Posted by Socrates on | Featured
AI模型的计算复杂度呈指数级增长,而硬件提供的计算能力呈线性增长。因此,这两个数字之间的差距越来越大,这可以看作是供需问题。
在需求方面,每个人都想训练或部署人工智能模型。在供应方面,我们有英伟达和一些竞争对手。目前,供应方的收益正在飙升,而需求方则在囤货并争夺计算资源。
这是一个简单的表述,但可以很好地解释人工智能的现状。如果说有什么不同的话,那就是过去几年生成式人工智能的爆炸式增长验证了这一说法。那么如何解决这种供需失衡的问题呢?
一种方法是引入更多具有更多功能的人工智能硬件,有些人正在致力于此。如果您不是其中之一,另一种选择是从事软件方面的工作。也就是说,尝试想出一些方法来降低人工智能模型训练和推理的计算强度。
这就是 Deci 首席执行官兼联合创始人 Yonatan Geifman 自 2019 年以来一直致力于的工作。 Deci 专注于构建更高效、更准确的人工智能模型。最初 Deci 发布了计算机视觉模型,后来在其产品组合中添加了一系列语言模型。
有趣的是,这些模型大多数都是开源的。我们采访了 Geifman,探讨了开源人工智能的前景,旨在解决一些关键问题。
开源的好处以及经典构建与购买困境中要考虑的标准是否适用于 AI 大语言模型 (LLM)?如何评估法学硕士并根据组织对其申请的特定需求进行定制?
开源大型语言模型不同
首先,我们来看看“开源”在法学硕士的背景下意味着什么。开源软件已经存在很长一段时间并且已经被充分理解。开源经历了一些动荡,不同的许可方案有其特殊性。
不过,在软件领域,事情相对简单。这一切都与源代码及其可用性有关。拥有源代码以及正确的依赖项和环境意味着能够构建和部署软件。
但是人工智能模型呢?是的,我们那里也有源代码。但从源代码到部署的过程中还有其他工件。我们有用于训练模型的数据集。我们有训练过程和 源代码的权重。某些模型版本还包含元数据,例如指标和模型卡。相同的开源定义可以应用吗?
Geifman 认为,最重要的工件是源代码和权重,因为共享这些工件使人们能够在其他人的工作之上使用和构建,并围绕这些开源衍生品进行协作。拥有元数据固然很好,但在他看来并不是必需的。
但还有数据和训练过程的关键问题。与 Mistral 一样,Deci 也没有分享有关开源模型训练过程的数据或细节。盖夫曼指出,这些都存在商业秘密。他补充道,要获得一个运行良好的模型,不仅需要拥有正确的数据,还需要以正确的方式使用数据的正确部分。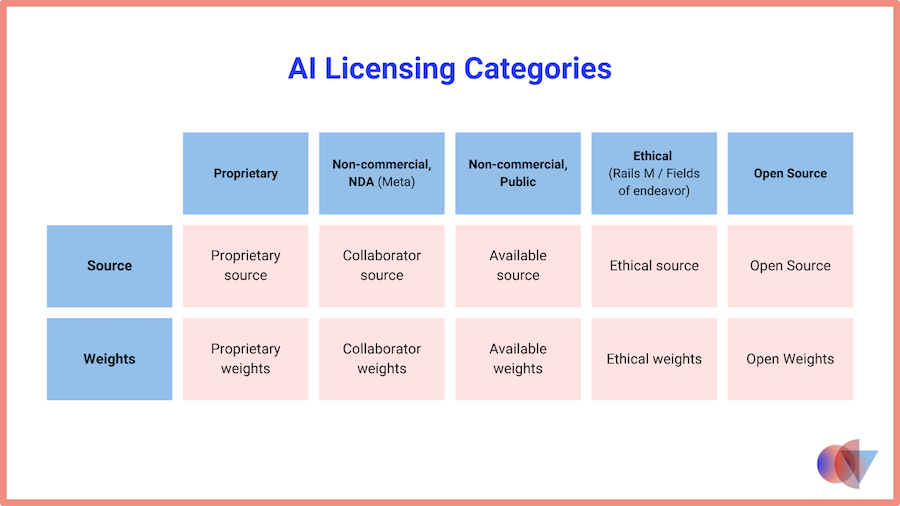
盖夫曼认为,共享数据和训练过程远不如共享模型本身重要。相比之下,OpenAI 的 James Betker 声称“在同一数据集上训练足够长的时间,几乎每个具有足够权重和训练时间的模型都会收敛到同一点”。
可能每个人都会同意这样一个事实:开源软件和开源模型并不完全相同。事实上,如果模型架构和软件没有开源,人工智能也不会达到今天的水平。
无论哪种方式,都有从所有东西都打开到所有东西都关闭的整个范围,大多数模型都介于两者之间。 Geifman 指出,社区中有使用术语开放权重的趋势模型而不是开源模型。
开源大型语言模型与 GPT-4 和 Claude
然而,开放权重或开源,可能更重要的是组织如何使用这些模型。这就是事情看起来更像传统软件的地方。组织有很多选择。他们可以使用托管在自己的基础设施、某些第三方提供商的基础设施中的开源模型,也可以通过 API 使用托管的闭源模型,例如 GPT-4 或 Claude 3。
Geifman 看到的是,许多组织通过利用闭源模型 API 踏上人工智能之旅。他认为原因是这种方式更容易开始,因为时间和专业知识的投资更少。然而,随着时间的推移,这可能不是更明智的方法。
价格可能会波动,但由于闭源 API 附带保费成本将开始增加。但这甚至可能不是最严重的缺点。闭源模型是黑匣子,由第三方控制,这会产生影响。
当事情进展顺利时,使用事物派对模型可能意味着降低进入门槛并安心无忧。但另一方面是,如果模型受到损害、出现故障、出现错误或性能下降,使用它的应用程序将遭受后果。
即使在更新模型时也会出现类似的效果,因为它们的行为可能会不一致地变化。即时工程本身就很脆弱,因此添加此参数使得在闭源 LLM 之上构建应用程序成为一种不确定性的练习。
还需要注意隐私和安全问题,因为敏感数据可能会暴露。这就是为什么一些组织不仅不使用闭源模型,而且还彻底禁止其员工使用它们。
大型语言模型定制:微调与 RAG
以上大部分内容并非特定于人工智能模型或法学硕士。定制是具体的,也是现实应用程序通常不需要的。是否通过 微调或 RAG,LLM 需要根据用户的需求和数据集进行定制。
正如 Geifman 指出的,尽管微调和 RAG 旨在实现相似的目标,但它们的工作方式却截然不同。微调是改变特定数据集的实际模型,而RAG专注于在生成阶段注入数据。
Geifman 发现,对于 RAG,如果您希望将其应用于开源或闭源模型,则没有太大区别。另一方面,对于开源模型来说,微调会容易得多。在微调与 RAG 的争论中,Geifman 认为未来是两者的结合。
<块引用>
“使用 RAG 有一些好处,主要是在数据隐私方面。您不想在私有数据上训练模型,但在 RAG 中,您可以在提示中用私有数据补充模型。这是使用 RAG 的好处之一,而且事实上你不需要一直微调模型以获得更新的数据,”盖夫曼说。
值得一提的是,微调和 RAG 都在不断发展,诸如 LoRA+< /a> 和修正 RAG 分别。不过,总体而言,Geifman 认为,与闭源相比,未来在开源中构建更复杂的用例会更容易,特别是当准确性差距得到弥补时。
提到准确性,我们就会想到另一个多元方程,即如何评估 LLM 的表现。目前,正如 Geifman 提到的,似乎 OpenAI 的 GPT-4 或 Anthropic 最近发布的 Claude 3 等闭源模型在准确性方面比开源模型具有优势。但这里有很多细微差别。
评估大型语言模型
Geifman 预测,这一差距将在 2024 年底前缩小。但正如最近所证明的那样,专门针对特定任务进行仔细微调的模型可以胜过这些任务的更大模型。 LoRA Land,由 25 个经过微调的开源 Mistral-7B 模型组成的集合,其性能始终优于基本模型 70%,优于 GPT-4 4 -15%,取决于任务。
然而,更重要的是全面评估绩效。通常人们倾向于将法学硕士的表现与准确性等同起来。虽然准确性是一个重要指标,但还需要考虑许多其他参数。
这些都围绕着法学硕士将用于的应用程序的性质。例如,即使是文档摘要等典型用例,根据文档类型和摘要的用途也有不同的要求。
延迟和吞吐量也非常重要,这同样取决于应用程序的要求。某些应用程序可能比其他应用程序更宽容。然后是
成本。尽管这本身不是一个指标,但它也是需要考虑的因素。

评估软件平台是一门艺术和科学。评估大型语言模型更加细致入微
盖夫曼的建议?首先,如果您需要速度,您最好使用更小的、经过微调的、为您的应用程序量身定制的模型。其次,对于大多数 B2B 应用程序,您不需要 GPT-4 级别的准确性。如果您想总结文档,可以使用 中型语言模型,具有良好的性能、更低的延迟和更高的性价比。
至于如何从整体上评估模型,这仍然是一个未解决的问题。目前的两种主要选择是人工评估和使用法学硕士来评估另一个法学硕士。两者都有优点和缺点,并且像往常一样,存在很多细微差别和盲点。
您可能会注意到这一切都很好,但并不是每个人都需要熟悉 LLM 评估的所有细微差别。总有Hugging Face排行榜,它已成为事实上的评估场对于所有法学硕士。然而,就像任何其他基准一样,这些指标仅具有指示性。
底线是,如果你想评估一个模型是否适合手头的任务,你可以站在巨人的肩膀上,但你必须自己投入工作。这意味着制定您的要求、开发现实的评估场景并对法学硕士进行测试。
市场展望
最后,其他领域的最佳实践和原则也至少部分适用于法学硕士,这一事实对于希望将法学硕士纳入其申请的组织来说可能是个好消息。正如 Geifman 指出的那样,法学硕士及其能力以及将其整合到多个垂直领域的企业中的潜力令人兴奋,这为市场注入了活力。
Geifman 表示,到 2023 年,Deci 的人工智能平台市场规模将增长两倍以上。Deci 的市场分为两个部分,每个部分都有自己的特点。
其中之一是计算机视觉,比较成熟。正如 Geifman 所说,人们知道自己需要什么,并且他们正在寻找每个公司和团队都有多个用例的生产用例。
然后是GenAI部分,人们更多地处于探索阶段。 Geifman 相信 2024 年我们将看到许多基于 GenAI 的项目投入生产。他将文档摘要和客户服务视为主要用例。
Deci 使用开源模型解决计算机视觉和 GenAI 问题。 Deci 的产品包括 SuperGradients、一个用于训练基于 PyTorch 的计算机视觉模型的库、DeciLM 6B 和 DeciLM Geifman 指出,Mistral 7B 的准确性与 Mistral 7B 类似,但效率和性能更高。此外,DeciCoder 1B 和 DeciCoder 6B 代码生成模型以及 DeciDiffusion 文本到图像模型也具有更高的效率和性能。
这些模型可以免费使用,并提供额外的工具来自定义、微调和部署它们。 Deci 的 LLM 部署环境称为 Infery-LLM。这是一种开放核心方法,其中模型是开源的,增值工具是商业的。
为了展示 Infery-LLM 带来的价值,Geifman 表示,在使用和不使用 Infery-LLM 的情况下运行 DeciLM 7B 的性能分别是 Mistral 7B 的 4.5 倍和 2 倍。 Deci 还致力于发布更多具有更多参数和更好性能的法学硕士。
