

大数据文摘出品
作者:曹培信
经费不够,2D来凑?
前些天,丰巢智能快递柜被“小学生”用打印照片破解,让人大跌眼镜。
据《人民日报》报道,嘉兴上外秀洲外国语学校402班科学小队向都市快报《好奇实验室》报料:他们在一次课外科学实验中发现,只要用一张打印照片就能代替真人刷脸,骗过小区里的丰巢智能柜,最终取出父母们的货件。随后,小朋友们还发来了几段视频佐证。

并且,都市快报记者也亲自进行了验证,用自拍照真的完成了一次开箱:

并且,记者用偷拍的照片进行测试,也顺利取出了包裹。
随后,@丰巢智能柜官方微博也进行了回应: 关于近期收到的取件反馈,经核实,因该应用为试运营beta版本,在进行小范围测试。收到部分用户友好反馈,已第一时间下线,完善后有关动态,可关注丰巢公告。谢谢大家的支持与鞭策。
为什么会发生这样的问题,还要从人脸识别说起,《人民日报》称,蜂巢的人脸识别系统之所以会被打印的照片轻易“糊弄”,是由于在人脸对齐时使用的是2D识别,而没有用安全级别更高的3D人脸识别和活体检测技术。
作为一家提供智能服务的公司,测试版的说法可能难以让大众相信,毕竟这是2D识别技术本身的问题,难不成是准备用2D识别做测试然后用3D测试上线吗?
所以网友的猜测都是,原本就准备用这个技术上线,但是被一群小学生给发现了。

结合前段时间爆红的人脸应用ZAO引发了很多读者对于“刷脸授权”的担忧,侵权、隐私安全和信息安全的风险。当时,支付宝回应称:支付宝“刷脸支付”采用的是3D人脸识别技术,各类换脸软件有很多,但不管换得有多逼真,都是无法突破刷脸支付的。
人脸识别,3D技术和深度学习就无懈可击吗?
随着人脸识别的发展,反人脸识别也在随之发展,其中对于深度学习人脸识别系统的欺骗,一般是使用电子版的对抗样本,主要用于检验系统的稳定性。
但是这种方式只能攻击线上人脸识别模型或API,无法用于线下的真实人脸识别场景,不具有实际的“反人脸识别”效果,所以很多研究人员还是将目光放在了“外加设备”来对抗基于摄像头的人脸识别。
2013年1月,日本国立信息学研究所的日本研究人员创建了“隐私护目镜”眼镜,该眼镜使用近红外光使脸部下方的脸部无法被脸部识别软件识别。现在最新版本使用钛金属镜架,反光材料和遮罩,利用角度和图案吸收和反射背光源来破坏面部识别技术。
2016年12月,芝加哥的一名定制眼镜工匠斯科特·厄本(Scott Urban)发明了一种称为“反射镜”的反摄像头和面部识别太阳镜。它们反射红外光和可选的可见光,使用户面对相机的白色模糊感。

今年八月,来自莫斯科国立大学、华为莫斯科研究中心的研究者们也找到了针对AI识别人脸的新型攻击方法,仅仅使用一张普通的打印纸就可以让已经广泛用于手机、门禁和支付上的人脸识别系统突然变得不再靠谱。
在这一新研究中,科学家们只需用普通打印机打出一张带有图案的纸条贴在脑门上,就能让目前业内性能领先的公开 Face ID 系统识别出错,这是首次有 AI 算法可以在现实世界中实现攻击。
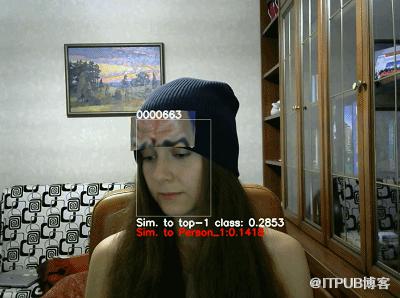
贴上纸条以后,系统会把Person_1识别成另外一些人「0000663」和「0000268」等。
此外,首先将刷脸应用于商业化产品的苹果也遭遇了不少刷脸攻击。去年11月3日,苹果公司发布了IPHONE X,并首次推出了刷脸解锁技术。与此同时,也引发了世界范围内的黑客角逐,意图率先破解该公司具有未来感的最新技术。
仅仅一周,在世界另一端的黑客就声称,他们已经成功复制了人脸,从而可以轻松解锁任何人的IPHONE X,甚至于他们采用的技术可能会比安全研究人员所研究的方法更为简捷。
“我们仅用150美元就制作出了破解iPhoneX面部识别的面具”
越南网络安全公司Bkav发布的博客文章和视频显示,他们使用3D打印塑料模具、硅胶、化妆品和简单的剪纸所组合而成的面具,轻松骗过IPHONE X,破解了脸锁。尽管该破解过程还需要等待其他安全研究机构的确认,但是这一破解方法还是打破了IPHONE X最为昂贵的安全防护措施,特别值得一提的是,该越南安全公司的研究人员仅仅只用150美元就制作出了这种破解面具。
不过,迄今为止,这一破解还只是一个概念证明(proof-of-concept),对于普通iPhone持有者而言,暂时不必慌张,因为该破解过程需要很长时间,花费大量精力,且需要能够接触到iPhone持有者的脸,才能做出破解面具来。
同时,Bkav在其博客文章中还直截了当强调说:“苹果的安全识别工作做得不好,脸锁能够被仿制的面具所欺骗,意味着它并非有效的安全防护机制。”
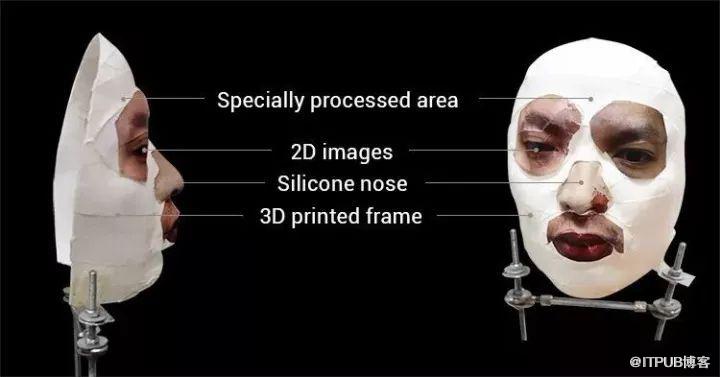
图中第1行:特别加工区域图中第2行:2D图像图中第3行:硅树脂鼻子图中第4行:3D打印框架
在YouTube上发布的视频显示,该公司一名员工把iPhone X前面架子上的布掀开,露出正对着iPhone X的面具,结果手机立即解锁。尽管该手机通过复杂的3D红外线摄影记录机主面部影像程序,并由人工智能驱动建模,研究人员仍旧能够成功骗取解锁,仅需通过制作相对简单的面具:在根据要解锁的机主脸部数字扫描进行3D打印出来的塑料框架上,安装一个雕刻好的硅胶材质的鼻子,一对打印在纸上的二维眼睛和嘴唇。
不过,研究者也承认,他们的技术需要对目标iPhone手机持有者脸部进行详细的测量或数字扫描。研究者还说,他们需要使用手持扫描仪对受试者脸部扫描五分钟以上才行。这就说明在实际运用中,只有经过精心策划才能对目标手机解锁,而不是随随便一个iPhone X手机持有者就可能面临自己手机被轻易解锁的问题。
Deepfake能成为万能钥匙吗?
Deepfake本质上是一种使用AI深度学习,能够将一张图片中人的脸换到其他人的图片上的技术。通过这种技术,我们可以创建一个非常逼真的“假”视频或图片,“换脸”因此得名。
前段时间,一款换脸App“ZAO”就在一夜间火遍社交媒体,但也同时引发了侵权、隐私安全和信息安全的风险。
当时,支付宝就回应称:支付宝“刷脸支付”采用的是3D人脸识别技术,各类换脸软件有很多,但不管换得有多逼真,都是无法突破刷脸支付的。

微信支付也支持人脸识别支付,微信也表示,微信的“刷脸支付”综合使用了3D、红外、RGB等多模态信息,可以有效抵御视频、纸片、面具等的攻击。
活体检测能有效保证人脸识别被照片和面具欺骗的情况,所有现在我们在进行各种安全认证用到人脸识别时,都会让眨眨眼或者摇摇头。
今年八月,《厦门晚报》报道了一则关于男友杀害女友后,在处理尸体以及逃跑过程中,他拿出女友的手机,想借用女友的身份在网上申请小额贷款。他下载了某网贷APP,按步骤操作,拍摄女友的身份证上传,把女友的尸体扶起来,对着手机摄像头进行“人脸识别”,但因系统提示要眨眼,他只好放弃。
随后系统发现异常,即在7秒的“活体识别”环节,贷款申请人无任何眨眼反应,而在语音验证时,是一名男性的声音,与贷款申请者性别不符,所以转入人工审核。
工作人员发现,贷款申请人的照片以及活体识别视频中颈部有棕红色的勒痕,且双眼失焦,面部有青紫色的瘀血,怀疑贷款申请人被害,赶紧向警方报案。
几十年人脸识别发展,从特征提取到深度学习
最后,文摘菌也带各位再一起回顾一下人脸识别发展的历史。
2018年10月,英国赫特福德大学与GBG Plc的研究者发布了一篇综述论文,对人脸识别方法进行了全面的梳理和总结,其中涵盖各种传统方法和如今主流的深度学习方法。
论文链接:https://arxiv.org/pdf/1811.00116.pdf
首个人脸识别算法诞生于七十年代初,尽管指纹识别和虹膜识别更加准确,但是使用条件要求更高,比如,指纹识别需要用户将手指按在传感器上,虹膜识别需要用户与相机靠得很近,语音识别则需要用户大声说话。相对而言,现代人脸识别系统仅需要用户处于相机的视野内(假设他们与相机的距离也合理)。
这使得人脸识别成为了对用户最友好的生物识别方法。这也意味着人脸识别的潜在应用范围更广,因为它也可被部署在用户不期望与系统合作的环境中,比如监控系统中。
人脸识别系统通常由以下构建模块组成:
检测。人脸检测器用于寻找图像中人脸的位置,如果有人脸,就返回包含每张人脸的边界框的坐标。
对齐。人脸对齐的目标是使用一组位于图像中固定位置的参考点来缩放和裁剪人脸图像。这个过程通常需要使用一个特征点检测器来寻找一组人脸特征点,在简单的 2D 对齐情况中,即为寻找最适合参考点的最佳仿射变换。更复杂的 3D 对齐算法还能实现人脸正面化,即将人脸的姿势调整到正面向前。
表征。在人脸表征阶段,人脸图像的像素值会被转换成紧凑且可判别的特征向量,这也被称为模板(template)。理想情况下,同一个主体的所有人脸都应该映射到相似的特征向量。
匹配。在人脸匹配构建模块中,两个模板会进行比较,从而得到一个相似度分数,该分数给出了两者属于同一个主体的可能性。

在深度学习出现以前,人脸识别方法一般分为高维人工特征提取(例如:LBP, Gabor等)和降维两个步骤,代表性的降维方法有PCA, LDA等子空间学习方法和LPP等流行学习方法。在深度学习方法流行之后,代表性方法为从原始的图像空间直接学习判别性的人脸表示。
如今人脸识别方面最常用的一类深度学习方法是卷积神经网络(CNN)。
深度学习方法的主要优势是可用大量数据来训练,从而学到对训练数据中出现的变化情况稳健的人脸表征。这种方法不需要设计对不同类型的类内差异(比如光照、姿势、面部表情、年龄等)稳健的特定特征,而是可以从训练数据中学到它们。
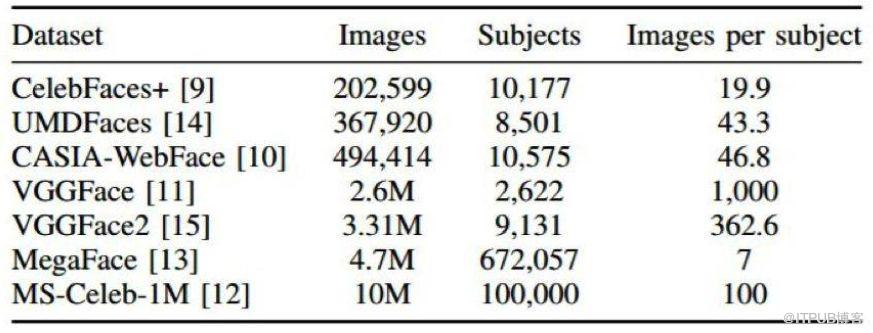
而其主要短板是它们需要使用非常大的数据集来训练,而且这些数据集中需要包含足够的变化,从而可以泛化到未曾见过的样本上。但是现在已经有一些包含大规模自然人脸图像的数据集被公开,可被用来训练CNN模型。
除了学习判别特征,神经网络还可以降维,并可被训练成分类器或使用度量学习方法。CNN 被认为是端到端可训练的系统,无需与任何其它特定方法结合。
用于人脸识别的CNN模型可以使用不同的方法来训练。其中之一是将该问题当作是一个分类问题,训练集中的每个主体都对应一个类别。训练完之后,可以通过去除分类层并将之前层的特征用作人脸表征而将该模型用于识别不存在于训练集中的主体。在深度学习中,这些特征通常被称为瓶颈特征(bottleneck features)。在这第一个训练阶段之后,该模型可以使用其它技术来进一步训练,以为目标应用优化瓶颈特征(比如使用联合贝叶斯或使用一个不同的损失函数来微调该 CNN 模型)。另一种学习人脸表征的常用方法是通过优化配对的人脸或人脸三元组之间的距离度量来直接学习瓶颈特征。