
数据库间实时数据传输服务可简化业务系统的数据架构,使其专注于业务开发。DBIO是爱奇艺研发的数据库间实时数据传输服务,用于同异构数据库间实时复制与数据变更捕获,是业务系统数据共享的核心通道。

作者:郭磊涛
编辑:张晓艺
郭磊涛,爱奇艺数据库服务负责人2007年博士毕业于中国科技大学,进入中国移动研究院负责大数据平台的建设,2014年加入爱奇艺负责数据库内核、中间件及运维系统的研发,热衷于 Hadoop 生态系统优化和数据库高效运维架构。
本文根据郭磊涛老师在DTCC数据库大会分享内容整理而成,将介绍 DBIO 的设计与实现,重点分享在源和目标端故障时如何保证服务高可用、如何优雅的支持多种源与目标端系统以及如何高效运维等方案。同时,也将介绍 DBIO 在数据变更订阅、异地多活、数据归档等方面的应用案例。
1. 爱奇艺数据库架构
爱奇艺是一家以科技创新为驱动的伟大娱乐公司,科技创新的前提是提供稳定、安全、高性价比的基础服务。数据库服务团队负责爱奇艺所有业务线的数据库、数据库中间件等的开发与运维工作。面对不同的业务角色,我们针对性地提供相应的服务。我们目前提供了基于开源和自研的缓存、kv、文档、图及关系数据库,部署在物理机、虚机和公有云上,网络环境异构、集群跨DC,这些都给数据库运维带来了巨大挑战。
我们面向DBA的运维管理系统经历了脚本、工具化、平台化到智能化演变。运维平台化可以确保规范运维,简化运维操作,减少运维失误。在此基础之上,尝试进行智能运维的探索。首先将常见故障及告警的根因定位封装为工具,手动或自动触发后对系统进行全面诊断。比如,MySQL主从复制延时告警可能是由写入吞吐量过高、网络故障、Slave节点IO/CPU打满、大事务等因素引起,通过这些工具快速定位根因。另外,我们对报警也进行了多维度的聚合,从而减少不必要的告警或提高某些告警优先级等。同时,我们还对各数据库集群进行容量管理,对不合理的资源进行动态缩容和扩容,并通过合理的数据库实例分配和迁移策略,提升服务器利用率实现降低成本的目的。
对于应用的开发者,我们提供客户端SDK及中间件,来实现运维操作对业务的透明,从而让业务只关注业务逻辑的开发,而涉及到后端DB的工作则由SDK去处理,如连接超时和重试等机制。除了提高运维效率和开发效率外,自服务平台提供详细信息展示、预警报告、自助运维等功能,并结合智能客服来降低需人工处理的业务咨询量。
本次将介绍数据库服务团队研发的数据传输中间件DBIO,它可以协助业务实现多端数据全量和实时同步。
2. DBIO简介
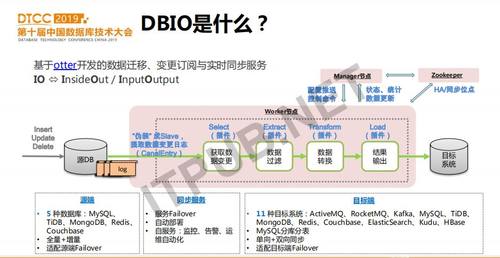
DBIO是数据库的数据迁移、实时变更订阅与同步服务。它基于阿里开源的otter项目逐步完善而来,目标是成为数据库间数据共享的通道,实现任意数据库间数据的灵活搬迁与同步,让业务只关注业务逻辑开发,而底层数据互通则通过DBIO来实现。
那么怎么实现数据的互通呢?首先,我们要解决的是如何高效的获取源端数据库的实时数据。各种数据库,包括kv、文档和关系数据库在有数据变更时,比如插入、更新、删除等都会记录变更日志。这些变更日志一方面用于故障后重放以保证数据完整性,另一方面用于主库和从库之间的数据同步。那么,我们只需要获取数据库的变更日志,就可以得到实时的数据库数据。 otter通过将其伪装为MySQL的slave,获取到mysql binlog,并经过ETL数据处理后写入到目标系统。otter部署和使用时主要包括3个服务,即manager提供了web配置和同步任务控制接口,本身并不承担数据同步的功能,真正的同步任务都运行在worker节点上,zookeeper用于记录部分元数据及服务高可用的管理。
我们对otter做了扩展和优化,从而更匹配我们的业务需求,也更易于管理。比如,对源端数据库的支持从MySQL扩展到5种数据库,对目标端系统从MySQL扩展到11种,增加了内置向MySQL分库分表同步的组件。支持了全量数据的同步、增强了HA和双向同步、数据处理ETL各阶段都支持用户自定义插件从而实现更加灵活的数据条件过滤、类型/字段映射转换以及写入到目前端时数据存储格式优化等等。本文将主要介绍我们对otter的功能增强的难点、实现方案及应用实践。希望这些经验可以帮助到大家了解如何基于otter来构建一个数据库数据迁移与同步的服务,以及如何灵活的使用这个服务来满足各种业务需求。
3. DBIO关键技术
3.1 源端支持更多的数据库
在DBIO中除MySQL外,还支持TiDB、MongoDB、Redis、CB数据的实时获取与同步。
1、TIDB
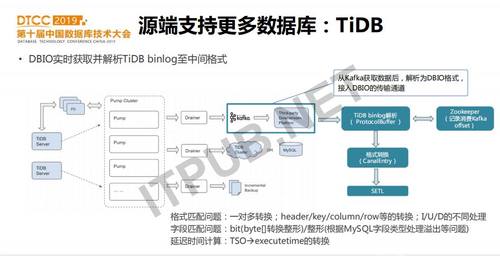
TiDB是PingCAP公司开源的分布式数据库,适用于TP和AP的场景。在2017年下半年爱奇艺开始调研测试TiDB,并在2018年中正式上线,目前已经在视频上传、生产、风控等核心业务线应用。我们上线的业务大都是从MySQL迁移到TiDB的,MySQL上的数据变更订阅、同步等也需要在TiDB上支持。同时,TiDB版本更新非常快,为了应对TiDB可能带来的不稳定以及频繁的升级等,我们需要把TiDB的数据同步到MySQL等其它系统。因此,我们在DBIO的源端也增加了TiDB。
TiDB的binlog是由TiDB Server生成并发送至Pump Cluster进行局部排序,之后再由Drainer模块归并排序最终形成全局有序的binlog日志,并同步到下游下游支持TiDB、MySQL等,同时为了方便接入其它系统,也支持Kafka。DBIO正是通过Kafka取到TiDB binlog,消费Kfaka消息,解析并转换成DBIO的中间数据格式。我们在接入时主要遇到一些数据格式、数据类型等转换的问题。由于TiDB binlog需要经过Pump cluster->Drainer->Kafka等几个流程才可以得到,因此以TiDB为源的同步延时相对要高一些,实测在4-8秒。
2、其他
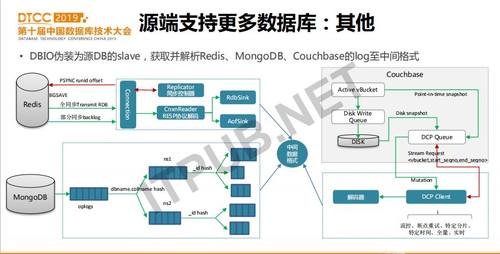
对于接入Redis和Couchbase(后简称cb)作为源端,我们采用和接入MySQL类似的方式,即DBIO伪装成Redis和cb的Slave节点,来获取全量和增量的数据变更。接入Redis时,我们启动一个同步控制器Replicator,向Redis Slave发送PSYNC runid offset指令,Redis会根据runid和offset来判断是否需要先做全量数据同步,如果需要的话会执行bgsave把内存中的数据存成rdb文件回传。如果不需要,就从复制缓冲区backlog中直接取操作指令给DBIO。要注意的是,全量和增量数据格式不一样,需要分别处理。
Couchbase是一个分布式NoSQL数据库,一般作为缓存使用(后简称cb)。cb的kv读写性能高于redis,且扩展性非常好,所以在爱奇艺的几乎所有在线业务都在使用cb。我们在DBIO中接入cb的主要动机是希望把cb数据转存到其它更便宜的kv存储中。因为cb数据要基于全内存存储才可以达到很高的性能,成本较高。而我们发现有些业务虽然使用cb,但它们实际的qps和延迟要求并不高。这时,我们会建议它们迁移到同样高性能但成本更低的基于ssd和内存的kv存储上,这个kv存储在我们内部的项目叫HiKV。HiKV是基于wisckey的存储方式,即key和value分开存储,key在内存,value在ssd,优化了LSM-Tree的写放大问题。把cb接入到DBIO源端相比其它几个系统要简单一些,因为cb的数据复制协议DCP可以把cb变更,包括从磁盘上的存量数据以及内存中的数据写入到DCP queue队列中。我们只需要启动一个DCP Client来读取queue中的数据,解析即可。DCP Client读数据时,会带上起止序列号seqno,已经消费的序列号会记录在zookeeper中。如果DCP client故障,DBIO failover到另外一台服务器再从zookeeper读取seqno就可以继续从cb获取数据了。
类似的方式,也可以得到mongodb的操作日志oplog,详细的做法就不赘述了。
3.2 支持更多目标端系统
除了接入更多的源端外,我们对同步的目标端也做了扩展。
DBIO在读取到数据并转换为中间数据格式后,会通过ETL流程对数据进行过滤、转换等。如果要接入更多目标端,只需要扩容Load模块即可。Load模块会根据配置来判断目标是不是MySQL或TiDB,如果是MySQL或TiDB,会继续判断是否向分库分表同步等等。如果目标端不是MySQL/TiDB,则会进入初始化异构目标端Loader的过程,这个过程会建立与目标端的连接,并将数据批量的写入。在修改Load模块时,我们遇到的问题主要是不同目标端数据格式不同的问题、每种系统写入成功与否的确认方式、异常处理以及如何保证幂等。对于批量Load失败时,DBIO会回落到逐条Load,以保证数据写入成功。如果重试多次都写入失败,则该批次同步失败,再次进行重试。
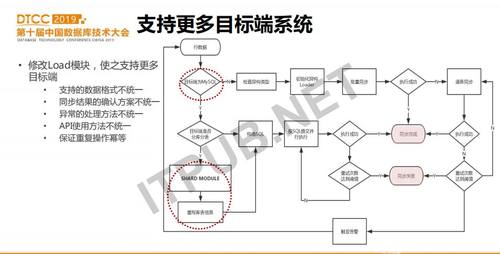
目标端分成两个大的通道,其一是原生支持的MySQL,相对来说会比较成熟一些。我们拿到一条数据之后,来看它目标端是不是MySQL,如果是,就走MySQL通道,如果不是,就走异构的数据同步通道。如果是像MySQL同步,我们会看目标端是不是分库分表,如果是分库分表,会有一个组件来自动将其同步至分库分表。如果是向异构数据同步,我们会先做批量,如果是批量有失败,再逐条加载。
在接入多种目标端时,也支持向MySQL分库分表的同步。目标端是分库分表的场景在爱奇艺非常常见。比如在业务上线初期并未预想到数据的增量,上线一段时间后发现只有分库分表才能满足需求。通过DBIO可以帮业务提前把全量和增量数据同步至分库。在接入分库分表时我们也走了一些弯路,最初为了接入方便,我们直接用mysql proxy实现分库分表,DBIO写proxy。但是因为引入了proxy,同步出现错误或延时,问题排查比较复杂,而且proxy为了实现高可用还需要引入虚拟ip或域名,这又增加了一层依赖。随后,我们抛弃了proxy这种外接的分库分表中间件,而是把这个功能紧耦合进DBIO的Load模块,通过groovy配置分库分表规则,在性能、灵活性和运维复杂性上都有降低。
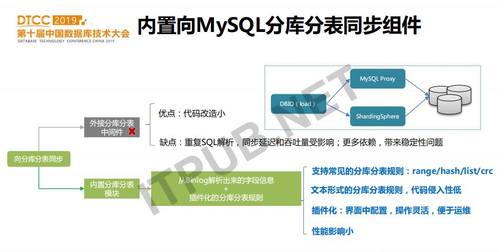
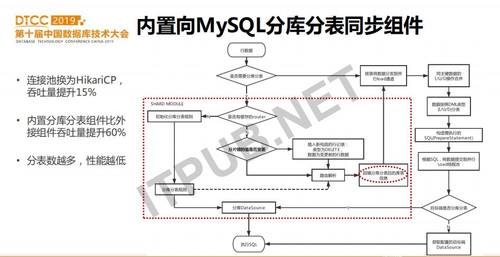
Load模块中内置的分库分表组件的实现:Load模块会初始化分库分表规则,并把路由规则缓存在内存。对于每一条数据,都通过路由规则计算,得到它在目标端的实际数据库名和表名,并把这个信息回填到该行记录中。这里要特别提出的是,如果shardingkey(分片键)上有update操作,Load模块会提前把update分解为2个操作,即delete+insert。修改完记录后,把该行记录发送到并行加载通道。并行加载通道中,首先对同一个主键上的I/U/D操作进行合并,比如U+D合并为D,I+U合并为I等,目的是减小写入目标端的记录数。之后根据DML类型排序,再去构建对应的SQL语句。SQL语句执行的粒度是,每个PrepareStatment会并行执行,执行之前会查询该SQL语句的目标端,获取分库datasource后写入。 在分库分表组件中,我们把原来的DBCP连接池替换为更为高效的HikariCP,吞吐量有了15%的提升。与外接Proxy的方案相比,内置分库分表组件的吞吐量提升60%。另外,我们对不同分库分表数也做了压测,分库分表数越多,性能越低。因此,需要合理设置分表,并不是越多越好。
3.3 MySQL全量数据同步

进行全量的数据在DB间搬迁,需要考虑的最主要问题就是限流,即如何读源端数据避免影响源端正常的读写,如何写目标端系统避免写入QPS过高导致数据积压或复制延迟等。另外需要考虑的就是如何控制数据迁移的整体逻辑,比如如何并发读写,如何进行错误重试等。
将MySQL数据全量导出到其它系统的方案,包含2个模块,即数据提取模块extract task和数据导入模块load task。通过流程控制器来协调两个模块的工作,并对异常信息同步进行重试和记录。在流量控制方面,采用从mysql流式读取的数据,并且通过令牌桶来保证读取数据的QPS在设置的范围内。之后,对读到的数据进行业务自定义的过滤和转换,并写入到一个BlockingQueue中。Load任务从BlockingQUeue读数据,并批量或单条写入目标端。如果目标端负载较高,写入QPS低,则BlockingQueue有数据积压,Extract任务也会阻塞,直至目标端正常。通过读写限流,避免了全量同步对源和目标端的影响。
3.4 DBIO HA方案
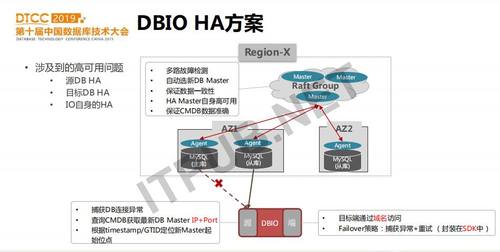
DBIO一般应用于实时在线的数据同步,所以需要保证在各种故障下可以快速检测故障并恢复,保证同步流程的正常运维。那么可能造成同步异常的故障有哪些呢?分别为:源端DB异常、目标端系统异常以及DBIO服务进程异常。
首先,介绍一下数据库系统本身的高可用方案。以MySQL 的一主多从集群中主库故障为例,来看MySQL本身如何实现failover。我们在每台服务器上都会启动一个agent进程,它会监控在这台服务器上的多个mysql实例的状态,并与master集群保持心跳。某个MySQL主库故障时,agent会监控到该信息,Master集群中的leader节点会对这个mysql集群进行多路检测,以确认该mysql主库确实故障,之后会选择出合适的从库来提升为主库。新主库的选择策略是,与原master同机房,且具有最新的binlog和relaylog。一旦某个从库提升为主库,其它从库都需要从新主库apply差异的binlog,之后master会将原故障主库上的域名重新绑定到新MySQL 主库上并更新CMDB的信息,完成MySQL failover过程。为了避免HA Master的单点故障,我们启动了多个HA Master组成raft group来实现HA Master的高可用。
现在看DBIO如何应对源端系统的failover。源端系统failover期间,DBIO肯定会触发连接异常,经过多伦重试仍失败时,则从CMDB查询到最新的主库,并根据之前同步的最新时间点,找到从新主库上同步的起始位置后开始同步。如果开启了gtid,则根据gtid来确定从新主库同步的起始位点。
对于目标端故障,我们也是类似的方案。区别是,源端是通过DB的IP和端口来获取数据,目标端通过域名访问数据库。数据库团队发布的SDK,对数据库failover的异常处理做了封装。所以,目标端的failover在DBIO这端基本不需要做什么。
那么,DBIO本身如果故障,是怎么处理的呢?这个比较简单,也是otter原生就支持的。它通过zookeeper来监控各个worker节点是否在线,如果有worker节点异常,manager会将dead worker上的同步流迁移到备用worker上。从线上数据库和DBIO的failover耗时统计看,基本上故障在不到1分钟内可以自动检测并恢复正常。
3.5 MySQL间双向同步方案
数据库间双向同步需要重点解决的是如何避免数据回环,即从A同步到B的数据,不能再从B同步回A,否则这个数据就会在两个DB间相互不停的写入。

我们的解决方案是,在通过DBIO写入目标MySQL时,对同步的数据打上标记。然后在DBIO的Select读数据时检查这个标记,丢弃回环数据。如上图示例,3个数据库分别负责同一个业务不相交的数据写入,但是通过DBIO来做相互同步,最终每个DB都存储有全量数据。我们看从mysql2到mysql3的DBIO同步。对于3条记录,第一条记录是mysql2写入的,DBIO未发现标记位,则同步到mysql3。第2条数,里面有标记且是mysql3的标记,与目标端相同,则丢弃。第3条数据,有标记但是mysql1的标记,不构成回环,则把数据写入mysql3。应用双向同步有一个前提条件,就是两个双向同步的DB上不能同一时间对同一个key更新,否则会造成冲突。这就要求业务在应用双向同步时首先需要对数据进行单元化切分。
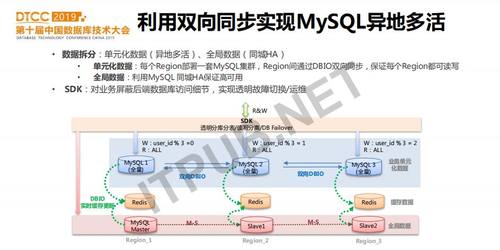
基于双向同步,我们进一步可以实现MySQL的异地多活。类似于前面介绍的双向同步的约束条件,我们可以把业务单元化数据部署到不同的地域(比如两地三中心),通过DBIO双向同步,从而每个DB都有完整的数据。另一方面,有一些全局数据无法拆分,可以仍然采用MySQL主从集群或Group Replication集群部署。如果某个Region故障,则可以把流量切到其它Region。数据库服务团队提供的SDK接入了配置中心,当切换到另外一个Region的集群时,修改配置中心的配置。SDK接收到配置变更通知,会逐步断开老连接,并连接到新配置的集群。所以SDK在我们的应用开发中占有非常重要的作用。
4. DBIO自服务平台
前面介绍了一些功能和方案,那么如何把这个工具变的易用也非常重要。我们开发了一个基于Web的自服务平台,业务可以提交同步流申请、查看同步状态、订阅告警、并可对工作流进行启停或配置修改等操作。如何把这些繁复的运维和告警处理自动化,就依赖后台的工作流引擎。
当接收到一个运维工单或告警时,会把它和事先定义好的一个工作流任务关联。这个工作流任务就是处理这个工单或告警的一系列脚本。工作流引擎生成工作流任务的配置信息,并提交执行任务。处理脚本提前保存在gitlab上,工作流任务执行引擎从gitlab下载脚本,并根据工作流的顺序来执行这些脚本。
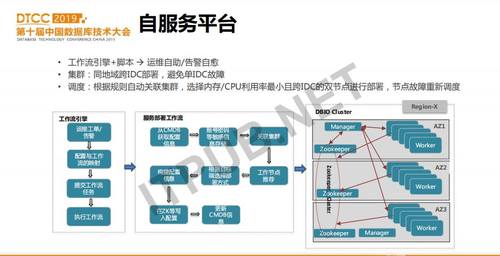
上图示例的是DBIO服务部署工作流,在执行时会读取工单信息和CMDB信息,生成同步任务的配置,并选择同步任务的执行集群和worker节点,配置生成后就可以启动同步任务了。为了保证服务的高可用,DBIO的集群是跨IDC部署的,这样单个IDC故障,不影响可用性。在进行同步流任务调度时,根据worker节点的资源利用率以及与原和目标端系统的延时来选择合适的worker。
5. DBIO在爱奇艺的应用
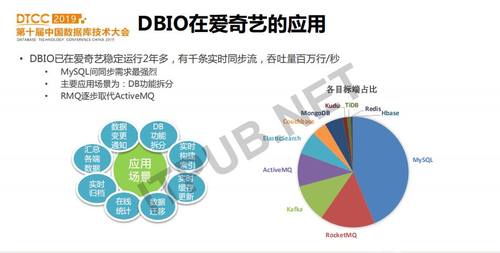
DBIO已经在爱奇艺稳定运行2年多,有千条实时同步流,百万行/秒的吞吐量,延时在500ms左右。各种目标端对比看,MySQL间的同步需求最多,主要用于DB功能拆分。另外MQ方面,之前主要是AMQ,但由于它扩展性及容错性差,逐步被RocketMQ所替代。
DBIO常见应用场景
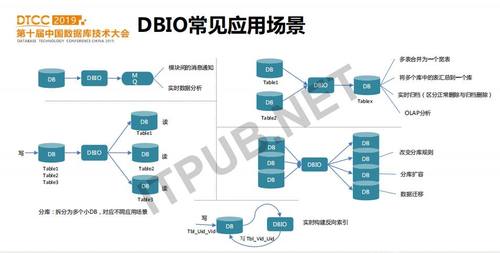
首先是用于模块间的消息通知。在用DBIO之前,业务需要写DB成功后再发送MQ,通知其它模块。现在业务只需要直接写MySQL,消息通知交由DBIO,同时MQ的消费端也可用于实时数据分析。
第二种场景是DB功能拆分。对于一个业务的基础库,由于需要支持多表事务,所以只能在一个MySQL中存储所有数据。但是,这个业务的多个子系统可能只需要部分数据。如果这些子系统直接读基础库,一方面可能会造成影响,另外一个方面也不方便自己扩展进行个性化的表定义。这种场景下,可以使用DBIO来做功能拆分,即每个子系统只同步需要的数据。这样业务开发会更加灵活。
另外一个场景就是多库映射到一个库上,比如多表合并成一个宽表、将多个库中的表汇总到一个库以及实时归档等。
当然,还有M到N的同步映射,一般应用于分库分表改变了映射规则、分库扩容或数据迁移等场景。
还有一种应用场景是在分表上实时构建反向索引。比如业务希望基于用户查询对应的红包信息,也需要根据红包查询用户信息。此时业务可以只写用户表(基于用户id分表),DBIO读取用户表变更信息,并把数据重新写入到红包表(基于红包id分表)中。
6. 展望
虽然DBIO已经比较稳定,但一些问题还没有完全或优雅地解决。比如源端DDL操作如何优雅的同步到目标端,如何高效地校验同步数据的一致性等。同时,我们也正在把业务常见的使用方案进行封装,变成通用易用的平台能力,更好地为各业务线服务。
我的分享就到这里,谢谢大家!