
摘要:广告平台是一个数据驱动的平台,数据在系统中高效流动,形成闭环,产生价值。腾讯广告系统每天有上百亿次请求量,以及上百T的数据,保证数据流的稳定可靠和高性能是数据系统的核心问题。对于数据分析场景,腾讯基于 spark 和 hbase 构建了一套实时离线统一的统计系统,同时也自研了一套基于SSD的多维数据透视分析系统,对万亿行数据做实时查询仅需秒级;对于机器学习,特征工程重点是保障特征数据的正确性,保证训练和预估使用的特征数据一致性,并且提升特征生产和调研的效率。此外,腾讯积累了大量的数据,同时非常注重用户隐私,不会把底层数据任意打通任意使用,为了保护用户数据安全,在 hadoop 的鉴权机制之上构建了更加安全和严格的鉴权系统,并通过差分隐私,数据脱敏和水印等方式保护各场景下的数据安全,同时也基于密码学多方安全计算提供了部分场景下更加安全的数据应用方案。腾讯基于 hadoop 构建了高性能高可靠性的营销数据平台,在保证数据安全前提下,提供在线分析处理和特征建模能力,支持腾讯的广告营销和智慧零售等业务高速发展。

作者:李锐
编辑:胡孟依
李锐:腾讯广告数据系统负责人,2011年加入腾讯,专注大数据存储和计算系统,有9年分布式系统开发和应用经验,带领腾讯广告的数据工程团队,打造基于hadoop 生态的营销数据平台,支持腾讯的广告营销和智慧零售业务。
腾讯广告系统架构
腾讯有全国之中最大的用户的覆盖量,有非常丰富的营销场景,借助腾讯数据即有的优势可进行广告业务的投放,实现流量变现。整个广告系统可以分成投放、播放、数据。广告主通过投放系统来投放广告,当流量接进来之后,系统选择在几十万,上百万的板块里面选择合适的广告去呈现和播放,广告是一个非常严重依赖于数据的一个行业,数据可以在整个系统里面,不断地扭转,然后产生越来越大的价值。比如说广告主他需要看到在广告播放后产生是我各种效果数据,去衡量广告的价值来决定这个广告是加大投放、还是说是需要停下来修改一些东西。内部运营人员也需要根据数据进行各种投放和运营的决策,包括怎么去打动更多的广告主。线上广告系统需要实时地、准确地回馈这些数据,去决定怎么去做广告主的频繁播放以及怎么把更好的播放量给到更合适的广告。
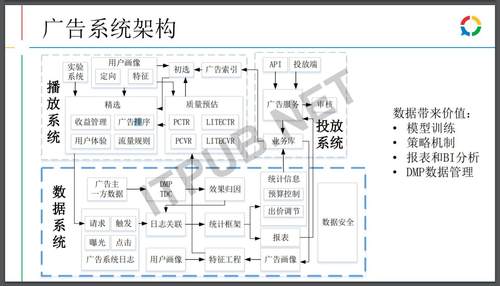
腾讯自己构建的广告数据管理平台,用来补足腾讯里面除社交数据之外的商业数据,把广告数据的变化、后续用户的行为归到广告曝光和点击上,形成数据的闭环,提升整个广告系统的转化率。对于广告系统来说,机器学习和模型训练也是一个非常重要的环节,广告中会经过各种各样的模型的训练提高点击率转化率,进行自动录像、人群的推荐、商品的推荐等等。
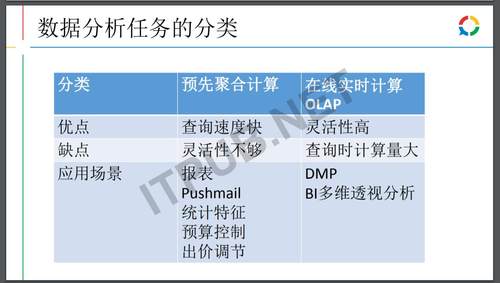
数据分析
数据分析的任务有两种类型,一种先把数据聚合好直接查询,但这种查询需要预先指定分析数据的维度和量级等等,一旦有新的需求的需要进行重新的开发、验证、上线、部署。如果查询历史数据需要重跑各种历史数据。适用于各种报表或线上统计数据。而另外一种方式是实时查询计算,这种方式计算量会非常的大,但灵活性很高,可以任意地执行OLAP场景的分析,这种方式需要预先把数据准备好,指定合适查询的格式做相应的分析,适用于DMP和BI场景。
下面要讲的是预先聚合查询平台,当广告业务刚开始时候,直接用Hadoop通过Hive/pig的脚本从原始数据中统计结果,但随着业务各种广告场景的不断的增加,需要分析的报表数据越来越多,机器资源很快就不够用了。那么很自然的解决办法就是从原始数据中抽取一些中间表,将中间的数据经过一些压缩、字段筛选,使它的计算量变小。这样能够暂时解决掉一部分问题。但是随着业务的慢慢扩大,经常要加不同的维度的字段,中间表越加越大,慢慢就跟原始的数据是一个量级了,只能对中间表进行拆分,但很快会产生20到30个空间数据,这些空间数据的计算量也是相当难以承受的。为解决这个问题建造统一计算平台,通过Storm进行实时的计算,mapreduce做离线计算,通过配置的方式指定输出数据和结果,最后上传到HBASE上供其他方进行查询。这个方式基本上解决了的业务不断增长、机器资源不够和本地开发的成本越来越大的问题。
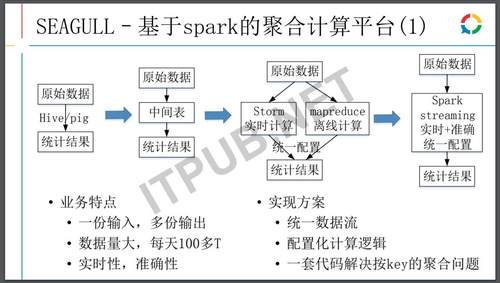
其实这个方式是不够好的,每有一个相应分析,都会实时、离线两套代码两套部署,能不能把它打成一套呢?其实是可以的,Storm肯定不行,Storm是纯内存计算,数据容易丢失。mapreduce能不能搞得更快呢?mapreduce有两个缺点,一个是它的计算成本开销,它会有很多进程启动和结束的成本,另外一种是它的调度,它是通过异构的平台来进行调度,如果提升它的计算,调度成本开销也会随之成长。基于以上问题,后来就改到了Spark streaming做调度计算。

聚合计算平台先将切分好的数据放到HDFS上,通过在Spark上调度很小聚合任务的方式去做相应的调度。通过这种方式,首先的话输入和输出都是HDFS,启动后只用看输出不存在输入存在,则做一下相应的逻辑。这样避免了Spark checkpoint带来的各种问题。相当于在Spark里面去执行一些比较小mapreduce的项目,如何避免刚才说的那个问题,首先spark worker是常驻的进程,不会有JDM的启动和停止的开销,分层调度只用把spark提起来,然后spark在driver里面启动,所以调度能够非常快。使用spark会带来一个麻烦,它是常驻进程,内存泄露就是一个很严重的问题,搞定这个问题后可以有内存来做很多的cache,从而加快计算速度。由此形成了一个统一的基于Spark streaming聚合计算平台,把最终数据输出到HBase,通过SQL的查询的接口获取相应的数据。
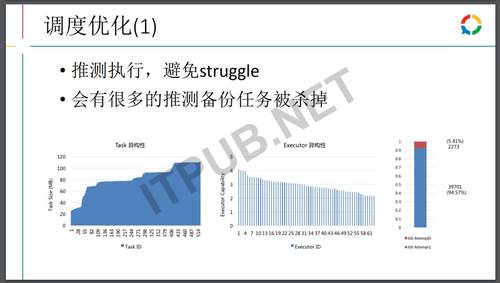
我们在Spark也做了一些优化,首先是Spark的话,Spark使用一定会去开推测执行,因为单机的讨论会导致整体的一个延迟。
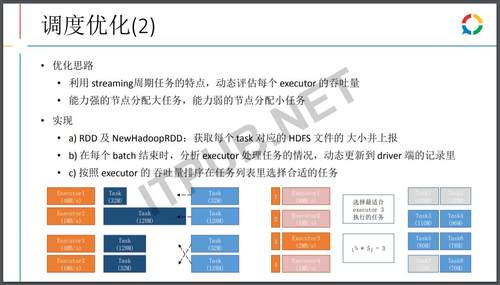
使用推测执行,一个会浪费计算,其实会有很多的推测备份任务被杀掉,所以把计算能力、任务大小都部署了监控,优先计算能力强的节点算大的任务,这样一个小的优化可以减少大概80%左右的浪费任务。
下面讲在线实时的计算,这个要解决的场景就是OLAP的分析,比如将原始的广告日志数据放在那儿,大家可能想到什么查什么,但没有统计好相应的报表,现在就要去分析上面的东西,需要在什么量级能够达到我的结果、能够去做这种运营的决策。

广告流量每天是几百亿的量级,需要把数据先做相应的数据的筛选、分组、聚合得出最后的结果,这个是在一个自研的计算引擎上面去做的,当时做这个事情的时候,没有任何一个开源的引擎,能够抗住这个数据量和性能要求。

计划引擎分为两种数据结构,一种是二维表的独立的数据结构,这种数据结构的特点是正排能够用列存储的方式来存,可以对数据去建相应的倒排数据,然后另外是嵌套结构,像Jason和proto buffer,用的比较多的是proto buffer,在广告的线上业务打印出来的日志为了做比较好的兼容,原始的数据都是proto buffer格式,需要保证原始的数据供大家去排查、分析各种问题,所以需要把这种嵌套的结构以一个比较高效的方式存储下来,使得上面的OLAP分析比较迅速。

索引设计对倒排和正排分别做了相应的优化,倒排的话,大家知道一个数据的储存,稀疏数据用array是比较高效的,而稠密的数据用bitmap是比较高效的,综合两者特点用一种叫roaring bitmap的方式来去实现,在实现的过程中做了比较多的在底层编码级别的优化和改进,使得在roaring bitmap中交、并、差、积的计算能够做得非常高效。

正排的话,首先是列存储,把相似的数据放到一起采用非常高效的编码,去优化储存的量级。针对业务的数据,构建了十多种编码方案,通过自适应去采用相应的编码方案。

下图一个例子,最开始的时候嵌套结构存下来东西使用Pivot来存储,但Pivot存下来的数据居然比使用行存储还要更大,这个是不符合认知的。
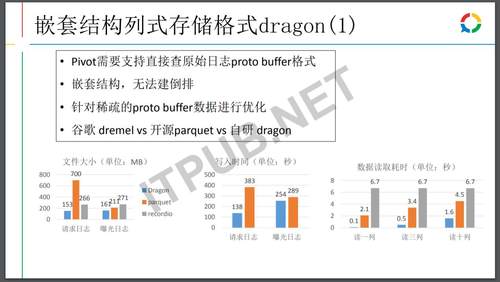
为什么呢?因为业务数据是比较稀疏的,有很多的空节点,这就浪费了比较多的存储。这个无法破解,因为没法和数据进行兼容,所以就直接研发了一个模式,像之前的编码优化等等,最后达到的效果是,对比之前的模式减少百分之四五十左右的存储,生成速度是Pivot的1/3左右,读的速度比行存储提高了几十倍。

上图是优化的一些具体项目。
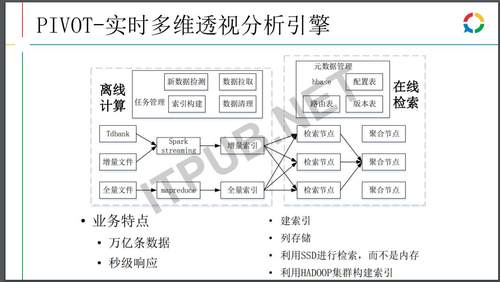
上图是整个OLAP计算引擎,引擎典型的应用场景是需要去分析大量的数据,这么大的数据肯定是不能放在内存中的,那就只能放在SSD上面,另外建倒排和正排的数据所产生的计算量其实非常惊人的,而在计算的时候其实不用去使用SSD这么昂贵的机器,将这些数据包括编码的计算都放在Hadoop集群上进行,所以形成了基于Hadoo集群离线计算和基于SSD在线检索混合部署的OLAP集群查询分析引擎。

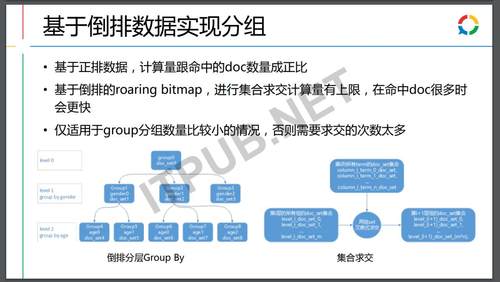
上图是对group by做的具体优化
特征工程
广告业务是有非常多的模型训练的,因为广告直接有现金收益的,所以大家研究这个技术的动力应该会更强。初选模型比如说相似人群扩展,自动定向,动态创意,商品推荐,最原始是广告主指定围绕一下什么样的人,但现在可以根据数据先做冷启动,自动做相应的定向、动态生成广告的创意、与其他公司广告主的商品部相结合、自动推荐商品等等。
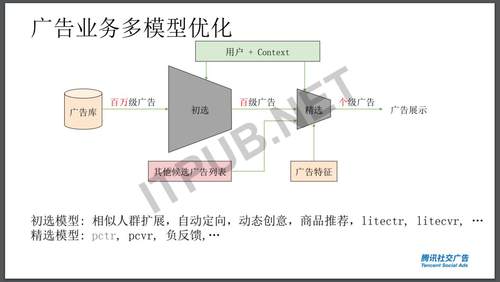
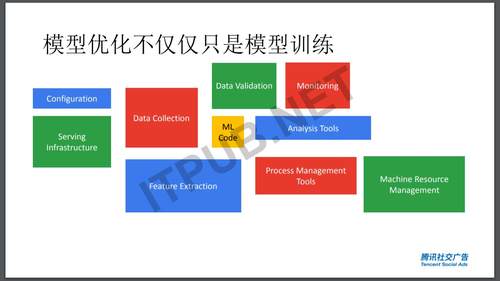
机器学习模型能力其实不仅仅只是机器学习,那就比如这里一个图是来自Tensorflow扩展图,谷歌开源了Tensorflow之后,在不断的开源它的周边产品,中间是机器学习,周边是做数据验证、数据清晰、特征抽取、数据分析等各种相关应用,这些都是在整个特征过程中里所需要进行处理的。
首先建立模型,比如说做一个商品推荐模型,首先需要用户的册子提取原始数据,包括广告数据、用户行为数据构造的样本,之后进行数据拼接,最后调用相关的数据进行模型的训练,之后再离线做TDC,完成一并将特征推到线上,整个过程中数据维护是很大的开销。另外一点是当不同模型有不同数据流之后,多个模型之间所产生的特征不同,而导入特征测试新的模型会很麻烦,所有的流程需要重新走一遍,最后测试的结果也不一定好,这就需要解决到底是实践过程有bug,还是说这个东西对模型没有用。

另外一点是从系统角度出发,维护和处理数据,会有很多重复的计算和处理,这些数据量都很大。这就需要提供相应的共享,去优化相应的数据来选择计算模型。
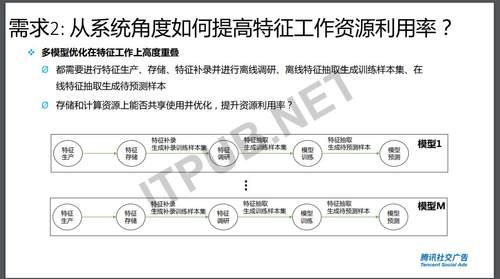
另外是机器学习的预测和训练可能会存在偏差。预测是用之前发生过的生成相应的样本,然后训练出模型,离线用的数据和在线用的数据,有可能是不一致的,还有可能是数据的处理逻辑、代码不一致,甚至是今天的数据和昨天的数据不一致,这都有可能会发生偏差。这就需要一个统一的平台,来保证数据源一致、数据的代码逻辑一致,尽量避免训练和预测有偏差。保证做模型的同学只用集合在它的模型上面,而不需要去关注工程怎么去开发,怎么去保证数据拼接没有bug。

特征平台主要有两个东西,一个是特征仓库,对于做特征的同学来说,做好了特征之后,把它注册到特征仓库,通过特征计算平台配置化的方式,把特征数据拼接到不同的样品上,做离线处理后推到线上通过实验后,完成一个模型的迭代。
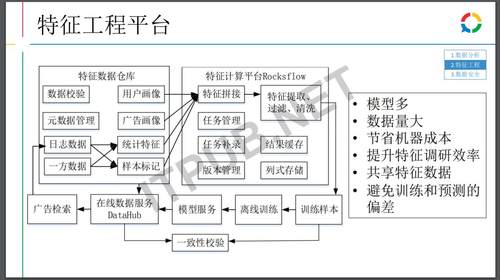
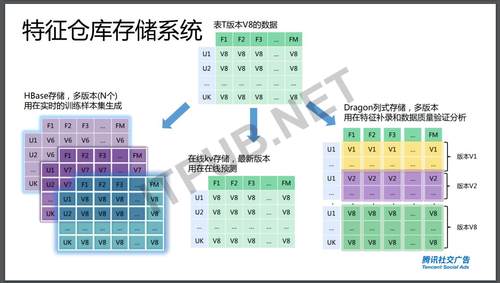
下面讲特征具体包括的东西,比如前文特征,前文特征指的是用户过去的一些行为,而且是实时需要产生到线上的进行相应的处理,腾讯现阶段是分钟量级的更新,如果来了一条数据就去计算,腾讯有10亿量级的用户,每个用户跑一个全量的计算,这个是非常不现实的,实际做法是利用HBASE的Qualifier family特性将数据分开来,当用户有数据有变更的时候,把它存在单独的Qualifier family做区隔,来触发规定时间内的数据扫描和相应抽取解析,通过这种方式在一个比较可接受的机器量级上,完成前文特征的统计框架。

另外一个是商业化数据的特征,广告数据包括广告主的行为,不管是在页面上操作,还是API上所触发的行为,它都是存在MySQL分库分表的机器上,以binlog流水的方式将数据同步到HBASE上,通过类似transaction方式的处理使得数据和流水是完全一致的,为什么要有流水呢?其实很多广告特征的计算框架是基于流水来驱动,比如一个广告更新了,有可能需要去抓取住有广告标题、描述、落地页、图片素材等数据,抽取相应的特征进行更新处理。

另外一个是特征仓库的储存,刚才介绍了离线处理是需要特征共享的,所以基于HDFS做了离线的特征仓库,可以储存比较久的历史数据,通过嵌套结构压缩的方式使数据变小,之前查看这个特征在过去三个月的样本训练结果需要的时间是好几天,但现在在几个小时内就可以做到。
数据安全
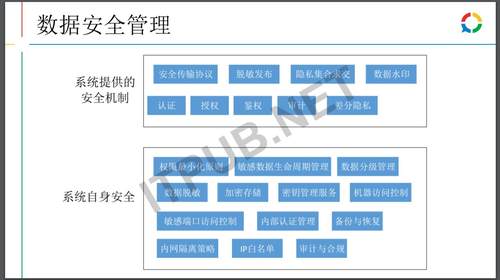
下面说的是数据安全,普通数据安全一般来说,都是鉴权、授权、认证审计等,这里其实想要介绍的是在双方数据保密的情况下如何进行数据合作。
举个例子如何衡量广告的效果,广告主方有广告带来的购买行为数据,而我们有广告的点击或曝光等数据,想要衡量效果的话很简单,要么我们把数据给广告主去做对应归因匹配,要么广告主把数据给我们去做对应归因匹配。如果这两条路子都走不通,有一种方式叫隐私集合求交,用两个加密的可交换函数,将双方的数据经过多次的加密处理后,去计算它们的交值,出来的结果就可以衡量广告效果。
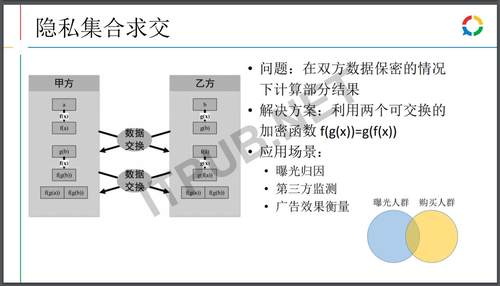
根据双方的协作的模式和场景,这个数据可以应用于广告的曝光归因,以及广告的项目分析,因为你投广告的人有可能本来就想购买你的产品的,这个行为相当于广告是没用的,所以衡量广告效果是需要AB test的,证明投了广告和不投广告产生的效果是不一样的。然后是第三方监测,我们会对数据做保密,第三方公司也需要相应的数据去做监测,通过这种方式是可以实现大家互相不用知道数据,但又能达到数据监测的实现。

在刚才举的这个例子中,如果一方只有一种类型数据,其实就相当于直接拿到另外一方具体数据了。同样腾讯的DMP没有给别人开放,对方用设备号对数据进行查询,没有开放这种接口,只开放了比如说你拿一个号码包来查询,平台对这个汉堡包进行相应的分析,分析后制定投放,其实也可以拿一个号码包再加一个人这样的方式做相应的攻击,这样就需要去用到差分隐私对数据做一些扰动。也会在内部进行计算此次攻击查了些什么样的数据,然后对访问的数据集进行相应的限制,控制差分预算,超过指定的差分预算,当天内则不能进行相应的查询。
今天我主要分享的就是基于腾讯广告的数据系统方面,主要介绍了在数据分析、特征工程以及数据安全方面所做的一些工作,谢谢大家。