

数据湖的诞生
以关系数据库技术为中心的传统数据中心理念正在迅速发展。 大数据的采用正在导致 IT 行业的范式转变,这与 80 年代初关系数据库和 SQL 的发布相媲美。我们看到数据量空前激增。
这种增长是过去 10 年中创建的无数新数据源的结果。 机器传感器,从汽车到搅拌机、医疗设备、RFID 阅读器、Web 日志,尤其是社交媒体等,每天都会生成数 TB 的数据。 如果能够挖掘和分析这种新的”智能数据”,可以提供巨大的业务价值。
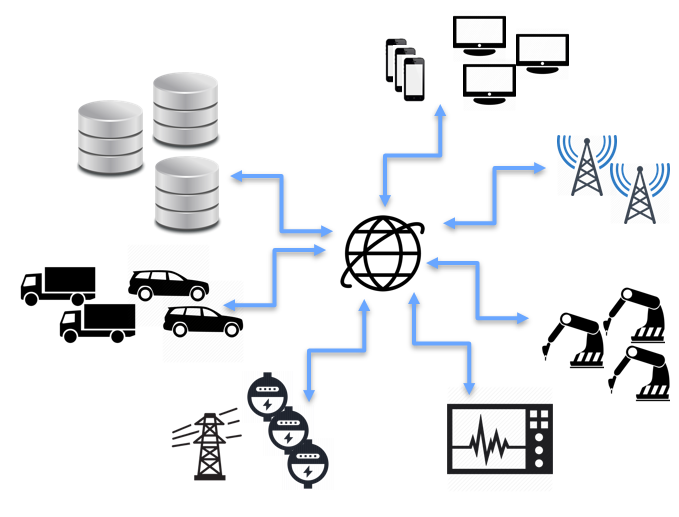
数据无处不在!
所有这些新数据的问题是,大部分数据是非结构化的。存储和分析它已远远超过传统的RDMS的容量。对于企业来说,面临的挑战是找到一种方法,将这些非结构化数据源与传统的业务数据(如客户和销售信息)合并。
这将提供客户购买习惯的 360 度视图。此外,它还可以帮助公司就如何增加业务做出更有针对性的战略决策。这种困境产生了数据湖的概念。数据湖本质上是原始数据的大保留区域。它们成本低,可扩展性强,能够支持非常大的数据量,并接受来自各种数据源的本机格式数据。
您可能还喜欢:
数据湖:中央数据存储。
选择的存储库主要是 Hadoop。Hadoop 允许您存储结构化和非结构化数据的组合。Hadoop 本质上是一个大规模并行文件系统,允许您及时处理大量数据。这些数据可以通过不同的方法进行分析,如MapReduce,Hive(SQL),以及最近的ApacheSpark。
典型的数据湖架构
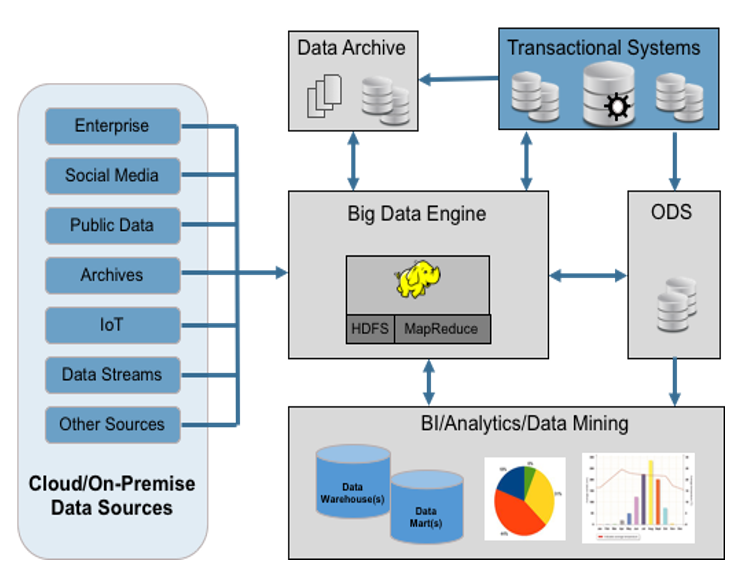
数据湖与数据仓库
了解数据湖和数据仓库之间的区别非常重要。数据仓库结构高度合理。在将数据加载到仓库之前,在开发架构和层次结构方面需要预先完成大量工作。数据湖中存储数据的方式没有层次结构或结构。之后将应用该结构。数据湖中的同一数据可以应用多个架构。
传统数据湖的不足
将所有数据源合并到公共存储库的概念给许多组织带来了挑战,而第一,它始终必须执行数据复制。主存储库必须与本地数据源保持同步。这通常需要运行大量 ETL 进程。
数据不一致的可能性很高另一个问题是,随着数据湖的增长,您可能有新的分析师组寻找不同的数据视图。 这导致不得不进行不必要的数据重复。
第三个,也可能是最大的挑战是数据安全和治理,以及新的 GDPR 法规限制数据位置。敏感数据不能移动到云中或集中式存储库中。它必须保留在其原生位置。这限制了您利用这些数据进行分析的能力。
数据虚拟化
数据虚拟化是克服集中式存储库缺点的解决方案。让我们首先了解什么是数据虚拟化。数据虚拟化是查看、访问和分析数据的能力,无需知道其位置。数据虚拟化可以跨多个数据类型和位置集成数据源。将其转换为单个逻辑视图,而无需执行任何类型的数据复制或移动。
查看有关数据虚拟化的简短视频。
数据虚拟化的优势:
- 通过提高数据准确性减少错误。
- 处理ETL后的资源消耗减少。
- 数据可以分类。
- 可以强制执行治理规则。
- 减少磁盘要求。
- 更易于跨组织共享数据。
数据虚拟化与联合
了解数据虚拟化和数据联合之间的区别非常重要。
数据联合是允许您从单个位置以逻辑方式映射远程数据源并针对这些多个源执行分布式查询的技术。数据虚拟化是一个平台,它让最终用户检索和操作数据,而无需他们了解有关数据的任何技术细节,例如数据的格式或物理位置。
它为最终用户提供了一个自助服务数据集市,该数据源可以联接到单个客户视图中。