
什么是 ETL?
ETL 是提取、转换和加载的缩写。简单地说,它只是在两个位置之间复制数据。[1]
- 提取:从不同类型的源(包括数据库)读取数据的过程。
- 转换:将提取的数据转换为特定格式。转换还涉及使用系统中的其他数据来丰富数据。
- 加载:将数据写入目标数据库、数据仓库或其他系统的过程。
ETL 可分为两类,与基础结构有关。
传统 ETL
回到今天,数据通常位于我们称为操作数据库、文件和数据仓库的热门位置。数据每天在这些位置之间移动几次。ETL 工具和脚本以临时方式插入,以在源和目标到达时连接它们。
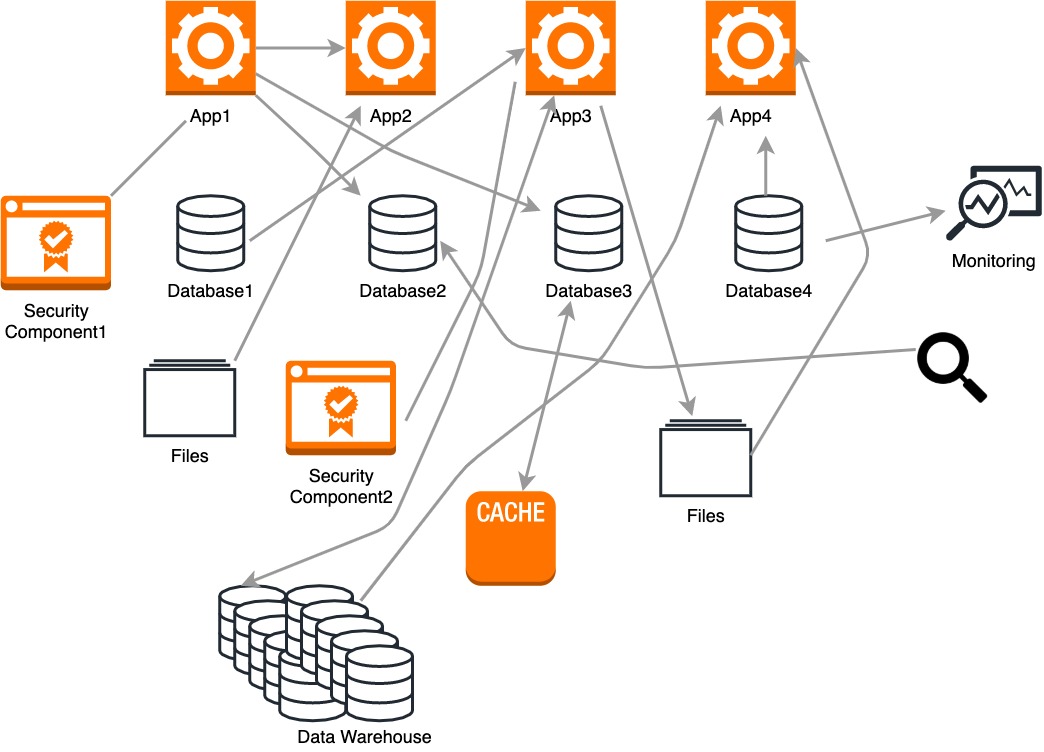
这种特定的体系结构是难以管理且相当复杂的。以下是传统ETL体系结构的一些缺点:
- 数据库、文件和数据仓库之间的处理以批处理方式完成。
- 目前,大多数公司倾向于对实时数据进行分析和操作。但是,传统工具的设计并不用于处理日志、传感器数据、指标数据等。
- 非常大的域的数据建模需要全局架构。
- 传统的 ETL 过程速度缓慢、耗时且耗费资源。
- 传统架构当时只关注技术。因此,引入了新技术,应用程序和工具必须从头开始编写才能连接。
随着时间的推移,大数据改变了流程的顺序。数据被提取并加载到存储库,并保留在原格式。数据分析人员或其他系统需要时,都会转换数据。这称为ELT。但是,在处理仓库中的数据时,这最有利。系统,例如
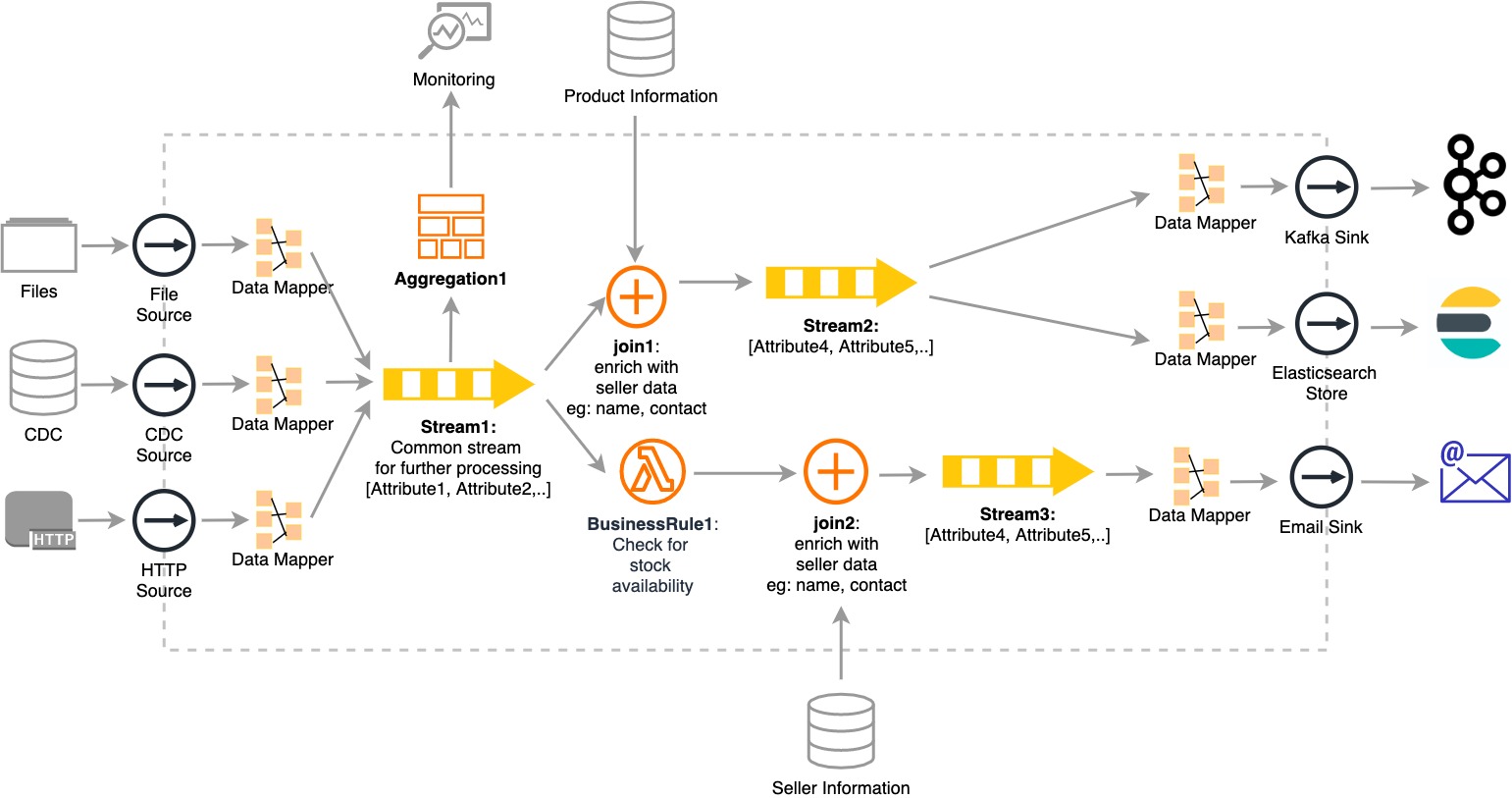
您可能还喜欢: 与十年前相比,现代世界数据及其使用发生了巨大变化。在处理现代数据时,传统的 ETL 流程存在差距。以下是造成这种情况的一些主要原因: 源和目标终结点应与业务逻辑分离。数据映射层应允许以不影响转换的方式无缝插入新源和端点。 由于对数据的新需求,数据是驱动组织的燃料。大多数传统系统在大多数组织中仍然运行,并且使用数据库和文件系统。同样的组织现在正在努力走向新的系统和新技术。 这些技术能够处理大数据的增长和高数据速率,例如每秒数以万计的记录,如 Kafka、ActiveMQ 等。 使用流式处理 ETL 集成体系结构,组织无需规划、设计和实施复杂的体系结构来填补传统系统和当前系统之间的差距。流式处理 ETL 架构是可扩展和可管理的,同时可满足大量实时数据,具有高多样性,包括不断发展的架构。 源汇模型是通过分离解压缩和转换加载引入的,transformation也使系统向前发展兼容新技术和功能。此功能可以通过多个系统来实现,例如Apache Kafka(带KSQL)、塔伦德、黑兹尔卡斯特、斯特里姆和WSO2 流集成商(与Siddhi IO)。 如上所述,旧系统通常会将所有数据转储到数据库和可供分批处理的文件系统。此方案说明传统事件源(如文件和更改数据捕获 (CDC) 如何与新的流集成器平台集成。 让我们考虑一个生产工厂中具有以下功能的实际方案。 传统的制度, 在传统的ETL工具中: 流媒体平台架构如何解决现代 ETL 问题 通过上述架构,我们可以看到流式处理平台如何将传统系统(如文件和 CDC)与使用 Kafka 和 HTTP 进行 ETL 处理的现代系统集成。 有关 WSO2 流式处理集成器如何为复杂的 ETL 方案提供解决方案的 WSO2 流式处理器,您可以参考此流式处理 ETL。 1. https://medium.com/sciforce/what-is-etl-1df5305bb341. . . .
实时流处理与阿帕奇卡夫卡第一部分。ETL 的当前状态
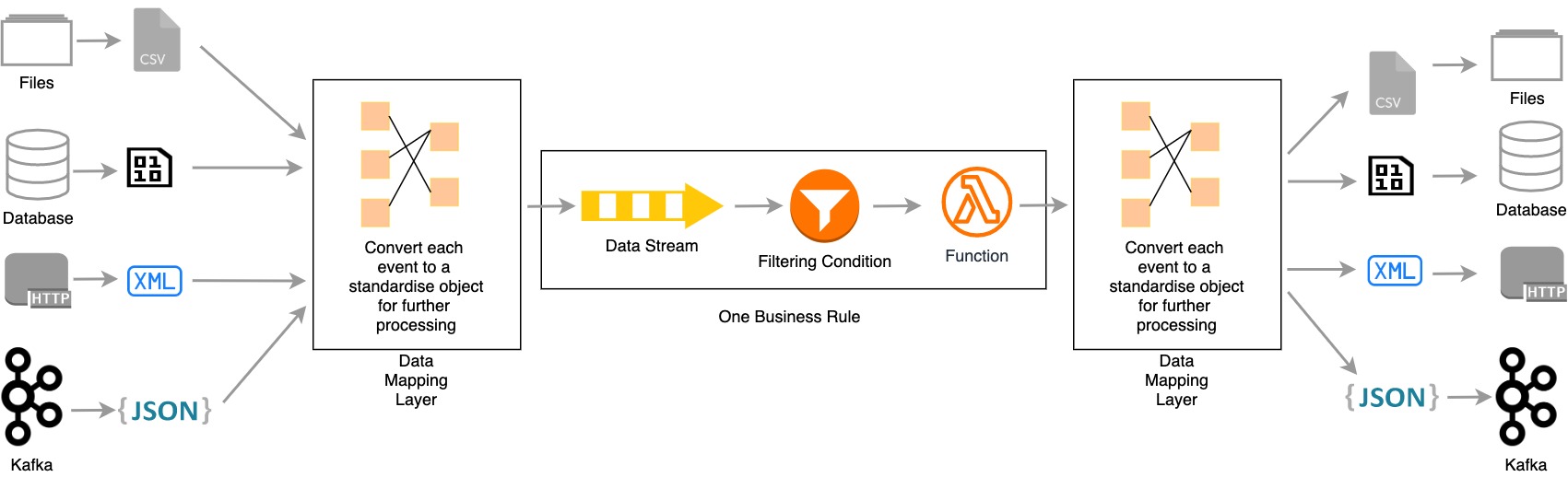
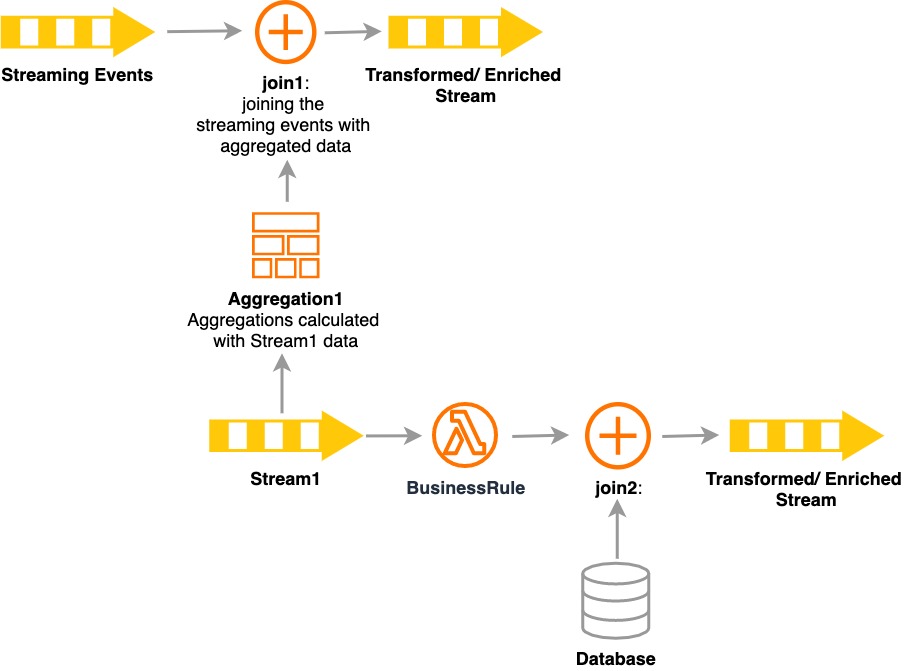
将 ETL 流式传输到救援
现代ETL功能
进一步阅读