
随着霍顿工程流消息管理器(smm) 今年的发布, 我们专注于帮助 devops 和平台团队治愈他们的卡夫卡失明。hortonworks 产品和工程团队继续投资于 smm 功能建设, 并提供新的即将推出的功能, 如警报和主题生命周期管理。
除了 smm 投资外, 该团队还一直专注于应用程序和 bi 开发人员角色的需求, 以帮助他们更成功地实施不同的用例, 其中卡夫卡是应用程序体系结构的关键组件。
为此, 产品和工程团队一直在与我们最大的企业卡夫卡客户中的应用程序架构师和开发人员进行访谈。从这些讨论中, 显然出现了若干趋势和要求:
- 趋势 #1: 卡夫卡正在成为企业中事实上的流媒体活动中心。
- 趋势 #2: 客户开始使用卡夫卡进行长期存储。例如: 卡夫卡主题的保留期越来越长。卡夫卡越来越多地被用作流媒体事件存储基板。
- 关键要求: 应用程序和 bi\ sql 开发人员需要基于不同用例/要求的不同卡夫卡分析工具访问模式。当前的工具是有限的。
3新的卡夫卡分析访问模式引入应用程序和 bi 开发人员
为了满足这些趋势/要求, 即将推出的 hortonworks 数据平台 (hdp) 3.1 和 hortonworks datafflow (hdf) 3.3 版本计划为应用程序和 bi 开发人员引入3个新的强大的卡夫卡分析访问模式。
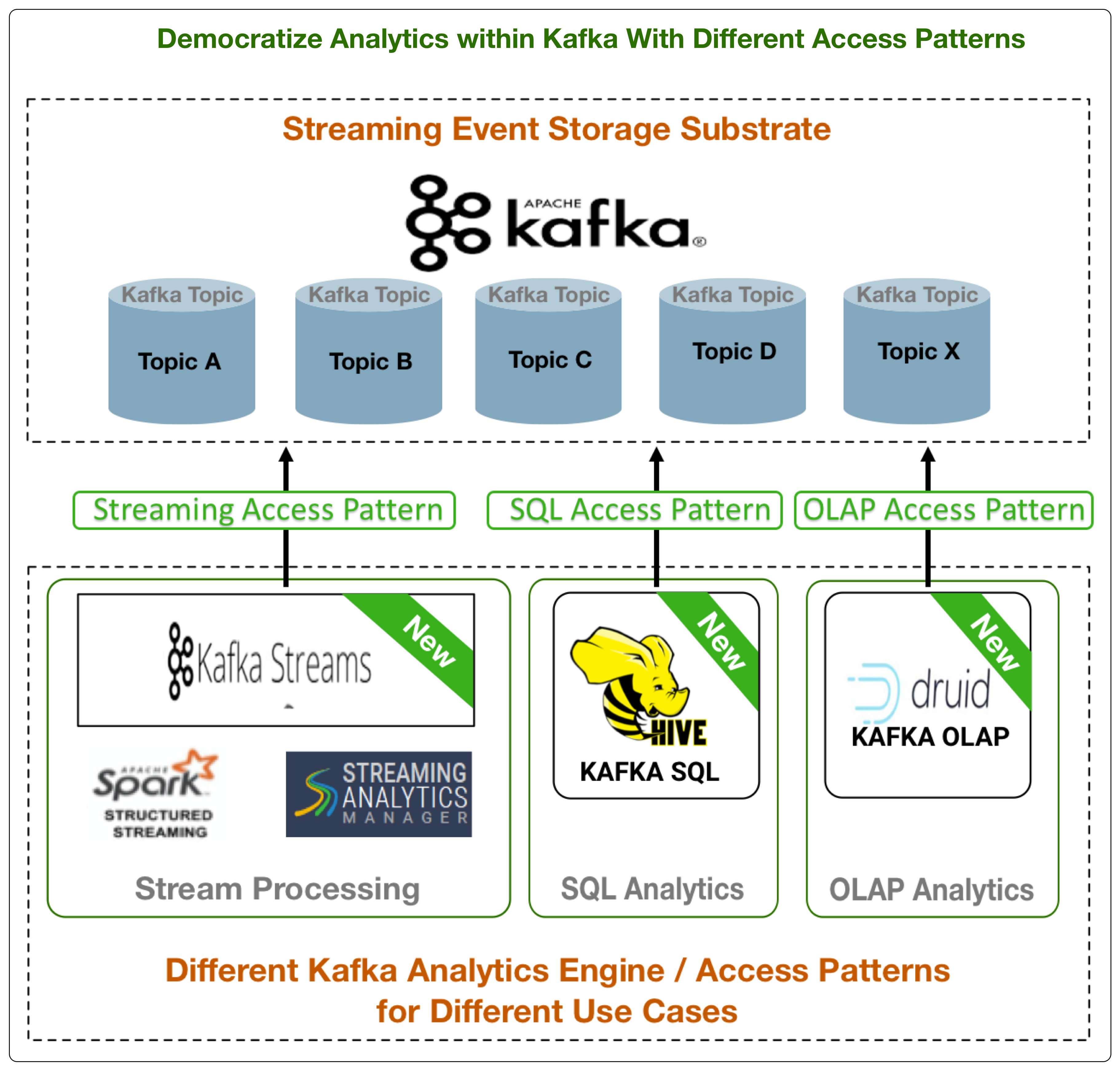
这三种新访问模式的摘要:
- 流处理:卡夫卡流支持-通过对 spark 流流、sam/storm 的现有支持, 卡夫卡流的补充为开发人员提供了更多的流处理和微服务需求选项。
- sql 分析:新的蜂巢卡存储处理程序-将卡夫卡主题作为表查看, 并通过 hive 执行 sql, 并提供完整的 sql 连接、窗口、聚合等支持。
- olap 分析:新德鲁伊卡索引服务-查看卡夫卡主题作为立方体, 并执行 olap 风格分析在卡夫卡流事件使用德鲁伊。
应用程序开发人员角色: 使用 hdp/hdf 卡夫卡流的安全和受管理的微服务
hdp/hdf 支持两个流处理引擎: 带有 storm 的火花结构化流和流分析管理器 (sam)。根据应用程序的非功能性需求, 我们的客户可以选择合适的流处理引擎来满足他们的需求。我们从客户那里听到的一些关键流处理要求如下:
- 选择适合其一组需求的流处理引擎非常重要。驱动引擎选择的关键非功能性需求包括批处理与事件实时处理、易用性、精确一次处理、处理延迟到达的数据、状态管理支持、可扩展性性能、成熟度等。
- 构建流式微服务应用时, 当前的两种选择功能有限。
- 所有流处理引擎都应使用一组集中的平台服务, 提供安全性 (身份验证/授权)、审核、治理、架构管理和监视功能。
为满足这些要求, 在即将发布的 hdp 3.1 和 hdf 3.3 版本中增加了对卡夫卡流的支持, 并与安全、治理、审计和架构管理平台服务完全集成
cheeli.com.cn/wp-content/uploads/2018/12/kafka-streams-addition.png “>
卡夫卡流集成了架构注册、地图集、游侠和流消息管理器 (smm), 现在为客户提供了一个全面的平台, 用于构建满足复杂安全、治理、审计和监控要求的微服务应用程序。
bi 角色: 实时流上的真实 sql
上面讨论的流处理引擎提供了对卡夫卡的编程流处理访问模式。应用程序开发人员喜欢这种访问模式, 但当您与 bi 开发人员交谈时, 他们的分析要求是完全不同的, 这些需求侧重于围绕临时分析、数据探索和趋势发现的用例。卡夫卡的 bi 角色要求包括:
- 把卡夫卡的话题/流当成桌子
- 支持 ansi sql
- 支持复杂联接 (不同的联接键、多路联接、非表键的联接谓词、非等联接、同一查询中的多个联接)
- udf 对可扩展性的支持
- 支持
- 为列屏蔽创建视图
- 丰富的 acl 支持, 包括列级安全性
为了满足这些要求, 即将发布的 hdp 3.1 版本将为卡夫卡添加一个新的 hive 存储处理程序, 允许用户将卡夫卡主题作为蜂巢表查看。这一新功能使 bi 开发人员能够充分利用 hive 分析操作功能, 包括复杂的联接、聚合、udf、推送谓词过滤、窗口等。
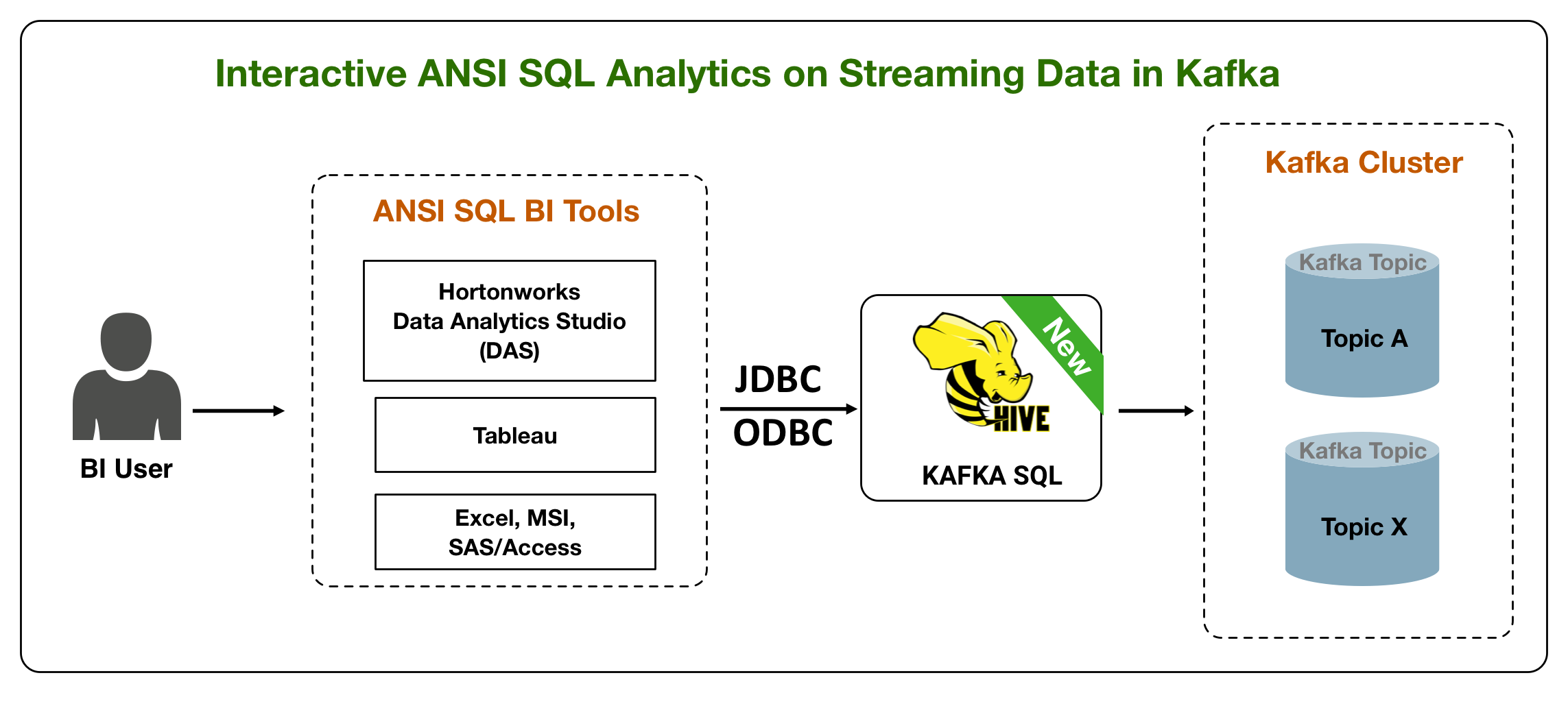
此外, 新的 hive 卡夫卡存储处理程序与 ranger 完全集成, 提供强大的功能, 如列级安全性。这是一个令人兴奋的新功能, 因为流媒体事件的列级安全性一直是卡夫卡最需要的功能之一。
卡夫卡 + 德鲁伊 + 蜂巢 = 卡夫卡数据流的强大新访问模式
新的 hive sql 对卡夫卡的访问将允许 bi 开发人员围绕数据探索、趋势发现和临时分析解决卡夫卡的一整套新用例。除了这些用例外, 客户还需要对卡夫卡中的流数据进行高性能 olap 样式分析。用户希望使用 sql 和交互式仪表板对卡夫卡中的流数据进行汇总和聚合。
为了满足这些要求, 我们将增加一个强大的新德鲁伊·卡夫卡夫卡夫指数服务, 由 hive 管理, 该服务将在即将发布的 hdp 3.1 版本中提供。
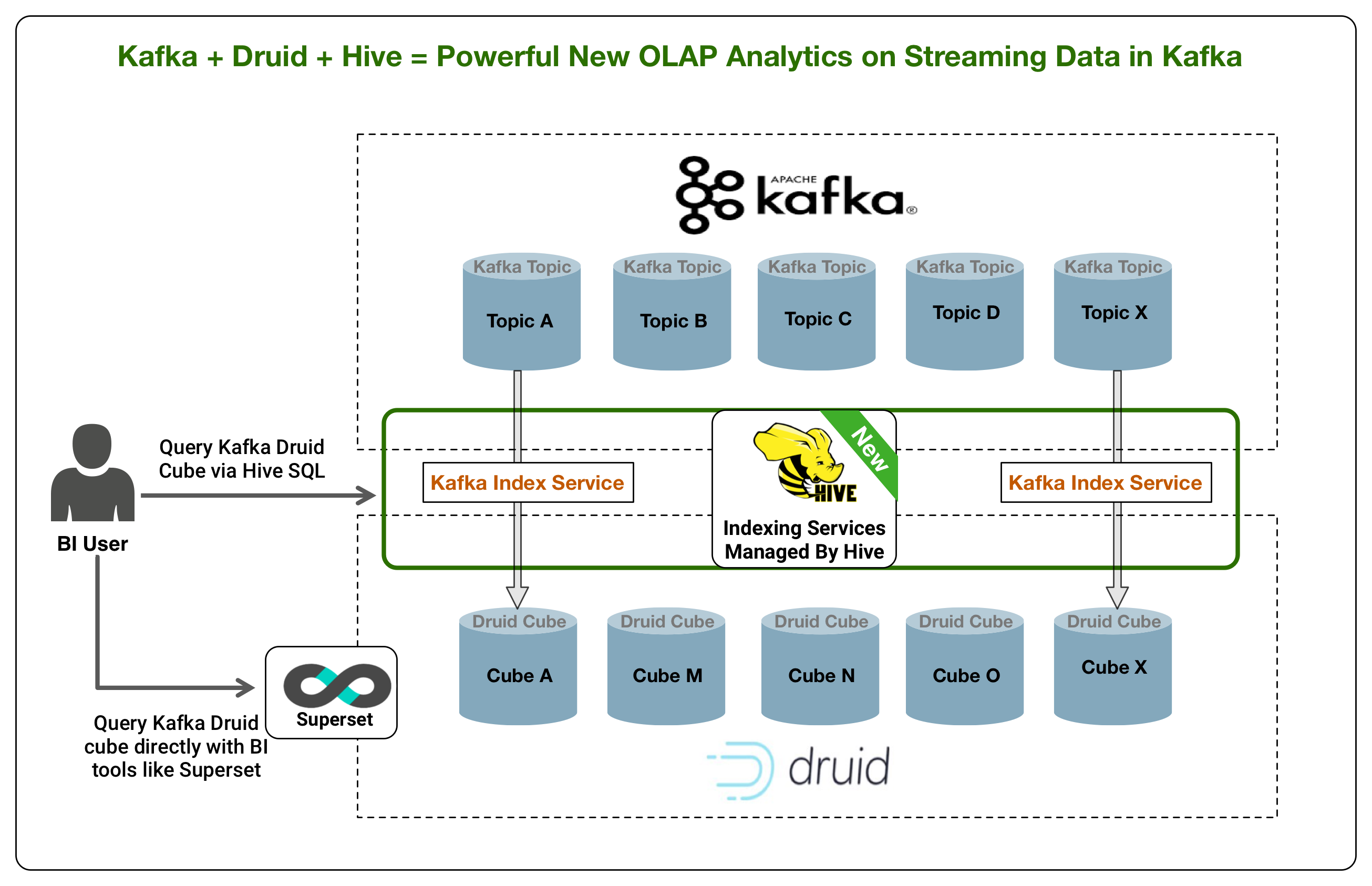
如上图所示, 卡夫卡主题可以被视为 olap 多维数据集。apache druid (孵化) 是一种高性能的分析数据存储, 用于事件驱动的数据。druid 结合了 olap/时间序列数据库和搜索系统的想法, 创建了一个统一的操作分析系统。新的集成提供了一个新的德鲁伊·卡夫卡索引服务, 该服务将卡夫卡主题中的流数据索引为德鲁伊立方体。索引服务可以由 hive 作为外部表进行管理, 该表为由卡夫卡主题支持的德鲁伊多维数据集提供 sql 接口。
下一步是什么?
此博客旨在让您偷看三种新的强大的卡夫卡分析访问模式, 这些模式将很快在 hdp 3.1 和 hdf 3.3 中提供。这将是卡夫卡分析博客系列的第一部分。本系列中的后续博客将更详细地浏览这些访问模式中的每一个。请继续关注!