
图形数据库是许多现代用例的一个很好的解决方案:欺诈检测、知识图表、资产管理、推荐引擎、物联网、权限管理…你命名它。
所有这些项目都受益于能够快速分析高度连接的数据点及其关系的数据库技术 – Graph 数据库专为这些任务而设计。
但是,在 #buzzword 警报* 可扩展性方面,图形数据的性质带来了挑战。那么,为什么这是,图形数据库能够扩展?我看看。。。
下面,我们将定义扩展是指扩展,仔细研究可能阻碍图形数据库扩展的两个挑战,并讨论当前可用的解决方案。
什么是”图形数据库的可伸缩性”?
让我们快速定义扩展在这里的意思,因为它不是”只是”将更多的数据放在一台计算机上或将其扔到各种计算机上。使用大型数据集或不断增长的数据集时,您想要的也是查询的可接受性能。
因此,这里真正的问题是:当数据集在一台计算机上增长甚至超过其功能时,图形数据库能否提供可接受的性能?
您可能会问,为什么这是一个问题摆在首位。如果是这样,请阅读下面的图表数据库的快速回顾。如果您已经意识到超音和网络跃点等问题,请跳过快速回顾。
快速回顾图形数据库
简而言之,图形数据库存储无架构对象(顶点或节点),其中可以存储任意数据(属性)和对象(边缘)之间的关系。边通常具有指向一个对象到另一个对象的方向。顶点和边形成一个称为”图形”的数据点网络。
在离散数学中,图形定义为一组顶点和边。在计算中,它被认为是一种抽象数据类型,它善于表示连接或关系——与关系数据库系统的表格数据结构不同,这种关系数据库系统的表型数据结构在表示关系方面具有非常有限的讽刺意味。
如上所述,图形由节点(又名顶点 (V) 组成,这些节点由关系(即边 (E) 连接)。

顶点可以具有任意数量的边和任意深度的窗体路径(路径的长度)jpg”数据-新””假”数据大小=”95341″数据大小格式化=”95.3 kB”数据类型=”临时”数据网址=”/存储/temp/13761781-图数据库搜索深度 s.jpg”src=”http://www.cheeli.com.cn/wp-content/上传/2020/07/13761781-图中搜索深度数据库.jpg”样式=”宽度:541px;”/>
从一个银行帐户到另一个银行帐户的金融交易用例也可以建模为图形,并且看起来像下面的架构。在这里,您可以将银行帐户定义为节点,将银行交易记录与其他关系定义为边缘。
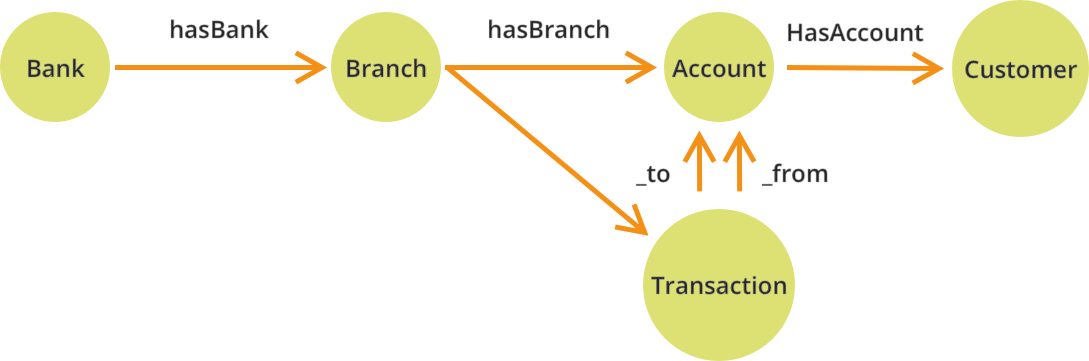
用这种方式存储帐户和事务将使我们能够遍历创建的图形是未知的或变化的深度。在关系数据库中编写和运行此类查询往往是一项复杂的工作。(旁注:使用多模型数据库,我们还可以将银行与其分支机构之间的关系建模为使用联接查询的简单关系)。如果您想了解有关图形数据库的信息,请查看此免费课程。
图形数据库提供各种算法来查询存储的数据和分析关系。算法可能包括遍历、模式匹配、最短路径或分布式图形处理,如社区检测、连接组件或中心。
大多数算法有一个共同点,这也是超node和网络跳的问题的性质。算法通过边缘从一个节点遍历到另一个节点。
在此快速回顾之后,让我们深入探讨挑战。首先:名人。
总是这些名人
如上所述,顶点或节点可以具有任意数量的边。一个超级问题的经典例子是社交网络中的名人。超节点是图形数据集中具有异常高的传入或传出边数的节点。
例如,帕特里克·斯图尔特爵士的Twitter账户目前拥有340多万粉丝。

如果我们现在将帐户和推文建模为图形并遍历数据集,则我们可能必须遍历 Patrick Stewart 的帐户,并且遍历算法必须分析指向 Steward 先生帐户的所有 340 万条边。这将增加查询执行时间,甚至可能超过可接受的限制。类似的问题可以在例如欺诈检测(具有许多事务的帐户)、网络管理(大型 IP 集线器)和其他案例中发现。
超级节点是图形的固有问题,给所有图形数据库带来挑战。但有两种选择,以尽量减少超音阴影的影响。
选项 1:拆分超级提示
更确切地说,我们可以复制节点”Patrick Stewart”,并按某个属性(如关注者来自的国家/地区或某种其他类型的分组)拆分大量边缘。因此,我们将超node对遍历性能的影响降至最低,以防我们可以在我们想要执行的查询中使用这些分组。
选项 2:以顶点为中心的索引
以顶点为中心的索引将边缘信息与有关节点的信息一起存储。
要停留在帕特里克 · 斯图尔特的 Twitter 帐户的例子, 根据用例, 我们可以使用
- 有关某人何时开始关注的日期/时间信息
- 跟随者来自的国家
- 关注者的追随者计数
- 等。
所有这些属性可能提供有效使用顶点为中心的索引所需的选择性。
然后,查询引擎可以使用索引来减少执行遍历所需的线性查找数。也可以采用同样的方法,例如欺诈检测。在这里,金融交易是边缘,我们可以使用交易日期或金额实现高选择性。
在某些情况下,使用上述选项不合适,在遍历超音时,必须忍受某种程度的性能下降。然而,在大多数情况下,有优化性能的选项。但还有另外一个挑战,大多数图形数据库尚未解决。
网络跳问题:如果你撕裂他们分开,你必须支付。还是你?
首先快速回顾一下。我们有一个高度连接的数据集,需要遍历它。 在单个实例上,查询所需的所有数据都驻留在加载到主内存中的同一台计算机上github.com/jboner/2841832″rel=”不跟随”=大约需要100ns。
现在让我们假设我们的数据集超过单个实例的功能,或者我们想要群集的高可用性或额外的处理能力…或者,一如既往,一切。
在图形案例中,分片意味着拆散以前连接过线的东西,我们的图形遍历所需的数据现在可能驻留在不同的计算机上。这会在我们的查询中引入网络延迟。我知道网络可能不是开发人员的问题,但查询性能是。
即使在位于同一机架的现代 Gbit 网络和服务器上,通过网络查找的成本比内存中查找要贵 5000 倍左右。在连接群集服务器的网络上添加一点负载,甚至可能获得不可预知的性能。
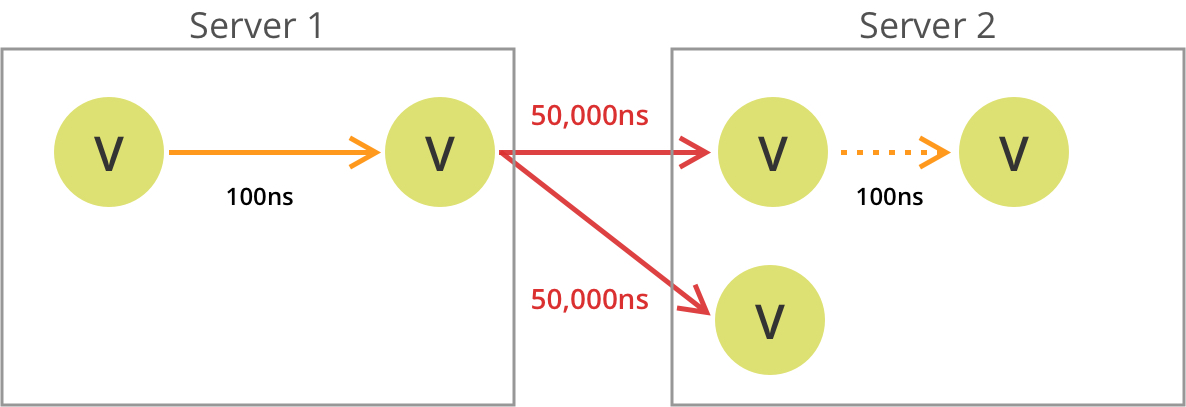
在这种情况下,遍历可能从数据库服务器 1 开始,然后点击一个节点,该节点具有指向存储在 DB Server 2 上的顶点的边缘,从而通过网络进行查找 – 网络跃点。
如果我们知道考虑更多实际用例,那么在单个遍历查询中,我们可能有多个跃点。
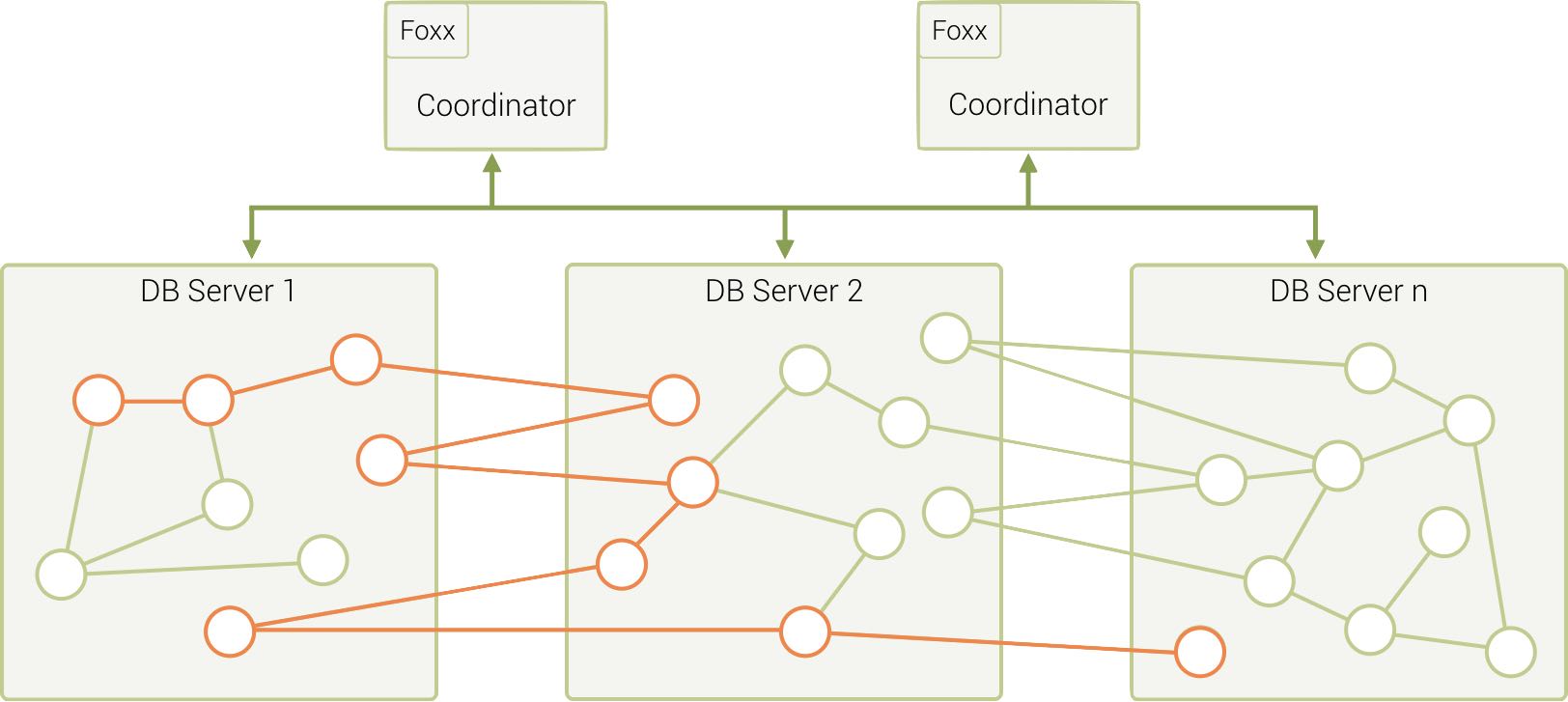
在欺诈检测、IT 网络管理,甚至现代企业标识和访问管理用例中,可能需要分发图形数据,同时仍需要以低于秒的性能执行查询。查询执行期间的多个网络跃点可能会危及此需求,从而付出高昂的扩展代价。
更智能的方法解决问题
在大多数情况下,您已经对数据有一些了解,我们可以用它来以智能方式分片图形(客户 ID、区域等)在其他情况下,我们可以使用分布式图形分析,通过使用社区检测算法(例如ArangoDB的 Pregel 套件)为我们生成此域知识,从而计算此域知识。
现在,我们可以做一个快速的思想实验。假设我们有一个欺诈检测用例,需要分析财务交易以确定欺诈模式。我们从过去知道,欺诈者利用某些国家或地区的银行来清洗他们的钱(你可以给真正的欺诈检测查询在Oasis尝试,只需按照注册后入职指南)。
我们可以使用此域知识作为图形数据集的分片密钥,并在 DB 服务器 1 上分配在此区域执行的所有财务事务,并在其他服务器上分发其他事务。
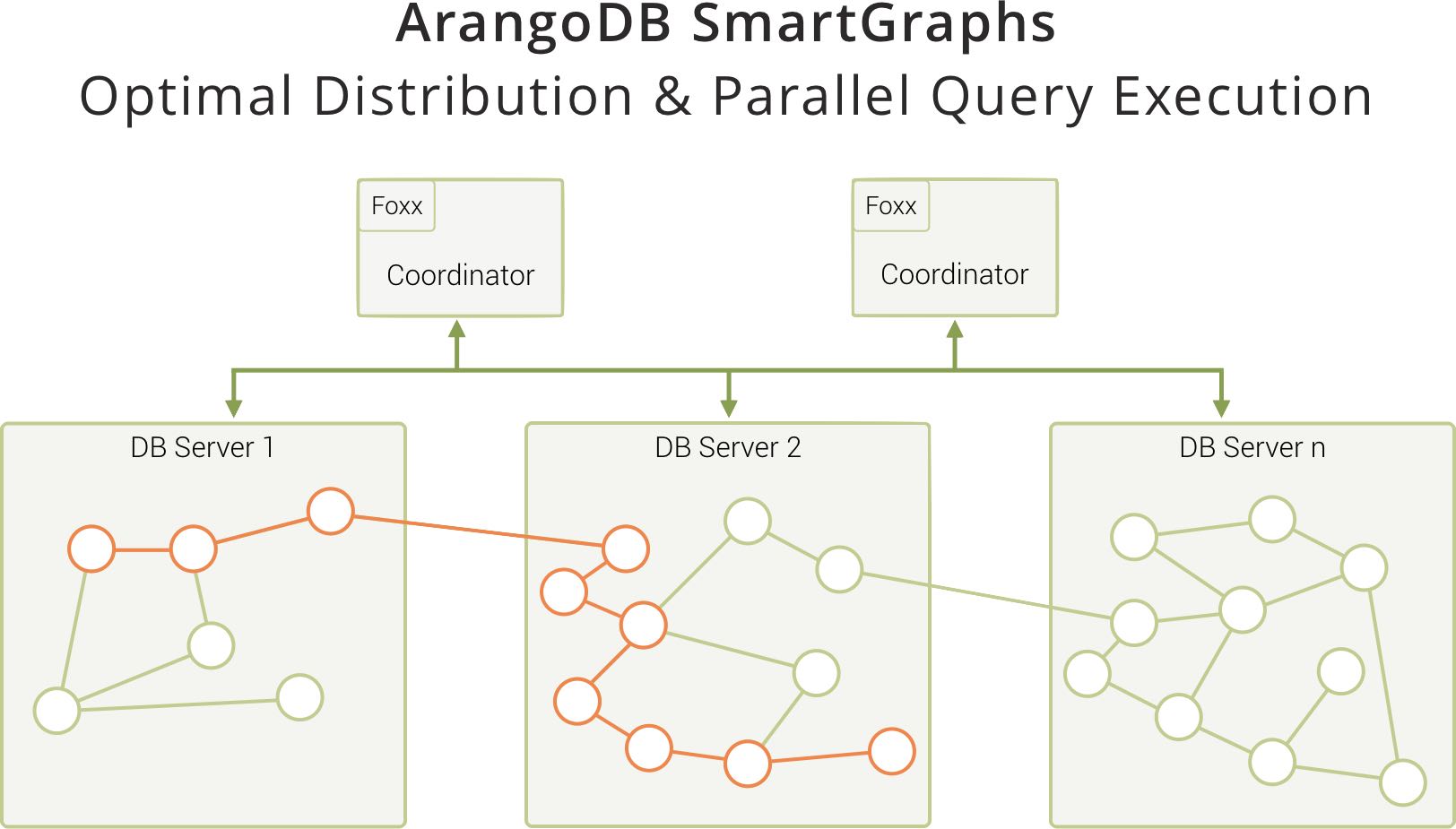
现在,您可以利用ArangoDB 的 SmartGraph 功能在本地执行反洗钱或其他图形查询,从而避免或至少大大降低查询执行期间所需的网络跃点。”不错, 但如何?
ArangoDB 中的查询引擎知道图形遍历期间所需的数据存储位置,将查询发送到每个数据库服务器的查询引擎,并在本地并行处理请求。然后,每个数据库服务器上的结果的不同部分将被合并到协调器上并发送到客户端。使用这种方法,SmartGraphs 允许在单个实例附近提供性能特性。
如果您有一个相当分层的图形,您还可以利用不相交的智能图来更好地优化查询。
我也很想提出其他解决方案的网络跳问题, 但据我所知, 没有其他。如果您知道其他解决方案,请随时让我知道在下面的评论!
结论
不断增长的数据需求需要找到答案,需要扩展解决方案
我认为,我们现在可以放心地说,图形数据库有垂直扩展的选项,但是,在ArangoDB的情况下,也是水平的。当然,有些边缘情况下,以顶点为中心的索引或智能图不能提供帮助,但这些往往相当罕见。