
这是奇怪的时代。城市被封锁,很少人在外面冒险。因此,按需物流服务(如在线食品配送)的使用增加并不让人感到意外。
这些应用程序在下订单后提供对 ETA 的近乎实时的跟踪。构建可扩展、分布式和实时 ETA 预测系统是一项艰巨的任务,但如果我们能简化其设计呢?我们将将我们的系统分解成碎片,以便每个组件负责一个主要工作。
让我们来看看构成系统的组件。
- 送货员/骑手应用 – 安装在送货员设备上的 Android/iOS 应用。
- 客户应用 – 安装在客户设备上的 Android/iOS 应用。
- Rockset – 为所有型号和服务供电的查询引擎。
- 消息队列 – 用于在各种组件之间传输数据。对于此示例,我们将使用Kafka。
- 键值存储 – 用于存储模型的订单和参数。对于此示例,我们将使用DynamoDB。
模型输入
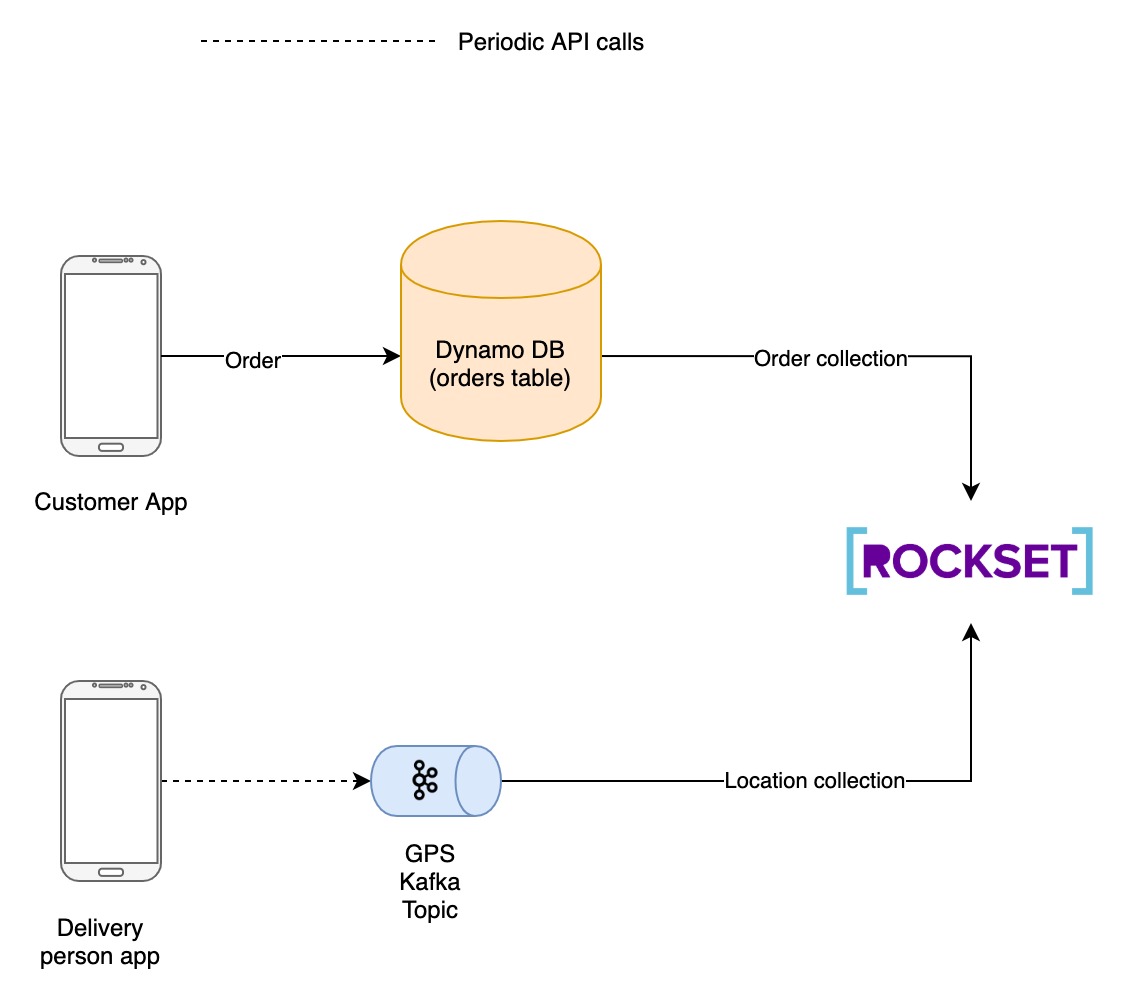
驱动程序位置
要获得准确的 ETA 估计,您需要送货员的位置,特别是纬度和经度。您可以通过设备中的 GPS 轻松获取此信息。对设备 GPS 提供程序的呼叫返回纬度、经度和位置(以米为单位)的准确性。
您可以在应用中运行后台服务,每 10 秒检索一次 GPS 坐标。因此,坐标的粒度太细,无法进行预测。为了增加GPS的粒度,我们将使用地理哈希的概念。地理哈希是表示 M 平方英里面积的位置的标准化 N 字母哈希。N 和 M 成反比,因此较大的 N 表示较小的区域 M。有关地理哈希的信息,请参阅此。
有数以吨计的图书馆可以将经纬度转换为地貌。在这里, 我们将使用地理由大卫莫滕得到一个 6 – 7 字母地理哈希。
然后,该服务将地理哈希以及坐标推送到 Kafka 主题。Rockset从这个Kafka主题中引入数据,并更新到一个名为位置的集合中。
订单
客户下订单存储在 DynamoDB 中,以供进一步处理。订单通常经历一个由以下状态组成的生命周期:
在 DynamoDB 中更新上述所有状态更改以及源位置、目标位置、订单详细信息等其他数据。订单交付后,实际到达时间也会存储在数据库中
ML 型号
指数平滑
我们有实际到达时间以及订单表中的订单来源和目的地。我们将称它为TA。您可以将所有具有源的 TA的均值作为送货人员的最新位置和目的地作为客户的位置,并可以获得近似的 ETA。但是,这并不准确,因为它没有考虑到不断变化的因素,例如该地区的新施工活动或通往目的地的新较短的路线。
为此,我们需要一个简单易用的预测模型,并且具有良好的准确性。
这就是指数平滑发挥作用的地方。使用公式计算指数平滑值:
St = 阿尔法 = Xt = (1 – 阿尔法) = St-1
在哪里
- St => 时间 t 平滑值 t
- Xt => 时间 t 时的实际值 t
- Alpha => 平滑系数
在我们的上下文中,S t表示 ETA,X t表示订单表中源目标对的最新实际到达时间。
Etat = Alpha = Tat = (1 – 阿尔法) = Etat-1
岩石集
当前系统的服务层需要满足三个主要条件:
- 能够每分钟处理数百万次写入 – 每个送货员的应用程序将每 5-10 秒推送一次 GPS 坐标,这将导致一个新的 ETA。一个典型的大型食品配送公司有近10万送货员。
- 数据提取延迟应该最小 – 对于出色的 UX,我们应该能够在客户应用更新 ETA 时立即更新。
- 能够快速处理架构更改 – 我们可以存储其他元数据,如 ETA 预测准确性和模型版本。每当添加新字段时,我们都不希望创建新数据源。
Rockset 满足了所有这些需求。它有:
- 动态缩放 – 根据需要添加更多资源以处理大量数据。
- 分布式查询处理 – 跨多个节点的查询并行化,以最大限度地减少延迟
- 无架构 Ingest – 支持架构更改。
Rockset有一个内置连接器阿帕奇卡夫卡。我们可以使用此 Kafka 连接器来输入送货员的位置数据。
为了在 Rockset 中执行指数平滑,我们创建两个查询 Lambdas。Rockset 中的查询 Lambdas 被命名为”存储在 Rockset 中的参数化 SQL 查询”,这些查询可以从专用 REST 终结点执行。
1. calculate_ETA:查询 Lambda 将 alpha、源和目标作为参数。它返回指数平滑的 ETAorders_fixed
在哪里
source_geohash = :源
和
destination_geohash = :d
订购者
time_i德斯克, order_id Asc
) 作为 idx
) 作为条款
)”数据-lang=”文本/x-sql”=
x
选择
(:阿尔法 * 总和 (术语) = (Pow((1作为ans
4
(
5
(
6
选择
7
order_id,
8
ta_i,
9
(ta_i * Pow((11作为术语,
10
time_i,
11
idx
从
13
(
14
选择
15
order_id,
16
和ta_ias一样
17
time_i,
18
ROW_NUMBER() 超过 (
19
订购者
德斯克, order_id ASC
21
AS idx
22
从
23
公地. orders_fixed
24
在哪里
25
source_geohash = :源
26
和
27
28
订购者
29
德斯克Asc
30
AS idx
31
作为术语
32
)
2. calculate_speed:此查询 Lambda order_id参数,并返回在运输过程中送货人员的平均速度。它运行以下查询:
Sql
X
1
27
1
选择
2
算作AS速度
3
从
4
(
选择
6
地理,
7
1)结束 (
8
订购者
9
德斯克
10
作为prev_geo,
11
ts,
12
1)结束 (
13
14
德斯克
15
作为prev_ts
16
从
17
(
18
选择
19
作为双倍的地理,
20
order_id,
21
22
从
23
公地. 位置
24
在哪里
25
order_id €:order_id
26
作为ts
27
作为速度
预测 ETA
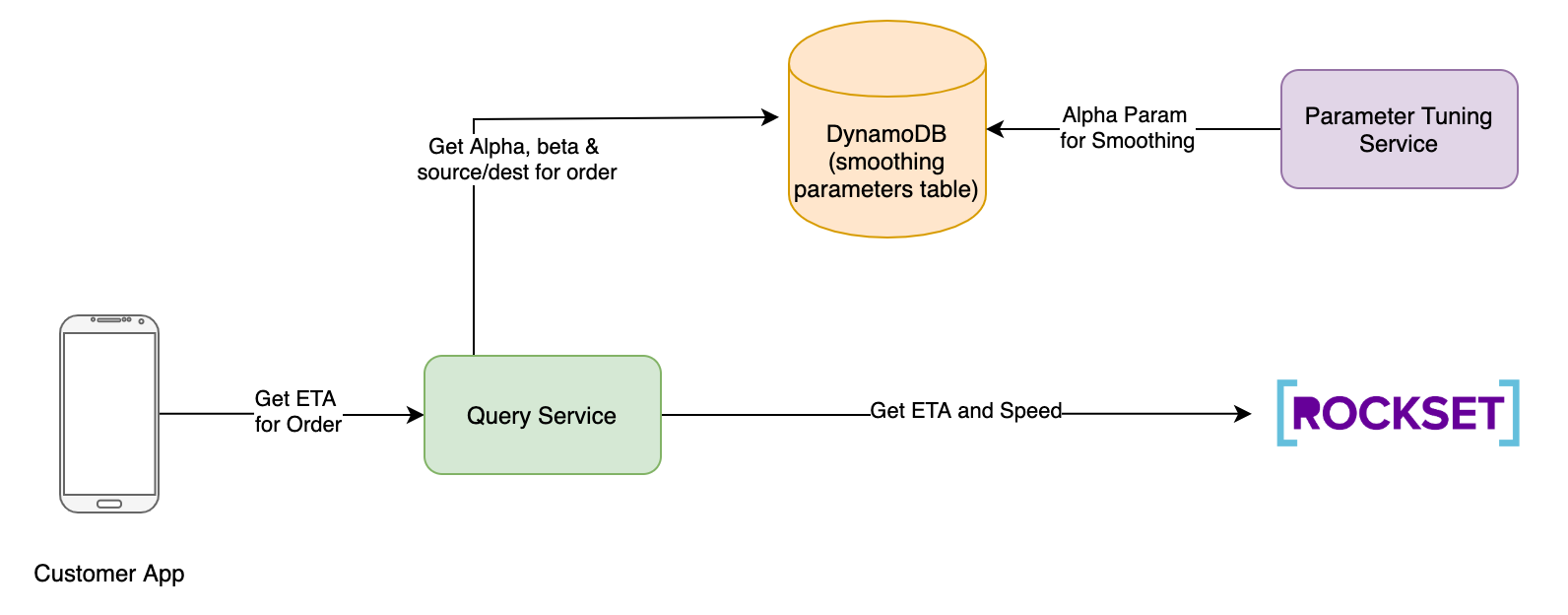
客户应用启动预测 ETA 的请求。它在 API 调用中传递订单 ID。
请求转到查询服务。查询服务执行以下功能:
- 从 DynamoDB 获取最新的平滑因子 Alpha 和 Beta
有关详细信息,请参阅步骤 6
获取订单 ID 的目标地理哈希。
从位置集合中获取当前驱动程序地理哈希。
触发calculate_ETA在 Rockset 中查询 Lamba,平滑因子 alpha 作为参数,驱动程序地理哈希作为来自步骤 2 的源地理哈希和目标地理哈希。让我们称之为历史埃塔。
壳
x
1
23
1
卷曲- 请求后发 |
2
- - url https://api.rs2.usw2.rockset.com/v1/orgs/self/ws/commons/lambdas/calculateETA/versions/f7d73fb5a786076c
3
- h'授权: 您的 Rockset API 密钥' |
4
-H"内容类型:应用程序/json" |
5
- d'*
6
"参数": |
7
8
"名字""阿尔法",
9
"类型""浮动",
10
"值""0.7"
11
},
12
{
13
"名称""目的地",
14
"类型""字符串",
"值":" tdr38d"
16
},
17
{
18
"名称""来源",
19
"类型""字符串",
20
"值""tdr706"
21
}
22
]
'
5. 在 rockset calculate_speed使用当前订单 ID 作为 Param 的查询 Lambda 触发器
壳
X
1
13
卷曲 - 请求后]
2
- - url https://api.rs2.usw2.rockset.com/v1/orgs/self/ws/commons/lambdas/calculate_speed/versions/cadaf89cba111c06
3
- h'授权: 您的 Rockset API 密钥' |
4
-H"内容类型:应用程序/json" |
5
- d'*
6
"参数": |
7
{
8
9
"类型""字符串",
10
"值""abc"
11
}
12
]
13
}'
6. 预测的 ETA 然后由查询服务计算为
预测 ETA = Beta * (历史 ETA) = (1 - Beta) * 距离(驱动器、目的地)/速度
然后,预测的 ETA 将返回到客户应用。
反馈循环
ML 模型需要再培训,以便其预测准确。在我们的场景中,有必要重新训练ML模型,以便考虑到不断变化的天气条件、节日等。这是参数调优服务发挥作用的地方。
参数调整服务
完成。</p>
<p>一旦服务计算了 Alpha 和 Beta 参数,它们就存储在 DynamoDB 中,该表中名为<strong>) 。查询服务收到来自使用者应用的请求时,会从该表中获取参数。
。查询服务收到来自使用者应用的请求时,会从该表中获取参数。
您可以使用位置收集中的 ETA 数据每周训练一次参数调优模型。
结论
该体系结构设计为每分钟处理超过一百万个请求,同时具有足够的灵活性,可以支持应用程序的扩展。该体系结构还允许开发人员切换或插入组件,例如添加新功能(例如天气)或添加筛选器图层以优化 ETA 预测。在这里,Rockset 帮助我们解决三个主要要求:
- 低延迟复杂查询 - Rockset 允许我们进行复杂的查询,例如只需使用 API 调用进行指数平滑。这是通过利用查询 Lambdas 完成的。Lambdas 还支持允许我们查询不同位置的参数。
- 高度可扩展的实时引入- 如果您的平台上有大约 10 万个驱动程序,并且每个应用每 5 秒发送一个 GPS 位置,那么您正在处理每分钟 120 万请求的吞吐量。Rockset 允许我们在事件发生的几秒钟内查询此数据。
- 来自多个源的数据- Rockset 允许我们使用需要最少配置的完全托管连接器从多个来源(如 Kafka 和 DynamoDB)进行摄入。
Comments are closed.

