

桔妹导读:本文讲诉滴滴在分布式Nosql存储Fusion之上构建NewSQL的实践之路。详细描述Fusion-NewSQL的特性,应用场景,设计方案。
1.背景
Fusion-NewSQL是由滴滴自研的在分布式KV存储基础上构建的NewSQL存储系统。Fusion-NewSQ兼容了MySQL协议,支持二级索引功能,提供超大规模数据持久化存储和高性能读写。
▍我们的问题
滴滴的业务快速持续发展,数据量和请求量急剧增长,对存储系统等压力与日俱增。虽然分库分表在一定程度上可以解决数据量和请求增加的需求,但是由于滴滴多条业务线(快车,专车,两轮车等)的业务快速变化,数据库加字段加索引的需求非常频繁,分库分表方案对于频繁的Schema变更操作并不友好,会导致DBA任务繁重,变更周期长,并且对巨大的表操作还会对线上有一定影响。同时,分库分表方案对二级索引支持不友好或者根本不支持。鉴于上述情况,NewSQL数据库方案就成为我们解决业务问题的一个方向。
▍开源产品调研
最开始,我们调研了开源的分布式NewSQL方案:TIDB。虽然TIDB是非常优秀的NewSQL产品,但是对于我们的业务场景来说,TIDB并不是非常适合,原因如下:
- 我们需要一款高吞吐,低延迟的数据库解决方案,但是TIDB由于要满足事务,2pc方案天然无法满足低延迟(100ms以内的99rt,甚至50ms内的99rt)
- 我们的多数业务,并不真正需要分布式事务,或者说可以通过其他补偿机制,绕过分布式事务。这是由于业务场景决定的。
- TIDB三副本的存储空间成本相对比较高。
- 我们内部一些离线数据导入在线系统的场景,不能直接和TIDB打通。
基于以上原因,我们开启了自研符合自己业务需求的NewSQL之路。
▍我们的基础
我们并没有打算从0开发一个完备的NewSQL系统,而是在自研的分布式KV存储Fusion的基础上构建一个能满足我们业务场景的NewSQL。Fusion是采用了Codis架构,兼容Redis协议和数据结构,使用Rocksdb作为存储引擎的NoSQL数据库。Fusion在滴滴内部已经有几百个业务在使用,是滴滴主要的在线存储之一。Fusion的架构图如下:
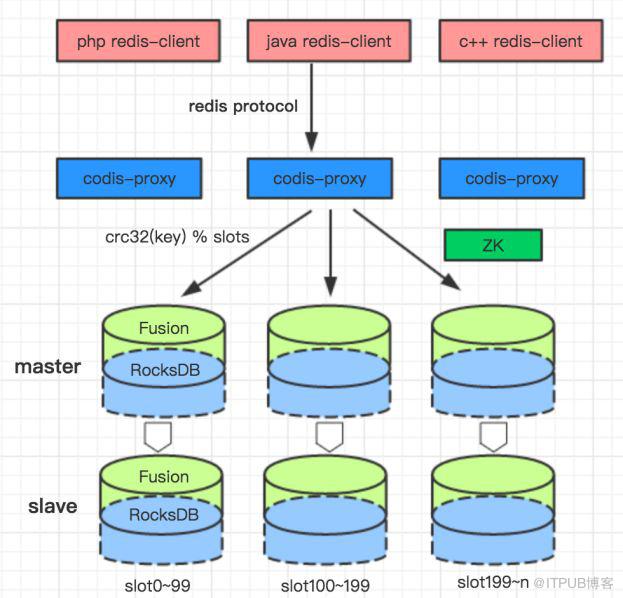
我们采用hash分片的方式来做数据sharding。从上往下看,用户通过Redis协议的客户端就可以访问Fusion,用户的访问请求发到proxy,再由proxy 转发数据到后端 Fusion 的数据节点。proxy 到后端数据节点的转发,是根据请求的key计算hash值,然后对slot分片数取余,得到一个固定的slotid,每个slotid会固定的映射到一个存储节点,以此解决数据路由问题。有了一个高并发,低延迟,大容量的存储层后,我们要做的就是在之上构建MySQL协议以及二级索引。那么如何将MySQL的数据格式转成Redis的数据结构存储就是我们必须面临的问题,后面会详细说。
2.需求
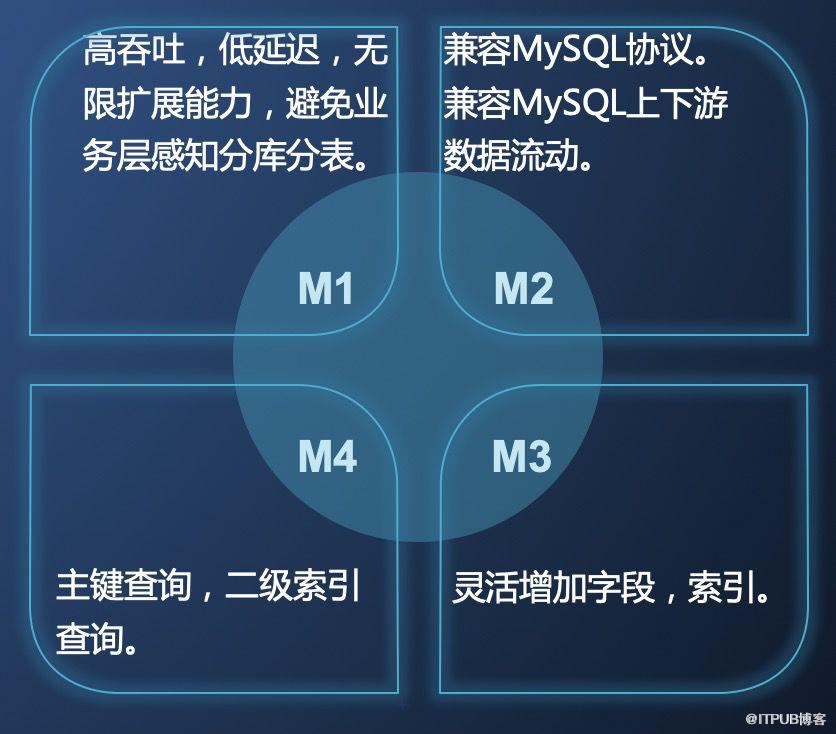
综合考虑大多数用户对需求,我们整理了我们的NewSQL需要提供的几个核心能力:
- 高吞吐,低延迟,大容量。
- 兼容MySQL协议及下游生态。
- 支持主键查询和二级索引查询。
- Schema变更灵活,不影响线上服务稳定性。
3.架构设计
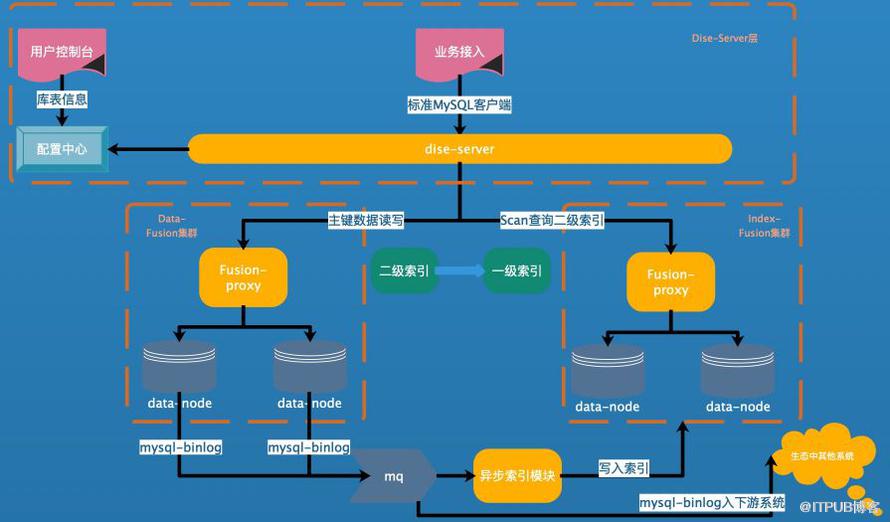
Fusion-NewSQL由下面几个部分组成:
- 解析MySQL协议的DiseServer
- 存储数据的Fusion集群-Data集群
- 存储索引信息的Fusion集群-Index集群
- 负责Schema的管理配置中心-ConfigServer
- 异步构建索引程序-Consumer负责消费Data集群写到MQ中的MySQL-Binlog格式数据,根据schema信息,生成索引数据写入Index集群。
- 外部依赖,MQ,Zookeeper
架构图如下:
4.详细设计
▍存储结构
MySQL的表结构数据如何转成Redis的数据结构是我们面临的第一个问题。
如下图:
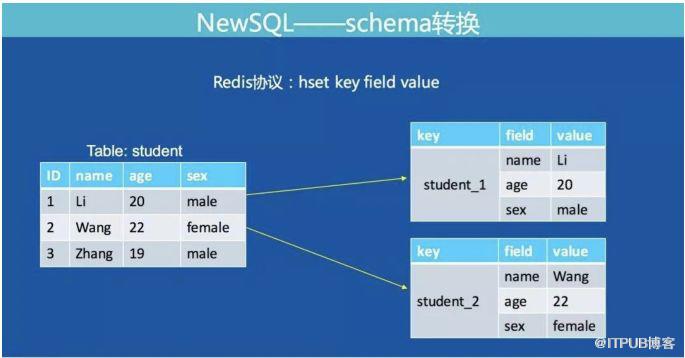
我们将MySQL表的一行记录转成Redis的一个Hashmap结构。Hashmap的key由表名+主键值组成,满足了全局唯一的特性。下图展示了MySQL通过主键查询转换为Redis协议的方式:
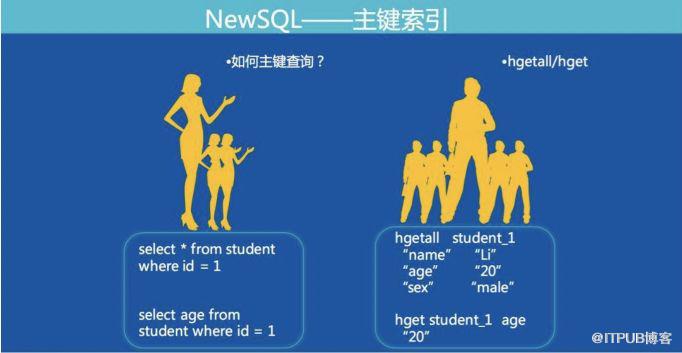
除了数据,索引也需要存储在Fusion-NewSQL中,和数据存成hashmap不同,索引存储成key-value结构。根据索引类型不同,组成key-value的格式还有一点细微的差别(下面的格式为了看起来直观,实际上分隔符,indexname都是做过编码的):
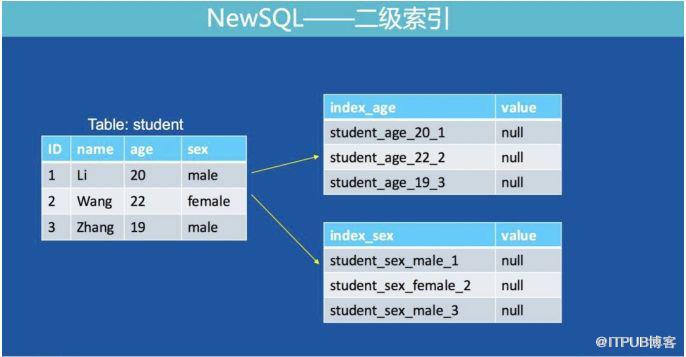
唯一索引:Key: table_indexname_indexColumnsValue Value: Rowkey
非唯一索引:Key: table_indexname_indexColumnsValue_Rowkey Value:null
造成这种差异的原因就是非唯一索引在加入Rowkey之前的部分是有可能重复的,无法全局唯一。另外,唯一索引不将Rowkey编码在key中,是因为在查询语句是单纯的“=”查询的时候直接get操作就可以找到对应的Rowkey内容,而不需要通过scan,这样的效率更高。
后面会在查询流程中重点讲述如何通过二级索引查询到数据。
▍数据读写流程
数据写入
- 用户通过MySQL-sdk将协议发给dise-server
- dise-server根据schema对用户写入的SQL做校验
- dise-server将校验通过的SQL转成Redis的Hashmap结构,通过Redis协议发给Data集群
- Data集群将数据写入wal文件,并将数据存储rocksdb。
- Data集群后台线程将wal文件消费,转成MySQL-Binlog格式。将数据发到MQ
- 异步索引模块消费MQ,将MySQL-Binlog根据操作类型(insert,update,delete)配合schema信息,构建索引信息,并将索引数据写入index集群。
通过上面的链路,用户的一条MySQL写操作就完成了数据存储和索引构建。由于通过数据构建索引这一步是通过MQ异步完成,所以会存在数据和索引有一定的时间差的情况。
查询
下面是一个使用二级索引查询数据的案例:
- dise-server接收到SQL查询,根据条件,选择索引,如果没有命中任何索引,给用户返回错误(Fusion-NewSQL不能以非索引字段作为查询条件)。
- 根据选中的索引,构建查询范围,通过scan命令遍历Index集群,获取符合条件的主键集合。下图以一个SQL查询,展示使用scan遍历二级索引的例子:
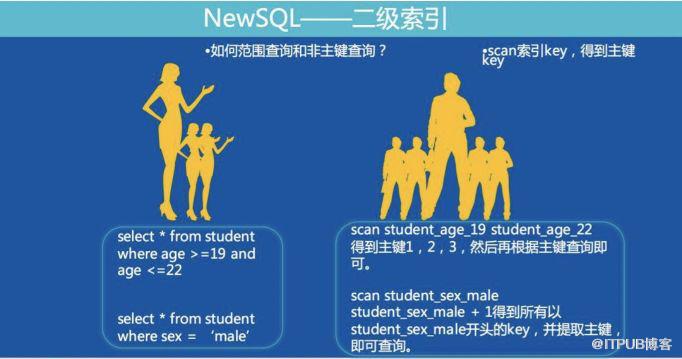
- 根据主键,通过hgetall命令向Data集群查询符合条件的结果集。
- 将结果集构建成MySQL的结果返回给用户。
根据上面索引数据的格式可以看到,scan范围的时候,前缀必须固定,映射到SQL语句到时候,意味着where到条件中,范围查询只能有一个字段,而不能多个字段。比如:

索引是age和name两个字段的联合索引。如果查询语句如下:select * from student where age > 20 and name >‘W’;scan就没有办法确定前缀,也就无法通过index_age_name这个索引查询到满足条件的数据,所以使用KV形式存储到索引只能满足where条件中有一个字段是范围查询。当然可以通过将联合索引分开存放,多次交互搜索取交集的方式解决,但是这就和我们降低RPC次数,降低延迟的设计初衷相违背了。为了解决这个问题,我们引入了Elastic Search搜索引擎,这部分后面会详细说明。
▍Schema变更
用户涉及Schema变更时,会以工单形式发给管控系统。管控系统审批过后,会将变更请求推给配置中心,配置中心进行安全性检查后,将新的Schema写入到存储中,并给各个节点推送变更。字段变更:节点接收到推送,更新本地的Schema。对于历史数据,并不真正去修改数据,而是在查询的时候,根据Schema信息匹配字段,如果数据比Schema缺失某些字段,就使用默认值代替;如果数据比Schema多了字段,就隐藏掉多余字段不展示。新增索引分为两步处理:
- 新增索引,历史数据不处理,增量数据立刻走索引构建流程。
- 通过历史索引构建工具,扫描历史数据,构建新索引的KV,将历史数据完成索引构建。这里有个优化点,扫描slave而不是master,避免对线上产生影响。
5.生态构建
一个单独的存储产品解决所有问题的时代早已经过去,数据孤岛是没有办法很好服务业务的,Fusion-NewSQL从设计的那天起就考虑了和其他存储系统的打通。
▍Fusion-NewSQL到其他存储系统
Fusion-NewSQL通过兼容MySQL的Binlog格式,将数据发到MQ中。下游各个系统凡是能接入MySQL数据的,都可以通过消费MQ中相同格式的Fusion-NewSQL数据,将数据存到其他系统中。这样的方式用最小的工作量最大程度做到了兼容。
▍Hive到Fusion-NewSQL
Fusion-NewSQL还支持将离线的Hive表中的数据通过Fusion-NewSQL提供的FastLoad(DTS)工具,将Hive表数据转入到Fusion-NewSQL,满足离线数据到在线的数据流动。如果用户自己完成数据流转,一般会扫描Hive表,然后构建MySQL的写入语句,一条条将数据写入到Fusion-NewSQL,流程如下面这样:

- MySQL-client将写请求发给DiseServer。
- DiseServer将MySQL写做解析,转成hashmap将转换后的数据以Redis协议发给Data集群。
- Data集群的存储节点收到数据,将数据写到wal文件。
- Data集群的存储节点走Rocksdb的写流程,这里包括了写memtable,还有可能memtable写满,发生flush以及触发后台的compact。
- 异步线程消费wal,将数据构建MySQL-Binlog格式发到MQ。
- 异步索引程序消费MySQL-Binlog,构建Index集群需要的数据,向Index集群发送写入请求。
- Index集群的存储节点写wal。
- Index集群的存储节点进入Rocksdb的写流程。
从上面的流程可以看出这种迁移方式有几个痛点:
- 有这种Hive到Fusion-NewSQL数据导入需求的用户都需要开发一套相同逻辑的代码,维护成本高。
- 每条Hive数据都要经过较长链路,数据导入耗时较长。
- 离线平台的数据量大,吞吐高,直接大幅提升在线系统的QPS,对在线系统的稳定性有较大影响。
基于上述的痛点,我们设计了Fastload数据导入平台,通过约定Hive到Fusion-NewSQL的表格式,使用Hadoop并发处理数据,并构建Rocksdb能识别的sst存储文件,绕过复杂的DISE写链路,直接将数据导入到Fusion-NewSQL中,流程如下:
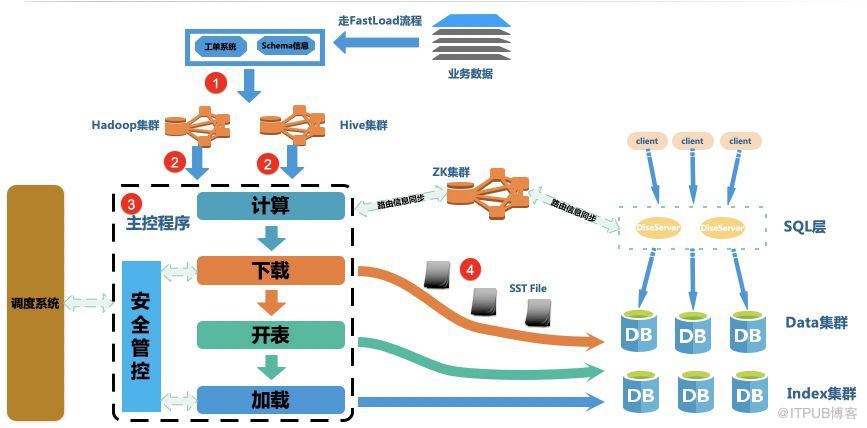
- 用户填写工单,选中将指定Hive表的某些字段映射为Fusion-NewSQL表的字段(这里可以Hive中多个字段组成一个Fusion-NewSQL字段)。
- Hadoop遍历Hive表,并且通过Zookeeper获取数据应该存放在Data集群和Index集群的路由信息
- 通过上面的遍历,计算,之后,将数据直接构建成、Rocksdb能识别的sst,并且其中存的数据已经是按DISE的表结构信息组成的KV数据。
- 将sst文件直接发送到指定的存储节点,存储节点或通过Rocksdb提供的ingest功能,直接将sst文件加载到Fusion-NewSQL中,用户可以读到。
这个方案避免了冗长复杂的写链路,同时不会增加系统的QPS,在磁盘和网络IO没有达到瓶颈的情况下对线上访问几乎是没有任何影响;同时,用户只需要填写Hive到Fusion-NewSQL的Schema映射关系即可,不必再关心实现。
▍通过Elastic Search实现复杂查询
在业务使用MySQL或Fusion-NewSQL的过程中,我们发现有这样一种场景:业务的查询条件很复杂,涉及的字段数,条件,聚合都比较多,这种场景下,业务会选择将Elastic Search作为MySQL或Fusion-NewSQL的下游,将数据导入Elastic Search,然后通过Elastic Search丰富的搜索能力,先从Elastic Search中获取数据在MySQL或Fusion-NewSQL的主键,然后再根据主键获取全部数据。根据上面的场景,Fusion-NewSQL提供一个特殊的索引类型:ES。用户在创建索引的时候,可以将需要做复杂查询的字段勾选出来,共同构建成一个ES索引,这样既满足了业务需求,避免了每个业务都需要开发一套和Elastic Search交互的复杂逻辑,又统一了数据库使用接口都为MySQL。同时,还弥补了前面提到的Fusion-NewSQL的KV二级索引不能支持多个字段范围检索的能力。架构图如下:
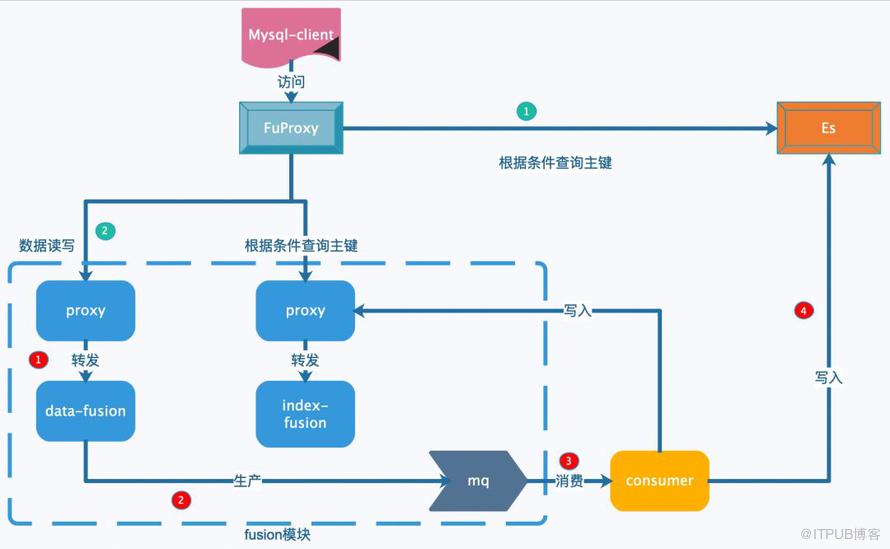
ES索引只是在上图红4处,将ES索引中包含的字段信息和主键写入到Elastic Search中。在查询时绿1如果选中了ES类型的索引,就根据where条件中涉及的字段,组装成Elastic Search的DSL语句,从Elastic Search获取主键,再从Data集群获取。由于Elastic Search查询的延迟比较慢,Fusion-NewSQL可以支持一张表的多个索引采用KV索引和ES索引并存,对于延迟要求高,查询条件相对简单的使用KV索引;对于查询条件复杂,延迟要求不高的使用ES索引。
6.总结
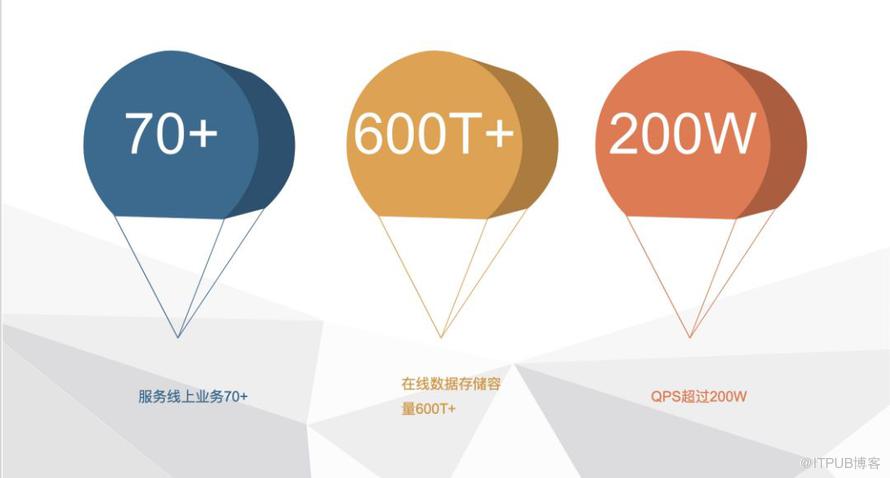
Fusion-NewSQL当前已经现已经接入订单、预估、账单、用户中心、交易引擎等70个核心业务,总QPS超过200W,总数据超过600TB。
当然,Fusion-New不是一个通用完备的NewSQL方案,而是在已有的nosql数据库基础上,通过对SQL协议的支持以及组合各种组件,构建对一个对外表达的数据库,但是这种方式,可以以最小的开发代价,满足大多数的业务场景,具备较高的投入产出比。
7.后续工作
- 有限制的事物支持,比如让业务规划落在一个节点的数据可以支持单机跨行事务。
- 实时索引替代异步索引,满足即写即读。目前已经有一个写穿+补偿机制的方案,在没有分布式事务的前提下满足正常状态的实时索引,异常情况下保证数据索引最终一致的方案。
- 更多的SQL协议和功能支持。
本文作者
▬李 鑫滴滴 | 资深软件开发工程师多年分布式存储领域设计及开发经验。曾参与Nosql/NewSQL数据库Fusion,分布式时序数据库sentry,NewSQL数据库SDB等系统的设计开发工作。