
DLP,或数据丢失防护,是一种主动方法和技术集,旨在保护敏感信息免遭组织内未经授权的访问、共享或盗窃。其主要目标是通过监视、检测和控制跨网络、端点和存储系统的数据流来防止数据泄露和泄漏。
DLP 解决方案采用多种技术来实现其目标:
内容检查
DLP 系统检查动态、静止或使用中的数据,以识别敏感信息,例如个人身份信息 (PII)、知识产权、财务数据或机密文件。他们根据预定义的策略和规则分析内容,其中可以包括关键字、正则表达式、数据指纹和数据分类标签。
政策执行
组织可以定义和执行规定如何处理和保护敏感数据的策略。这些策略指定检测到敏感数据时要采取的操作,例如加密、隔离、阻止传输、警告安全人员或应用数字版权管理 (DRM )控制。
情境意识
DLP 系统会考虑数据使用的上下文,包括用户身份、设备类型、位置、访问时间和预期接收者。通过考虑情境因素,DLP 解决方案可以应用适当的安全措施并更有效地降低风险。
发现和分类
DLP 工具可帮助组织识别和分类 IT 基础设施中的敏感数据。它们帮助发现存储在各种存储库中的数据,包括数据库、文件共享、云存储和端点。分类使组织能够确定保护工作的优先顺序并更有效地分配资源。
监控和报告
DLP 解决方案持续监控数据交易并生成有关数据使用、策略违规、安全事件和合规状态的综合报告。这些报告提供了有关安全状况的宝贵见解,帮助组织评估风险并促进法规遵从性审核。
与安全生态系统集成
DLP 解决方案通常与其他安全技术集成,例如防火墙、入侵检测系统 ( IDS)、身份和访问管理 (IAM) 平台、安全信息和事件管理 (SIEM)系统。集成可增强整体安全状况并实现对安全事件的协调响应。
人工智能方法
本文的这一特定部分讨论了使用 AI 进行内容检查。与传统的 DLP 方法相比,人工智能具有多种优势。
准确度和精度
与手动或基于规则的方法相比,人工智能驱动的内容检查算法可以以更高的准确性和精度分析大量数据。人工智能可以根据上下文、语义和模式识别敏感信息,从而更有效地检测数据泄露和策略违规。
可扩展性
人工智能驱动的内容检查解决方案可以扩展,以处理企业系统中不断增长的数据量和复杂性。传统方法可能难以应对现代数据环境的规模,导致内容检查流程不完整或效率低下。
自动化
人工智能使内容检查过程自动化,减少了人工干预和人为错误的需要。人工智能算法可以持续实时扫描和分析数据传输,使组织能够更有效地执行数据保护策略,而不影响生产力。
适应性
人工智能驱动的内容检查解决方案可以随着时间的推移进行调整和发展,以应对新的威胁、监管要求和业务需求。与基于规则的静态系统不同,人工智能算法可以从过去的事件中学习并更新其检测能力以检测新出现的模式和异常情况。
复杂性处理
人工智能可以比传统方法更有效地处理现代数据格式、结构和语言的复杂性。 人工智能算法可以解析和理解非结构化数据,例如文本、图像和多媒体内容,实现跨不同数据源的全面内容检查。
减少误报
人工智能算法可以通过将数据检查结果置于上下文中并关联多个数据属性来减少误报。通过考虑用户行为、访问模式和数据敏感性等因素,人工智能可以确定警报的优先级并专注于高风险事件,从而最大限度地减轻安全团队的负担。
持续学习
人工智能驱动的内容检查解决方案可以随着时间的推移不断学习并提高其检测能力。通过分析安全分析师的反馈并整合新的威胁情报数据,人工智能算法可以提高检测数据泄露和策略违规的准确性和有效性。
代码块
下面是一个使用 AI 的 DLP 的简单 Python 脚本。此 Python 脚本的亮点:
- 此示例中提供的脚本未明确涉及训练数据或训练阶段,因为它使用预先训练的语言模型(在本例中为 en_core_web_smspaCy提供的strong>模型,用于根据模式执行内容检查。
- 此脚本使用 spaCy 的 Matcher 类定义一个模式来匹配信用卡号码。该模式被指定为表示文本中标记形状的字典列表。然后使用 Matcher 类在处理后的文本中查找此模式的匹配项。
- 此外,此脚本使用正则表达式模式在输入文本中查找信用卡号。使用此正则表达式模式 (\b\d{4}[-\s]?\d{4}[-\s]?\d{4}[-\s]?\d{4}\b)搜索类似于信用卡号的数字序列。
- 此脚本使用预先训练的语言模型处理输入文本,并搜索与指定模式的匹配项(均使用 spaCy Matcher 和正则表达式)。找到匹配项后,它会打印出识别出的敏感信息,例如信用卡号。
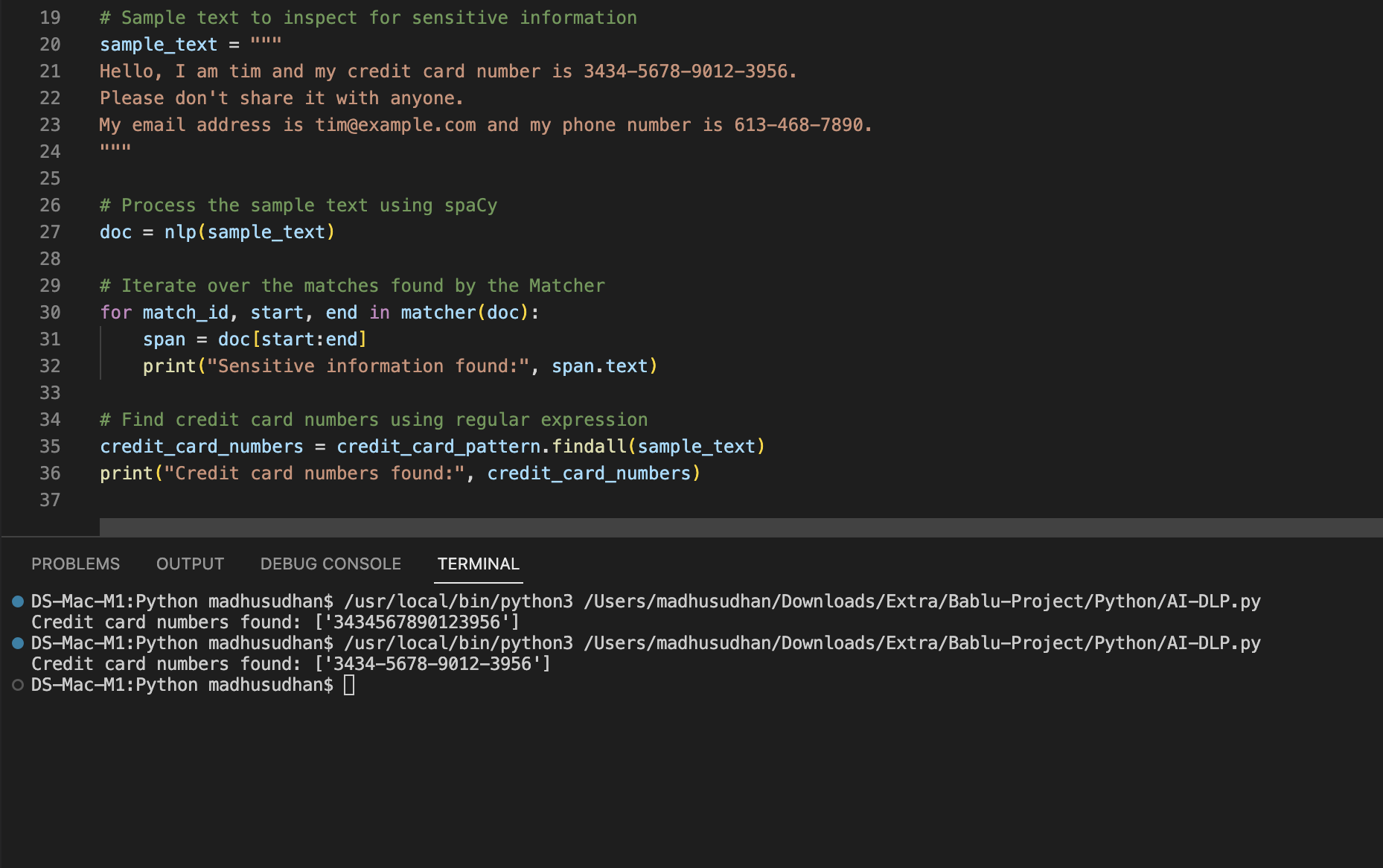
导入 spacy
从 spacy.matcher 导入匹配器
进口再
# 加载英语语言模型
nlp = spacy.load("en_core_web_sm")
# 定义信用卡号的正则表达式模式
Credit_card_pattern = re.compile(r'\b\d{4}[-\s]?\d{4}[-\s]?\d{4}[-\s]?\d{4}\b ')
# 加载 spaCy 的匹配器
匹配器 = 匹配器(nlp.vocab)
模式 = [{"SHAPE": "dddd"}, {"SHAPE": "dddd"}, {"SHAPE": "dddd"}, {"SHAPE": "dddd"}]
# 定义一个模式来匹配信用卡号
matcher.add("CREDIT_CARD", [pattern])
# 用于检查敏感信息的示例文本
样本文本 = """
您好,我是蒂姆,我的信用卡号码是 3434567890123956。
请不要与任何人分享。
我的电子邮件地址是 tim@example.com,电话号码是 613-468-7890。
”“”
# 使用 spaCy 处理示例文本
doc = nlp(样本文本)
# 迭代匹配器找到的匹配项
对于 match_id、开始、结束于匹配器(doc):
跨度 = doc[开始:结束]
print("发现敏感信息:", span.text)
# 使用正则表达式查找信用卡号
Credit_card_numbers = Credit_card_pattern.findall(sample_text)
print("找到信用卡号码:",credit_card_numbers)
示例输出 1
示例输出 2
结论
虽然此 Python 脚本演示了如何使用 AI 技术进行内容检查,但基于 AI 的方法相对于传统的基于规则的 DLP 方法的效率和优势取决于多种因素,包括数据的复杂性、准确性要求和具体用例。组织应根据其要求和限制评估不同的方法,以确定最合适的内容检查解决方案。