

对于公司来说,保护敏感数据可能是一项具有挑战性的任务。在数据隐私法规不断变化的互联世界中,一些技术公司为遵守最新要求提供了强大的解决方案,例如美国的《加利福尼亚州消费者隐私法案》(CCPA)或欧洲一般数据保护条例 (GDPR)。
在这个由两部分组成的博客系列中,我们旨在探讨一些技术,使您能够有选择地在整个组织中共享生产质量数据,以便进行开发、分析等,而无需公开个人身份信息 (PII) 给无权查看信息的人员。
您可能还喜欢:实际屏蔽数据 – 第 1 部分。
为了保证数据隐私,存在多种方法,尤其是以下四种方法:
选择其中一个(或混合组)主要取决于您正在处理的数据类型和您拥有的功能需求。关于加密和哈希技术,已经有大量的文献可供使用。在这个由两部分组成的系列的第一部分中,我们将深入探讨数据洗牌技术。我们将在第二部分中介绍数据屏蔽。
数据洗牌
简而言之,洗牌技术旨在混合数据,并可以选择保留列之间的逻辑关系。它随机从属性中的数据集(例如纯平面格式的列)或一组属性(例如一组列)中随机排列数据。您可以随机排列敏感信息,将其替换为不同记录中同一属性的其他值。
这些技术通常非常适合分析用例,确保在整个数据集上计算的任何指标或 KPI 仍然完全有效。然后,它允许将生产数据安全地用于测试和培训等目的,因为所有统计信息分发都保持有效。
一个典型的用例是生成”测试数据”,即需要将数据看起来像实际生产数据作为新项目的输入(例如,对于新环境),但保证匿名,同时确保数据统计信息保持不变。
随机洗牌
让我们看一下第一个简单的示例,其中我们要随机排列下面的数据集。

通过应用随机洗牌算法,我们可以获得:

电话和国家/地区的不同字段已正确混合,因为所有列之间的原始链接已完全丢失例如,电话前缀在同一国家/地区内有所不同,并且国家/地区不再与名称正确配对。
此方法非常适合,并且可能就足够了,如果您需要统计信息分布仅保持每列的有效。如果需要保持列之间的一致性,可以使用特定的组和分区设置。
指定组
组可以帮助保留同一行中字段之间的值关联。属于同一组的列将链接,其值将一起随机排列。通过分组电话和国家/地区列,我们可以获得:

洗牌过程后,电话和国家/地区列中的值仍会关联。但是,名字和国家之间的联系已经完全丧失。
此方法非常适合,如果您需要在某些属性之间保持功能交叉依赖关系,可能就足够了。根据定义,主要缺点是分组列不会在它们之间随机排列,这样您就可以访问某些初始关系。
指定分区
分区可以帮助保留列之间的依赖关系。数据在分区内随机排列,并且来自不同分区的值永远不会关联。
通过为特定国家/地区创建分区,我们可以获得:
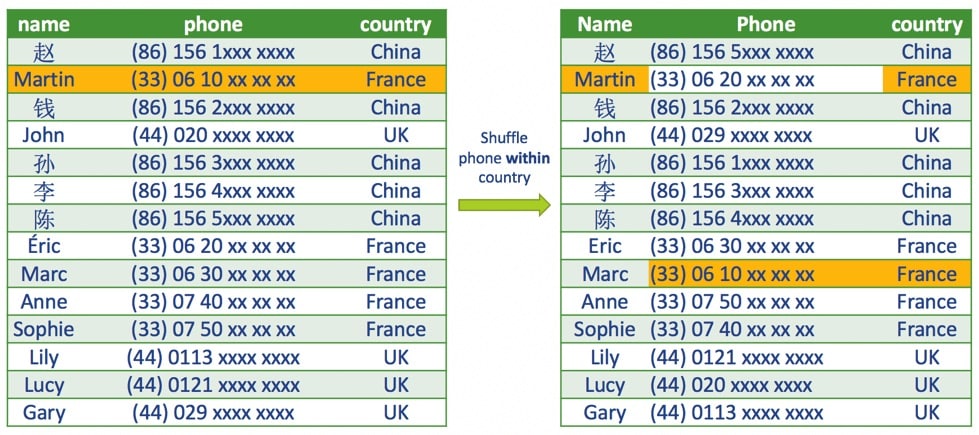
此处,名称列保持不变。电话列已在每个分区(国家/地区)内随机排列。名字和电话现在与这个国家一致。
换句话说,此洗牌过程仅适用于共享国家/地区列相同值的行。
输入数据中的敏感个人信息已被洗牌,但数据看起来仍然真实且一致。随机播放的数据仍可用于生产以外的用途。
此方法非常适合,如果您需要在某些属性中保留功能依赖项,可能就足够了。根据定义,主要缺点是来自不同分区的值永远不会关联,这允许您访问某些初始关系。
作为提醒,洗牌算法从列或一组列中的数据集随机洗牌数据。组和分区可用于保持列之间的逻辑关系:
- 使用组时,列将一起随机排列,并且同一行中的值始终关联。
- 使用分区时,数据在分区内随机排列;来自不同分区的值永远不会关联。
洗牌技术可能看起来像分析用例的神奇解决方案。小心。由于数据本身没有更改,因此有时可能无法使用纯统计推理来返回一些原始值。
- 以具有法国城市人口数据集并要对该数据集执行数据洗牌为例。由于您在巴黎拥有约 250 万个人,而巴黎是法国最大的城市,因此在洗牌后,您会发生与原始值一样多的事件。它将允许轻松地”取消洗牌”这个特定值,并检索原来的。
- 更糟糕的是 , 以单个值表示数据集 50% 以上为例
关于数据隐私技术的两部分系列的第一部分就到此结束。请继续关注第二部分,我们将详细讨论数据屏蔽技术,作为数据隐私的有效措施,并通过 Talend 数据结构获得的关键工具。