

在本博客的两部分系列的第一部分中,我们深入探讨了旨在混合数据的数据洗牌技术,同时可以选择保留列之间的逻辑关系。在第二部分中,我们将重点介绍数据屏蔽技术,作为保证数据隐私的主要方法之一。
数据屏蔽
简而言之,屏蔽技术允许阻止特定字段或数据片段的可见性。它隐藏数据,同时保留整体格式和语义。它实际上在数据字段上应用了特定函数后,创建一个结构上相似但不真实的数据版本。
请注意,当使用最常用的技术进行数据屏蔽时,原始数据在被屏蔽后无法检索。尽管如此,仍然存在一些基于加密的算法,允许用户加密和解密数据,同时保留格式,我们将在本节的末尾看到。
在以下各节中,我们首先描述了用于隐藏数据片段的众多数据转换函数中的一些。然后,我们详细介绍了不同的掩蔽模式及其在运行时的影响。
您可能还喜欢:实际屏蔽数据 – 第 1 部分。
数据转换功能
为了屏蔽数据,可以在原始数据上应用大量的转换函数。让我们先来挖掘一下最常见的。此列表并非详尽无遗,并且可以轻松地应用其他转换来创建其他不真实的数据版本。
文本处理功能
下表列出了一些可用的文本掩蔽例程,例如,它们对值”2019 年的 Talend 非常出色”的影响。

数值处理函数
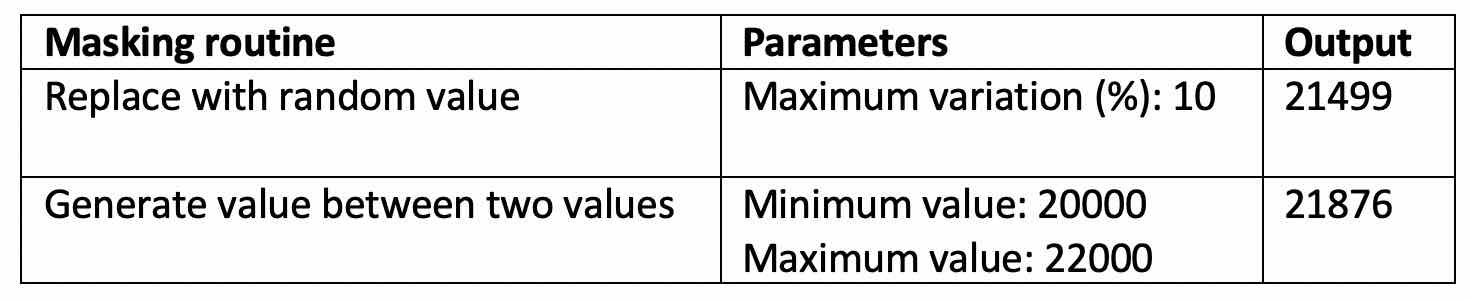
下表列出了包含数值的列的可用掩蔽例程,以及它们对值”21803″的影响。
日期处理功能
下表列出了包含日期值的列的可用掩蔽例程及其对值”05/04/2018″的影响。

模式处理功能
特定算法可用于屏蔽遵循特定模式的数据。这非常适合屏蔽记录,例如信用卡号、社会保险号 (SSN)、帐户 ID、IP 地址等结构化和标准化数据。
例如,如果我们想要屏蔽法国社会保险号,输入值由 15 个字符(不包括空格)组成,并使用模式”yy mm ll ooo kkk cc”,其中:
- s是性别:1 为男性,2 为女性
通过精确指定如何使用指定范围屏蔽哪些部件,可以一致地转换原始数据。例如,您可以指定:
- s 必须在 1 和 2 之间生成。
- yy 必须在 00 和 99 之间生成。
- 必须在 01 和 12 之间生成 mm,等等。
您还可以屏蔽输入的特定部分,并保留其他部分的蒙版。例如,您可能希望屏蔽除第一个字符之外的所有 SSN 字符。这将允许保持性别的真实统计数据(由第一个字符表示),保持真实人物的匿名性——其他字符被完全遮盖。
当然,相同的行为可以应用于专用数据类型,如电子邮件、电话号码、地址等。
屏蔽模式和运行时行为
屏蔽数据时,除了用于转换数据的技术例程外,另一个组件也是关键。它涉及掩蔽模式和函数在运行时的行为。
根据目标用例,数据屏蔽例程可以纯粹是随机的。但它们也可以在同一数据集上从一个执行到另一个执行重复。这打开了巨大的视角,特别是允许对屏蔽数据进行联接和查找。让我们深入探讨一下…
随机数据屏蔽
随机掩蔽包括用随机生成的值屏蔽输入值。因此,当输入数据集中出现多个相同值时,可以将其屏蔽为不同的值。反之亦然,输入数据集的不同值可以屏蔽为相同的值。
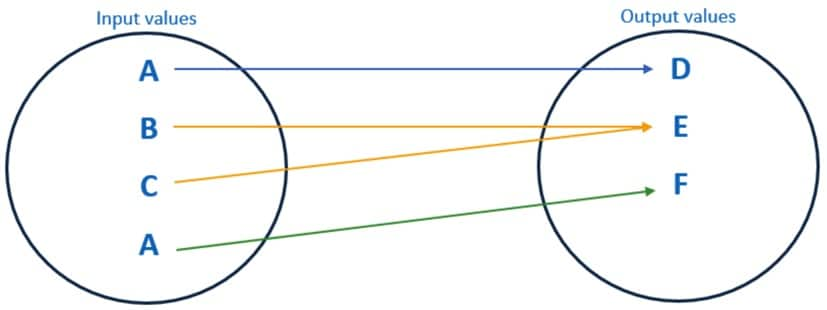
例如,下图显示了纯随机数据屏蔽的示例:
- 当 A 值首次出现在输入数据集中时,该值被蒙版为 D。
- B 和 C 值被屏蔽为 E。
- 当 A 值第二次出现在输入数据集中时,该值被屏蔽为 F。
下表显示了使用”替换 n 个第一个字符”函数生成的屏蔽值的示例:

此处,两个输入值相同。屏蔽后,输出值将完全不同。”新用户”在第一次出现时被”u_ser”掩盖,在第二次出现时被”_zoser”掩盖。
下表显示了从法国 SSN 编号生成的屏蔽值的示例:

同样,两个输入值相同。屏蔽后,相应的输出值将完全不同。”1 90 04 94 184 376 21″在第一次发生时被”2 59 04 592 221 47 22″所掩盖,在第二次发生时被”2 73 03 64 078 284 70″所掩盖
一致的数据屏蔽
当相同的值出现在输入数据中两次时,一致的掩蔽函数将输出相同的屏蔽值。但是,两个不同的输入值可以替换为输出中的相同屏蔽值。
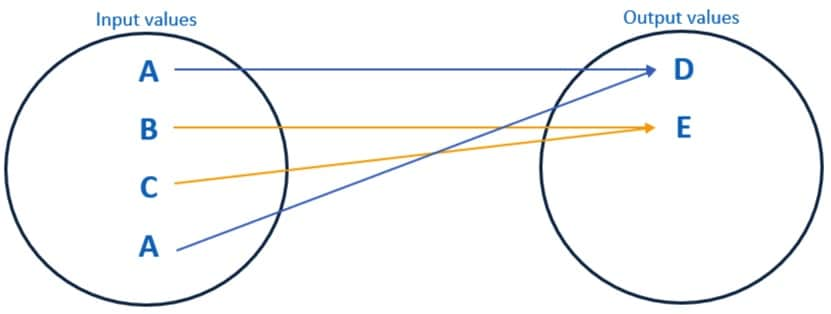
例如,下图显示了一致掩蔽的示例:
- 无论输入数据集中出现的次数如何,A 值都屏蔽为 D。
- B 和 C 值被屏蔽为 E。
下表显示了使用具有一致项函数的”屏蔽域左侧部分”生成的屏蔽值的示例(即用额外参数列表中设置的项之一替换左侧部分域):
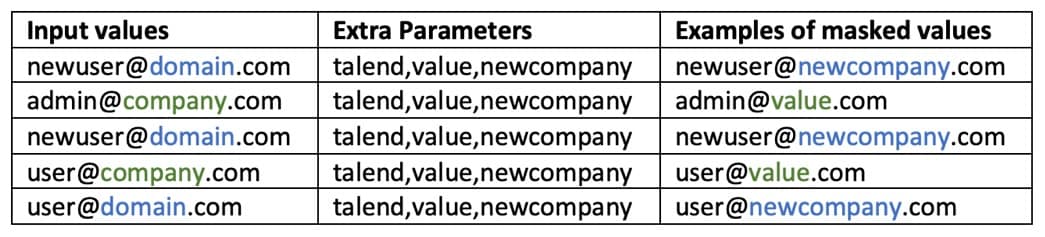
在这里,相同的输入值始终被完全相同的输出值屏蔽:”域”始终被”新公司”屏蔽,”公司”始终被”值”掩盖。
一致的数据屏蔽可以看作是Bijective数据屏蔽之前的第一步。
Bijective 数据屏蔽
Bijective 掩蔽函数具有以下特征:
- 它们是一致的掩蔽函数。
- 它们始终为两个不同的输入值输出两个不同的屏蔽值。
例如,下图显示了双向掩蔽的示例:
- 无论输入数据集中出现的次数如何,A 值都屏蔽为 D。
- B 值被屏蔽为 E。
- C 值被屏蔽为 F。
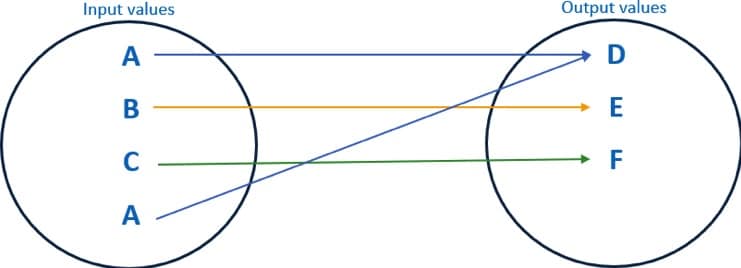
下表显示了从法国 SSN 编号生成的屏蔽值的示例:

在这里,相同的输入值始终被完全相同的输出值屏蔽:”1 90 04 94 184 376 21″始终被”2 89 05 24 283 319 01″所掩盖。
如果需要确保初始值和屏蔽值之间的一对一对应关系,Bijective 数据屏蔽非常适合。正如我们在下一节中将看到的,如果您的目标是加入/查找多个屏蔽数据集,同时保持正确的关系,则此属性是关键。
可重复数据屏蔽
可重复掩蔽允许保持作业执行之间的一致性。定义种子,因此,对于给定的输入值和种子值组合,将生成相同的输出屏蔽值。
结合双向数据屏蔽和可重复数据屏蔽具有非常强大的特性。特别是它允许用户基于已屏蔽的键加入不同的数据集。
假设您希望在保险和医疗保健数据库上执行商业智能,但我们没有明确同意直接访问这些数据。一旦洗牌和屏蔽,我们仍可能对数据执行一些统计信息。
由于我们必须同时加入这两个数据库,因此我们更需要确保用于使联接的数据在任何地方都以完全相同的方式屏蔽
格式保留加密 (FPE)
格式保留加密算法是保存输入值格式的加密算法。这些算法需要指定密钥才能生成唯一的屏蔽值。
由于这些方法基于加密,因此存在以下几个优点:
- 加密后,可以解密数据,这意味着可以解密输出值(当然知道密钥)。然后,这样的掩蔽函数是可逆的 – 您可以检索原始输入数据。
- 它原生地意味着双可操作性和可重复性。
FF1算法是NIST标准的格式保留加密算法。
结论
我们看到一些技术有助于确保数据隐私。在这里,关键是,没有一个简单的神奇解决方案,可以解决您的整个数据隐私问题。
根据您正在处理的数据类型和要解决的用例,某些技术比其他技术更相关。混合了不同的技术,如数据洗牌,带有一些可重复的数据掩蔽和一小撮哈希,通常是正确处理此类复杂数据隐私项目的正确途径。
好消息是,Talend Data Fabric提供了所有这些不同的技术资源,可帮助您满足数据隐私需求!