所有过滤器都设置为索引就可以了吗?答案是不。” Salesforce 为您的查询应用“选择性阈值”,只要您的查询将数据提取到该阈值以下,您的查询就是选择性的或优化的。门槛是什么?
- 标准索引阈值: 前 100 万条记录的 30% 和其余记录的 15%,最大限制为 100 万条记录
- 自定义索引阈值:前 100 万条记录的 10% 和其余记录的 5%,最大限制为 333,333 条记录
例如,考虑以下查询并假设您有大约 200 万条业务机会记录。
从机会中选择 ID、名称,其中 RecordTypeId = '1234'由于您使用的是标准索引,因此您的阈值是 450k (300k + 150k)。如果您的查询返回超过 450k 条记录,则您的查询不是选择性的,Salesforce Optimizer 宁愿进行表扫描。如果您使用自定义索引过滤器,则阈值将为 150k。
查询中的常见错误
- 使用
!=或NOT– 即使字段已建立索引,使用!=或NOT也会不要让你的查询有选择性。请改用IN或=。 - 使用
%wildcards%– 如果您在查询中遇到使用%wildcards,请退后一步,问问自己 SOSL 是否是更好的选择。 - 避免空值 – 考虑以下代码:
如果您有机会使用 customlookup__c=null,您的列表将具有 null 值,并且您对 customObject__c 的查询code> 不会有选择性。要解决此问题,仅当 customLookup__c !=null 时,才将 customLookup__c 添加到 Ids 列表。
4.删除的记录可能会影响查询性能 – 使用 isDeleted = false 或清空回收站以提高查询性能。
检查您的查询性能
有两种方法可以检查查询的性能,而无需实际运行查询。
- Salesforce 查询 REST 资源,其中包含 < code>‘解释’ 参数
- 来自开发者控制台的查询计划
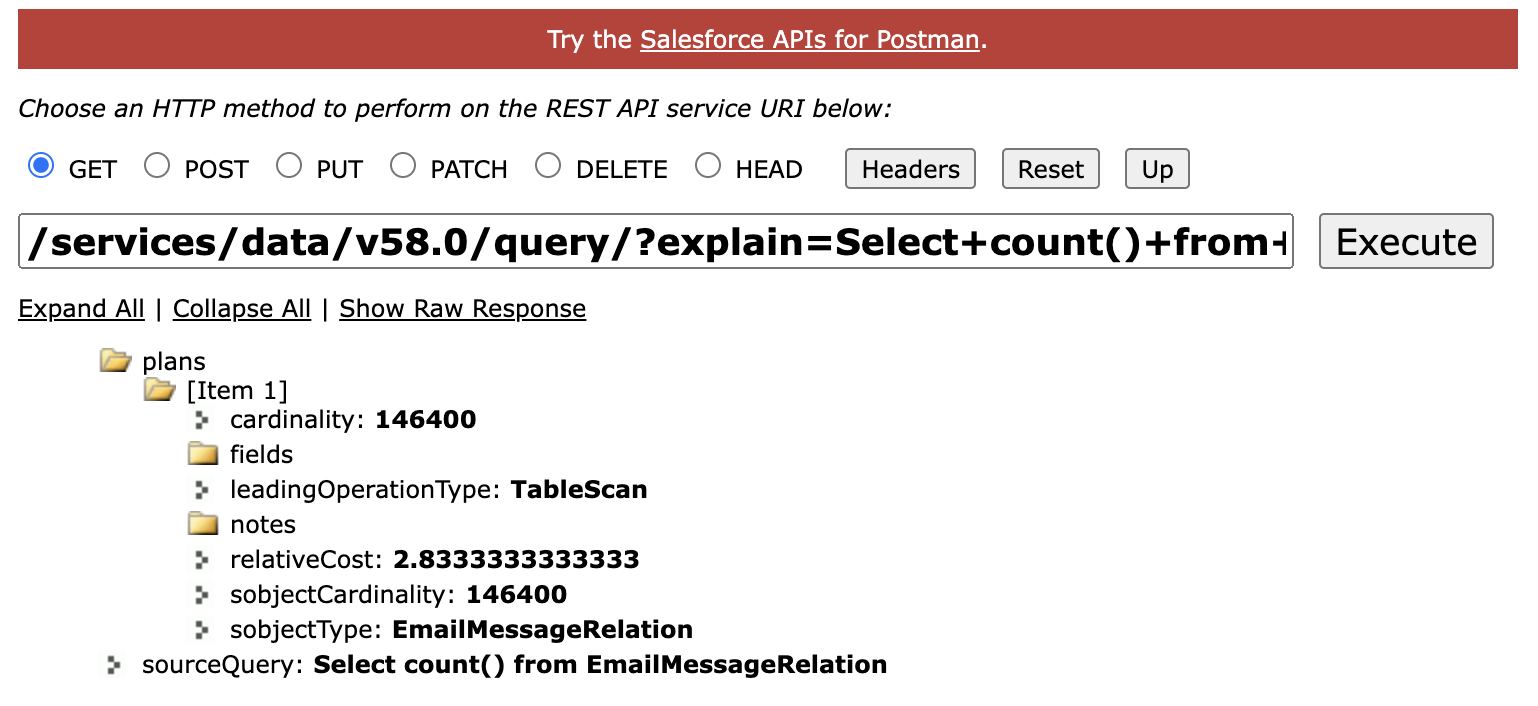
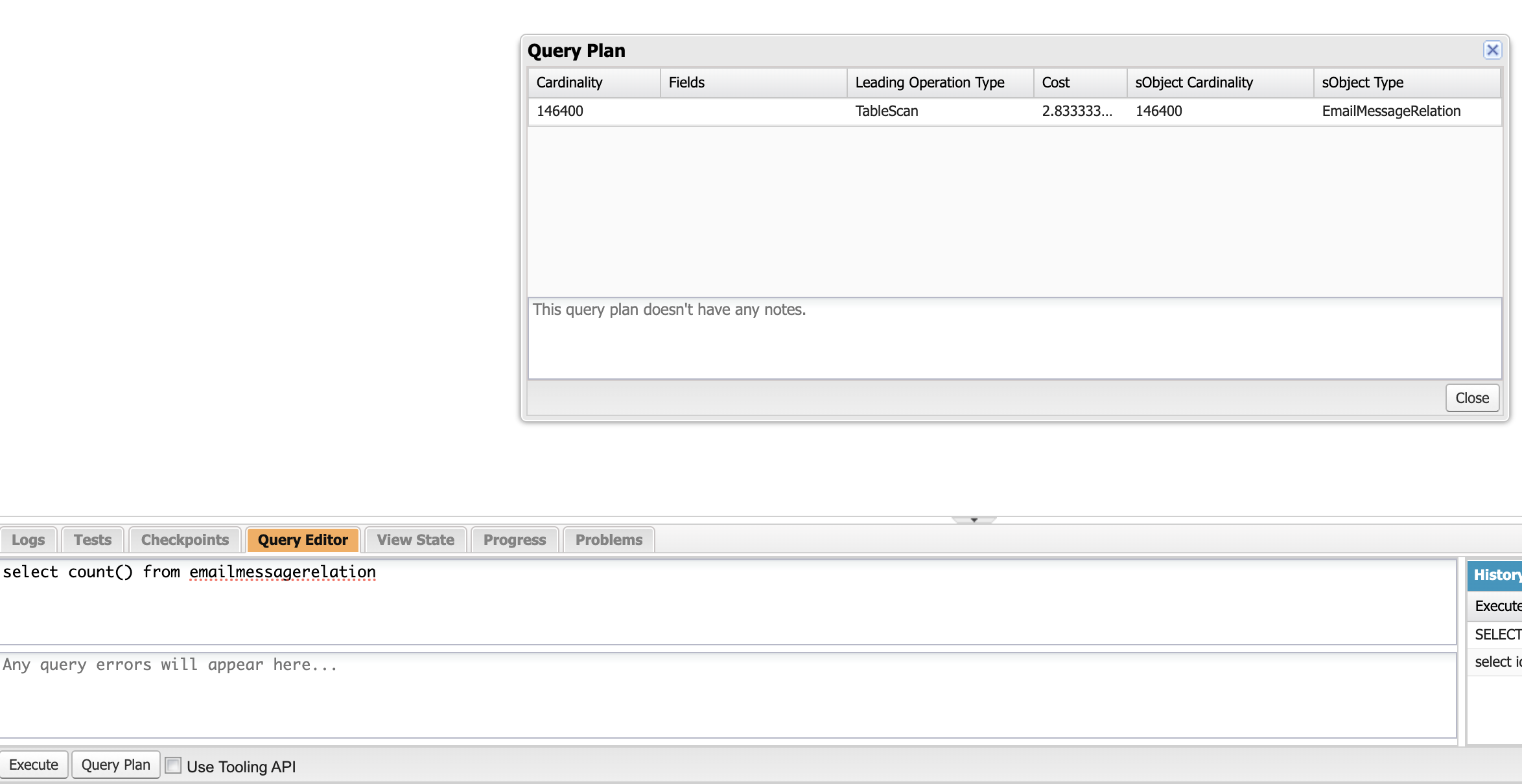
查询性能属性
当您使用上述两种方法运行查询计划时,您将看到具有以下关键属性的“查询计划”。
- 基数 – 主要操作类型将返回的估计记录数
- SObject Cardinality – 查询对象的大概记录数
- 主要操作类型– Salesforce 将用于优化您的查询的主要操作类型;两种常见的类型是索引和表扫描。
- relativeCost 或 Cost – 与选择性阈值相比的查询成本;如果成本大于 1,则查询不是选择性的。
请注意,大多数时候您会在回复中找到多个计划。 Salesforce 将使用成本最低的计划。
