介绍
在我的上一篇文章中,我介绍了如何在 Windows 上设置和使用 Hadoop。现在,本文将介绍在 Windows 操作系统上为 Apache Spark 配置本地开发环境。
Apache Spark 是最流行的群集计算技术,专为快速可靠的计算而设计。它提供隐式数据并行性和默认容错能力。它可轻松与 HIVE 和 HDFS 集成,并提供并行数据处理的无缝体验。你可以在https://spark.apache.org阅读更多关于火花。
默认情况下,Spark SQL 项目不会在 Windows 操作系统上运行,并要求我们首先执行一些基本设置;例如,在 Windows 操作系统上运行 Spark SQL 项目。这就是我们在本文中要讨论的所有问题,因为我没有发现它在互联网上或书籍中记录得很好。
本文还可用于在 Mac 或 Linux 上设置 Spark 开发环境。只需确保您从 Spark 的网站下载正确的操作系统版本。
您可以在此处引用 GitHub 中本文中使用的 Scala 项目:https://github.com/gopal-tiwari/LocalSparkSql。
期待什么
在本文的末尾,您应该能够在 Windows 操作系统上创建/运行Spark SQL项目和火花外壳。
我把这篇文章分为三部分。您可以遵循以下三种模式中的任何一种,具体取决于您的特定用例。
您可能还喜欢:
完整的Apache火花集合[教程和文章]。
激发本地开发设置模式
- 单个项目访问(单个项目单一连接)
- 每个项目都有自己的元存储和仓库。
- 一个项目创建的数据库和表将不能被其他项目访问。
- 一次只能运行或执行一个 Spark SQL 项目。
- 多项目访问(多项目单一连接)
设置时间:20 分钟
功能:扩展- 每个项目将共享一个公共元存储和仓库。
- 由一个项目创建的表将可由其他项目或火花壳访问。
- 它将提供一个伪群集,就像感觉一样。
- 一次只能运行或执行一个 Spark SQL 项目。
- 完整群集式访问(多项目多连接)
设置时间:40 分钟
功能:完整- 此配置有点繁琐,但一次性设置将使您能够为元存储打开多个连接
设置时间:15 分钟
功能:有限
火花错误解决方案
他们中的许多人可能尝试过在 Windows 上运行火花,在运行项目时可能面临以下错误:
16/04/02 19:59:31 WARN NativeCodeLoader: Unable to load native-hadoop library for
your platform... using builtin-java classes where applicable
16/04/02 19:59:31 ERROR Shell: Failed to locate the winutils binary in the hadoop
binary path java.io.IOException: Could not locate executable null\bin\winutils.exe
in the Hadoop binaries.
这是因为您的系统没有适用于 Windows 操作系统的本机 Hadoop 二进制文件。
你可以按照我上一篇文章构建一个,或者从https://github.com/cdarlint/winutils下载一个。
以下错误还与 Windows 操作系统的本机 Hadoop 二进制文件有关。
16/04/03 19:59:10 ERROR util.Shell: Failed to locate the winutils binary in the
hadoop binary path java.io.IOException: Could not locate executable
C:\hadoop\bin\winutils.exe in the Hadoop binaries.
解决方案是相同的。我们需要 HADOOP_HOME 使用本机 Windows 二进制文件进行设置。
所以,只要跟着这篇文章,在本教程的结尾,你应该能够摆脱所有这些错误。
下载所需文件
- 下载并安装JDK根据您的操作系统和CPU架构从https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html。
- 安装Scala版本取决于您https://www.scala-lang.org/download/all.html使用的Spark版本。
- 下载并安装7-zip从https://www.7-zip.org/download.html。
- 下载并提取Apache火花使用7zip从http://spark.apache.org/downloads.html。
- 从https://github.com/cdarlint/winutils下载 zip 或克隆 Hadoop Windows 二进制文件。
- 如果未安装 IDE,请安装一个 IDE。Intellij IDEA 是首选,您可以从https://www.jetbrains.com/idea/download/#section=windows获取社区版本
microsoft.com/en-us/download/details.aspx?id=5555″rel=”nofollow”目标=”_blank”\https://www.microsoft.com/en-us/下载/详细信息.aspx?id=5555。
对于 32 位 (x86) OS,您只需安装 a.,对于 64 位 (x64),请安装 a. 和 b。
在本教程中,我们假设 Spark 和 Hadoop 二进制文件在C:#驱动器中解压缩。但是,您可以在系统中的任何位置解压缩它们。
设置和安装
Jdk
在继续之前,让我们确保 Java 设置正确完成,并且使用 Java 的安装目录更新环境变量。
要确认 Java 已安装在您的计算机上,只需打开 cmd 并键入 java –version 。您应该能够看到系统上安装的 Java 版本。
如果您收到错误消息,如”‘java’未被识别为内部或外部命令、可操作程序或批处理文件”,请按照以下步骤操作。否则,请跳过它。
- 执行下载的 JRE 和 JDK 设置,并在默认设置下完成安装。
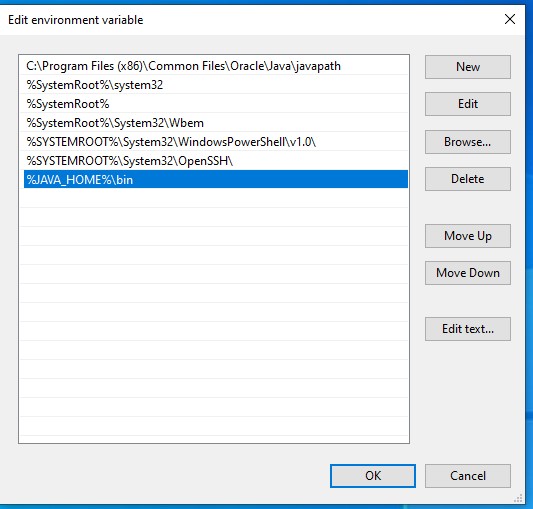
- 现在,打开系统环境变量对话
- 对于 Windows 7,右键单击“我的计算机”并选择“属性>高级“。
- 对于 Windows 8,转到“控制面板”>系统 > 高级系统设置。
- 对于 Windows 10,转到“控制面板”>系统和安全 > 系统 > 高级系统设置。
- 单击”环境变量”按钮。
- 单击“系统变量”部分中的“新建…”按钮。然后,
JAVA_HOME键入变量名称字段,并在变量值字段中提供 JDK 安装路径。 - 如果路径包含空格,请使用缩短的路径名称 – 例如,C:\Progra_1_Java_jdk1.8.0_74
- 适用于 64 位系统上的 Windows 用户
- Progra_1 = “程序文件”
- Progra_2 = “程序文件(x86)”
- 要确认 Java 安装,请打开一个新的 cmd 并键入
java –version,您应该能够看到刚刚安装的 Java 版本。 - 您可能需要安装 Scala,具体取决于您的 Spark 版本。
- 在本文中,我们将使用 Spark 2.4.4 和 Scala 2.12.10。
- 只需执行下载的scala-2.12.10.msi,然后按照安装说明操作
- 您可以使用Scala插件设置Eclipse,或者只是安装IntelliJ IDEA。
- 您可以选择从首次设置屏幕或设置 > 插件 > 搜索和安装 Scala 中安装 Scala 插件。
- 如果您在安装插件期间有 VPN 代理问题,您可以选择脱机插件安装。
- 确保文件> 设置 > 插件窗口显示已安装 Scala 插件,如下图所示:
- 使用 7 zip(即 winutils master.zip)打开下载的 GitHub 存储库https://github.com/cdarlint/winutils。
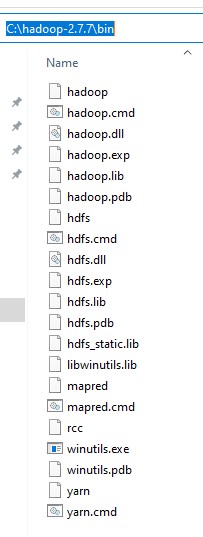
- 在里面,你会发现文件,有2.7.7。现在,将其提取到C:*驱动。
- 您的C:_hadoop-2.7.7_bin目录应如下所示:
- 提取完成后,我们需要添加新
HADOOP_HOME的系统环境变量 - 使用 7-zip(即 spark-2.4.4-bin-hadoop2.7.gz)打开下载的 Spark gz 文件。
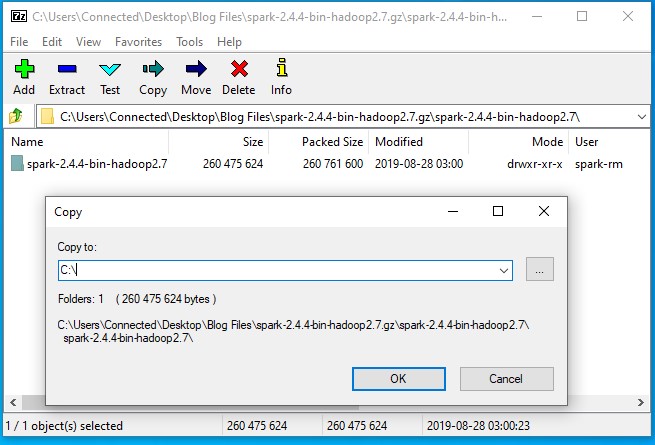
- 在里面,你会发现焦油文件火花-2.4.4-bin-hadoop2.7。双击它,并将火花-2.4.4 bin-hadoop2.7目录提取到C:*驱动器。
- 您的C:*spark-2.4.4bin-hadoop2.7目录应如下所示:
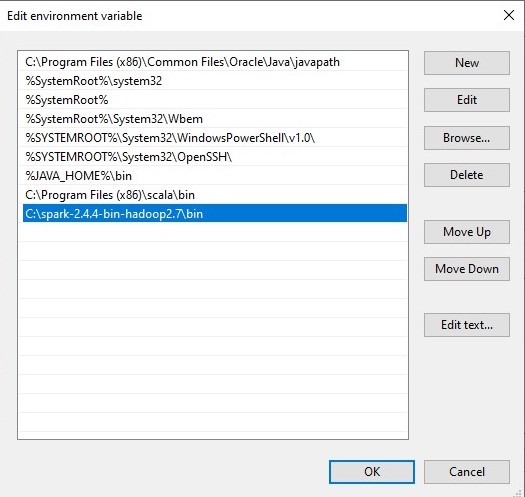
- 提取完成后,我们需要将 Spark bin 目录添加到系统环境”路径”变量中。
- 编辑路径变量并添加”C:\spark-2.4.4-bin-hadoop2.7_bin”,如下图所示:

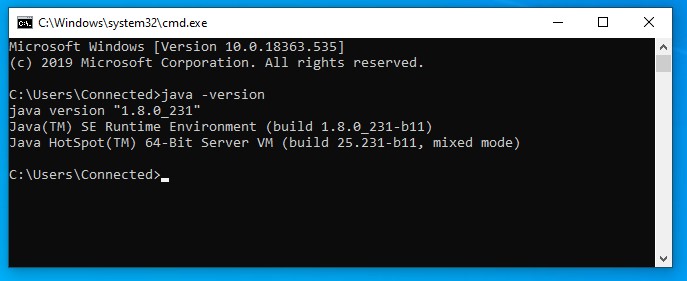
如果命令提示听起来与上图类似,您就好去。否则,您需要检查您的设置版本是否与操作系统体系结构 (x86、 x64) 匹配。环境变量路径也可能不正确。
Scala
命令提示应如下所示:
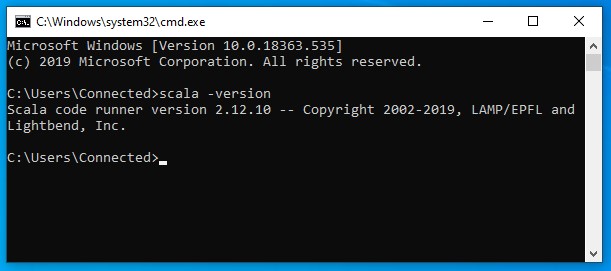
IntelliJ IDEA 设置

哈多普家庭设置
jpg” 数据-新=”假”数据大小=”26042″数据大小格式化”26.0 kB”数据类型=”temp”数据 url=”/存储/临时/12944315 -8.jpg”src=”http://www.cheeli.com.cn/wp-内容/上传/2020/02/12944315-8.jpg”样式=”宽度:661px;显示:块;垂直对齐:顶部;边距:5px自动;文本对齐:中心;”/>
火花主页设置
注意:如果您没有管理员添加环境变量的访问权限,不要担心,因为您可以在 IDE 中单独为每个项目设置它
单个项目访问
现在,让我们创建一个名为”LocalSparkSql”的斯卡拉-Maven项目。或者,您也可以从 GitHub 克隆它:https://github.com/gopal-tiwari/LocalSparkSql。
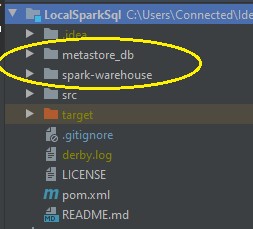
项目结构如下所示:
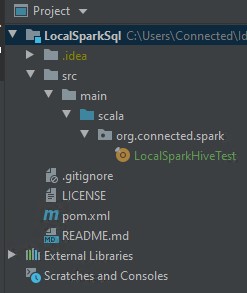
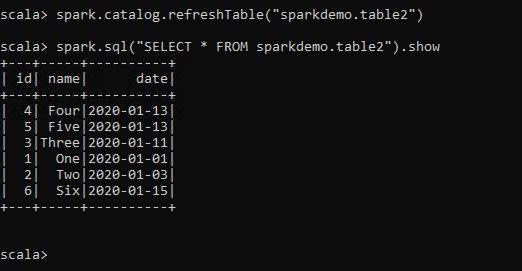
本地火花测试.scala
xxxxxxxxx
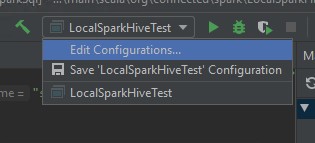
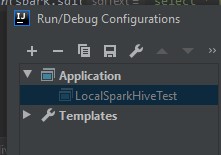
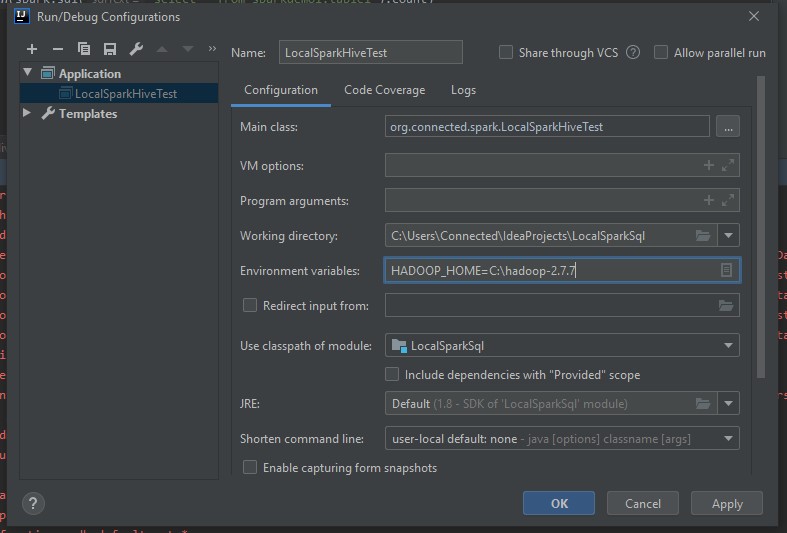
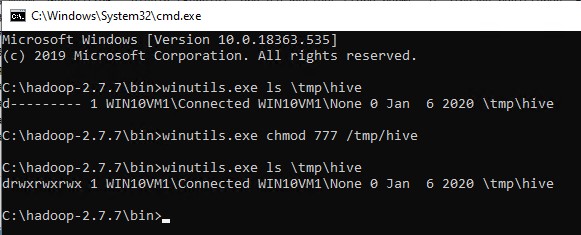
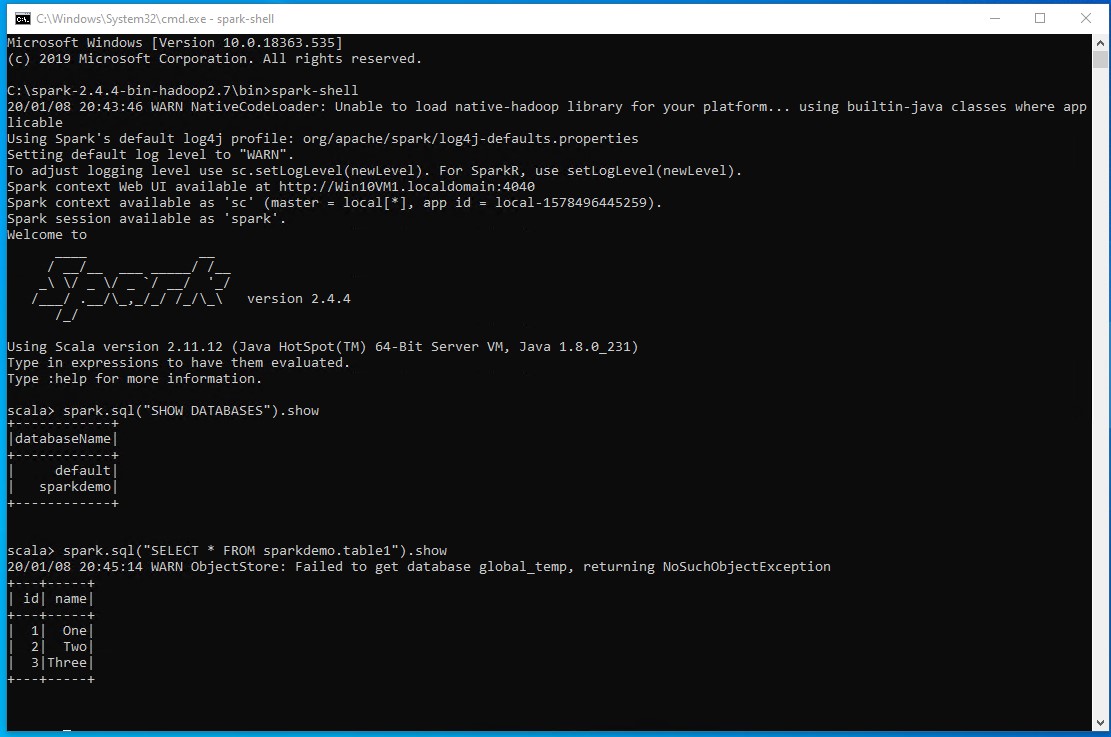
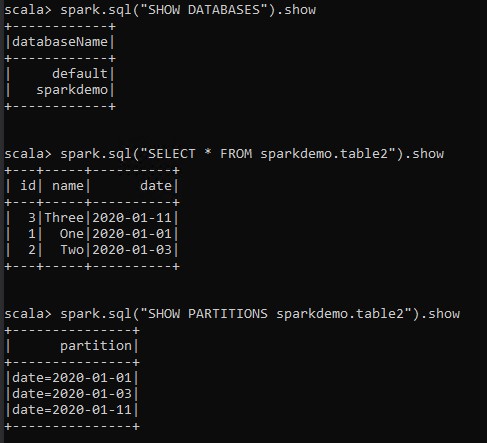 从 SQL 命令输出
从 SQL 命令输出