
看看下面两个表格,您认为哪种格式更直观、更容易阅读?
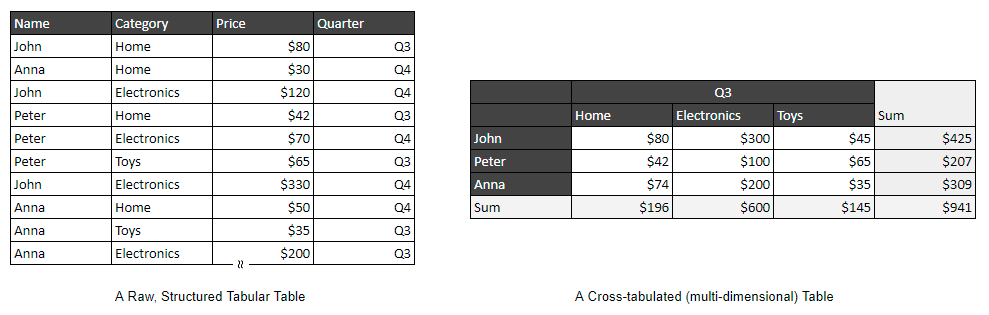
多年来,人们一直在使用电子表格软件来创建交叉表(或应急、多维)报告或填写表格。这些报告将类别、日期和其他数据点整齐地组织成行和列级别,使它们易于阅读和分析。
但是,每份报告仅代表基础数据的一个观点,例如一年中每个季度每个销售人员的总销售收入。为了展示收集的数据的另一个观点(例如,即2023年每个业务员每个季度的平均销售收入),然后我们必须创建一个新的报告或再次使用电子表格软件从头开始填写表格,这是繁琐且容易出错的。
数据透视表解决方案
为了解决静态交叉表报告的局限性,软件工程师 Pito Salas 引入了 1989 年 Lotus Improv 提出了数据透视表概念。数据透视表允许用户动态重组数据,使他们能够轻松地从不同角度查看报告。
数据透视表的先决条件
但是,使用数据透视表需要结构良好的表格样式源数据模型,这对于普通用户来说可能具有挑战性。与创建交叉表报告不同,设计此类数据模型需要工程培训,并且可能既耗时又复杂。
逆透视交叉表
为了释放交叉表数据的全部潜力,我们需要一种方法来快速分析现有的交叉表报告并将其转换为结构化表格样式数据模型用于进一步分析。这个过程称为“逆透视”,涉及将交叉表分成不同的部分,然后将它们重新组织成结构化格式。
通过识别和组织侧面标签、顶部标签和数字,我们可以创建一个结构化表格样式的数据模型,以更灵活的格式表示原始交叉表。
分步转换示例
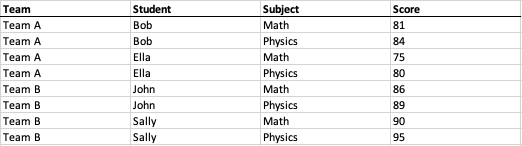
考虑一个简单的例子:一个专门为学生分数制作的电子表格交叉制表报告的布局如下。

学生被分成左列两队,科目在顶行,中央交叉矩阵区域是每个学生对应科目的分数。右端 E 列是每个学生总分的公式。底行(第 6 行)是所有学生每个科目的平均分数的公式。
为了将上述交叉表直线显示的报表转换为相应的结构化表格式源数据模型,我们必须首先将交叉表分成三部分,即侧标签、顶部标签和数字。

侧标签和顶部标签的每个级别对应于已解析的结构化表格样式数据模型的一个字段。数字本身也是结构化表格式数据模型的一个字段。
如上面的交叉表示例,“团队 A”和“团队 B”有一个“团队”字段(A 列),“Bob”、“Ella”有一个“学生”字段(B 列) “约翰”和“莎莉”,“数学”和“物理”的“科目”字段(第 1 行),以及每个相关学生和科目的每个对应数字的“分数”字段(区域 C2:D5) ;如以下解析的表格样式数据模型所示:
请注意,每个数字都与侧面标签和顶部标签的组合唯一关联,因此首先识别数字区域是最重要的。只要我们识别出号码区域,侧标签区域(号码区域左侧)和顶部标签区域(号码区域顶部)就很容易识别。
识别号码区域
要识别数字区域,最直接的方法是逐行扫描报表,选出带有数字的单元格,然后将这些单元格合并为区域。如示例所示,我们可以立即知道数字区域是C2:D5。但对于复杂的报表,可能还分散有其他号码,导致难以识别真正关注的号码区域。
另一种方法是利用汇总公式提供的信息。人们在报表中编写SUM或AVERAGE等聚合公式来汇总关注的实数,我们可以利用这些信息来定位数字区域。在示例交叉表报告的 E 列中,我们看到四个 SUM 公式引用了 C2:D2、C3:D3、C4:D4 和 C5:D5,它们合并为 C2:D5,帮助我们识别数字区域。在第 6 行中,我们看到两个引用 C2:C5 和 D2:D5 的 AVERAGE 公式,它们合并为 C2:D5,这使我们能够再次识别数字区域。
识别标签区域
我们得到数字区域后,从数字区域的左边框开始逐列扫描,直到没有列或空列即可找到侧标签;从数字区域的上边框开始逐行扫描,直到没有行或空行,找到顶部标签。
处理多级标签
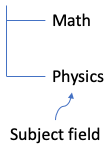
侧面标签和/或顶部标签可能有多个级别。它们各自自然地形成一棵从高级到低级的组树。每个级别都是已解析表格样式数据模型的一个字段。例如,示例中的侧标签形成一个组树,如下所示:

顶部标签(示例中只有一层)形成一个组树,如下所示:
 < /p>
< /p>
然后我们将两棵树合并并展开为一棵主树,并将相应的数字附加到路径中各侧面标签加上顶部标签的组合,如下图:

请注意,树的每个级别都与解析的表格样式数据模型中的一个字段相关联。现在,我们只需从根到叶遍历树并在每个关联字段中填写值即可:
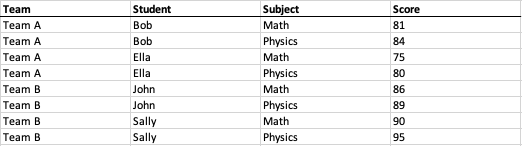
此时,我们已将交叉表转换为原始的结构化表格格式。
我很高兴分享这篇文章,因为我一直在为我的项目探索各种数据分析技术,ottava.io。我们最近实现了这种非旋转技术,我相信它也对其他开发人员有帮助。
通过将此方法纳入我们的平台,ottava.io 旨在简化数据分析和操作,无需手动准备数据或依赖 Power Query 或 Python 等高级工具Pandas 。我们的目标是简化流程并使用户能够更深入地研究数据以发现有价值的见解。我们非常欢迎您对此方法提供反馈和意见。