

桔妹导读:滴滴自成立以来,有海量的数据存储在离线平台,离线数据虽然存储便宜,压缩比高,但不适用于线上使用。为此,我们提供了一键式DTS平台——FastLoad,帮助业务往在线存储系统搬运离线数据,目前主要针对滴滴自研分布式存储Fusion,Fusion以RocksDB为存储引擎,服务线上集群500+,承载业务数据1600TB+,总QPS峰值1200W+,是一个成熟稳定的分布式NoSQL/NewSQL解决方案。
0.
目录
1. 业务背景:雄关漫道真如铁
2. 技术探讨:工欲善其事必先利其器
- Ingest SST
- Map/Reduce产出全局有序文件
3. 系统架构:千磨万击还坚劲
4. 总结展望:直挂云帆济沧海
- 基于FastLoad的数据传输给业务带来的收益
- 发展规划
FastLoad致力于离线数据在线化,服务业务300+,单日运行次数1000+,在线搬运30TB+的数据,提供数百亿次高效查询,服务稳定性达到99.99%。

1.
业务背景:雄关漫道真如铁
在没有FastLoad以前,业务一般都会自己维护读离线数据,写在线存储引擎的业务逻辑。比如,滴滴有很多重要的业务有如下的场景:前一天的订单数据会落到离线平台,经过一些特征提取和分析,转换成业务需要使用的数据。在第二天线上高峰期前,需要把这部分数据及时导入线上,才能够不影响业务逻辑。这些业务都需要定时更新在线数据、线上使用最新数据,下面我们对需求进行提取。
定时更新像特征数据,一般需要小时级别甚至天级别的更新,所以业务需要有快捷的定时更新功能。
快速更新特征数据还有一个特点,就是数据量特别大,以乘客特征为例,动辄上 TB 级别数据量。这么大的数据量通过 SDK 写入肯定是不行的。刚开始业务方也确实是这么玩的,直接通过 Hadoop 任务调用 Redis SDK,然后一条条的写入 Fusion,一般是每天凌晨开始写数据,等到早高峰 8 点时大量读取。但是这种方法实践下来,经常导致 Fusion 各类超时,在早高峰打车已经来临时还在写凌晨的数据,非常影响稳定性。因此第 3 个需求是必须快速更新。
稳定性这个是毋容置疑的。
多表隔离有些业务有很多类特征数据,他们有隔离存储的需求,也有分类更新、分类查找的需求,因此需要多表来支持逻辑到物理的隔离。下面我们看下用户正常写存储的流程,如图展示了以RocksDB为引擎的存储的写入过程。
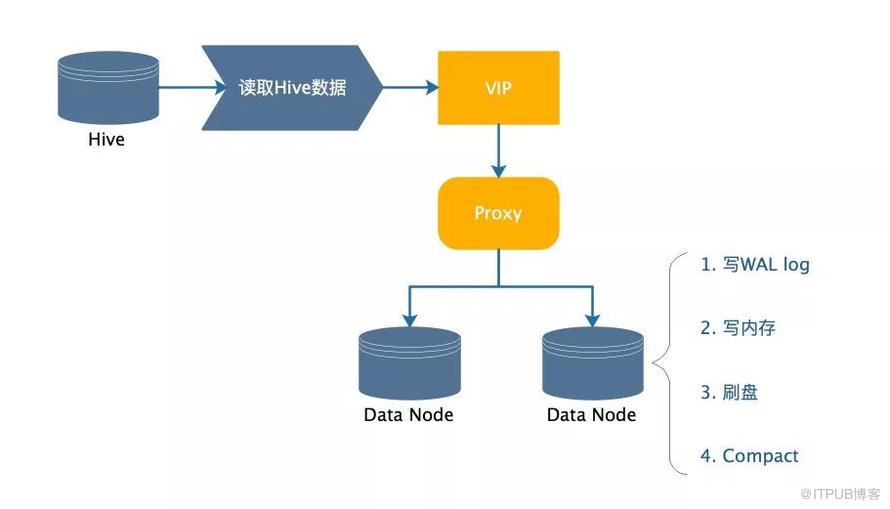
正常灌库流程如图可见,从Hive写到最终存储的链路比较长,数据要经过几次中转才能最终落盘。我们做一个公式换算,1TB的数据,以5w的QPS写入存储,每个请求写512B,需要大约12个小时,也就是半天的时间才能将数据完全写入。要是每天更新的任务,在早高峰之前根本不能取到最新的数据,是不满足业务场景的。为了满足上述提及的4点需求,我们需要转换思维,不能拘泥于传统的数据灌入方式。我们萌生了一个快速导入的想法,如果将文件直接拷贝到存储中,就可以避免上图中的1/2/3/4,直接对外开放读。
2.
技术探讨:工欲善其事必先利其器
▍Ingest SST
我们需要以文件方式导入到存储引擎中,借助了RocksDB提供的IngestFile接口,通过用户预先创建好的SST文件,直接加载到硬盘的LSM结构中,已达到快速导入的目的。直接构造SST文件并导入的方式,绕开了上图正常灌库的流程,避免了写WAL日志、写内存、刷盘等操作,同时RocksDB的Ingest能够尽可能地将数据放在LSM结构中最底层的位置,减少L0到Ln层不断Compact带来的写放大。
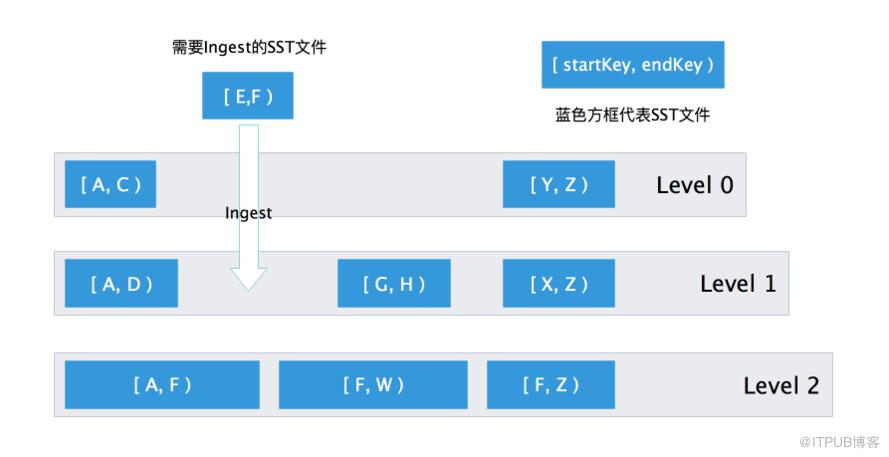
Ingest SST文件Ingest SST文件流程为:
- 检查需要导入的SST是否合法,包括文件之间Key值是否有重叠,文件是否为空,ColumnFamilyID是否合法等等。
- 阻塞DB实例的写入操作,对可能与Ingest文件有重叠的MemTable进行刷盘操作。阻止RocksDB执行新的Compact任务导致LSM结构更新。
- 确定Ingest的文件应该在磁盘LSM结构中的哪一层,RocksDB会尽可能地将文件放在Key值不重叠的最底层。如上图所示,Key值范围为[E, F]的SST文件将Ingest导入到了L1层;随后,根据当前存在的快照、LSM组织形式等设置SST文件的元信息。
- 将之前设置的阻塞标记全部删除。
总的来说,Ingest导入是RocksDB的一个很关键的功能特性,适合用户数据的大批量写入。上述描述了一个将新文件Ingest到已存在的DB实例中的流程,可以看出是比较重的操作,除了会导致停写停Compact,还会导致MemTable强制刷盘。所以对于每天更新的任务,我们完全可以每天往新的DB实例里导文件,这样就能避免很多的阻塞。
▍Map/Reduce产出全局有序文件
从上述的Ingest文件可以看出,导入文件的堵塞需要付出比较大的代价,堵塞在线写和增大系统Compact。我们可以通过往新DB实例中导文件避免堵塞写,通过保证SST全局有序避免系统Compact。从Hive到SST这一步,我们依赖了大数据引擎进行Map/Reduce,将原始数据作为输入,按照用户提交的拼接Key的方式,启动Map/Reduce任务直接构造最终DB需要的SST文件。
3.
系统架构:千磨万击还坚劲
经过上面的背景和技术细节,我们最终完成了如下图的系统架构。
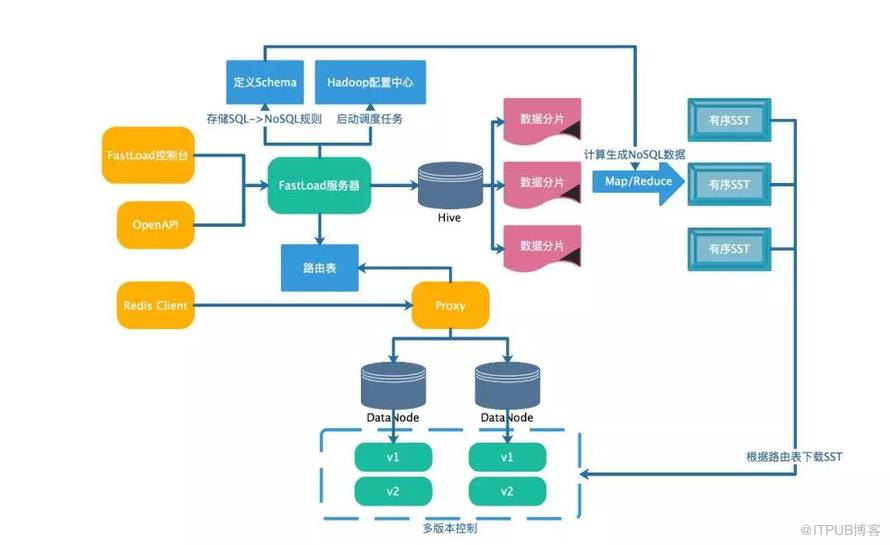
一键式DTS平台——FastLoad系统架构整个系统分为以下几个模块:
- 控制台服务:对外提供控制台表单和OpenAPI方式接入,提供创建任务、Schema转换规则等服务。
- 大数据调度模块:依赖Hadoop的计算资源,将Hive数据导出为我们需要的中间文件,在经过Map/Reduce的构建,生成全局有序的SST文件。
- 文件下载模块:根据分布式存储的路由表,将SST文件下载到不同的存储节点。
- 文件导入和DB切换:依赖上文提及的Ingest SST的方式,将文件一次性导入DB实例。为了避免上述提及的堵塞,我们提供往新DB实例导数据的选项,这样就可以避免因线上写而导致的堵塞,空数据也可以避免Compact。假如选择了新DB导入的选项,最后还会有一次DB新旧实例的切换,相当于一次链接映射。
4.
总结展望:直挂云帆济沧海
▍基于FastLoad的数据传输给业务带来的收益
- 大大缩短业务导数据耗时,1TB数据平均导入时间为1小时;
- 线上服务业务300+,每天运行次数1000+,每天导数据量30TB+;
- 服务稳定性达到99.99%,上线运行2年无任何重大事故;
- 高频运维操作一键自助完成,90% 的问题,5 分钟完成定位;
▍发展规划
- 架构优化,整体架构目前依赖Hadoop,可以考虑迁移到Spark,提升运行效率;
- 管控优化,提供更细致更全面的FastLoad监控和报表;
- 多产品应用,目前FastLoad主要针对NoSQL和NewSQL两种场景,同比可以应用在ES、MQ等场景;
- 新场景支持,离线数据的实时读取不仅对OLTP场景提供了更好的支持,也为接下来大热的HTAP场景提供了无限的可能。
本文作者
赵锐滴滴 | 高级工程师
从事分布式存储NoSQL/NewSQL的相关研发,参与从零开始构建滴滴分布式存储Fusion,有PB级别存储、千万QPS的存储经验