
业务人员利用公开数据或公司数据库中的数据进行决策。然而,当需要内部数据时,大多数人缺乏 SQL、Cypher 或其他数据库特定语言的专业知识。这就造成了数据分析师之间的差距,他们充当企业到数据库的解释者,将人类的问题翻译成数据库可以理解的语言。
如今,大型语言模型 (LLM) 就像GPT 或 Mistral 可以完成数据分析师执行的一些任务。例如,法学硕士可以:
- 了解各种语言(例如英语、西班牙语、中文)的用户查询。
- 根据这些问题生成 SQL 查询。
- 使用工具和 API 对数据库执行这些 SQL 查询以检索相关业务数据。
在本文中,我将引导您完成使用 DBeaver 创建 AI 数据分析师的步骤。您会发现,在您的团队中“加入”一名初级人工智能专家已经非常简单,他可以充当业务人员和数据库之间的解释者,从而使人类数据分析师能够专注于更复杂的任务。
探索 DBeaver 中的 AI 聊天
如果您经常使用数据,那么 DBeaver 应该是 no对你来说很陌生。它是一种流行的工具,可以连接到数百个数据库,允许您查询或操作数据。该工具供开发人员、管理员、分析师和所有处理数据的人使用。
DBeaver 拥有广泛的版本、功能和扩展生态系统,使其成为适用于各种用例的多功能工具。 人工智能聊天 是其最新功能之一。借助 AI Chat,您可以用简单的英语输入问题,然后让 DBeaver 生成 SQL 请求,然后通过数据库执行 SQL 请求。
正如您所猜测的,AI 聊天是 AI 数据分析师的一项基本功能。因此,让我们尝试一下。
我将 DBeaver 连接到我的 YugabyteDB 数据库集群,该集群存储 Netflix 数据集,包含超过 8800 部电影和节目:

接下来,为了启用 AI 聊天,我跳转到窗口 -> 首选项 -> AI (GPT) 并配置了以下设置:
选中启用智能完成框以激活 DBeaver 的 AI 功能
注意:我使用的是 DBeaver Enterprise Edition,它内置了对 AI 的支持。如果您使用的是 DBeaver Community Edition,则需要 首先安装 AI (GPT) 扩展。
应用配置设置后,我打开了 AI 聊天并允许与 OpenAI 共享数据库元数据(表和列名称)。

通过与 LLM 共享元数据,您可以有效地将 AI 分析师“加入”您的团队。分析师将通过分析元数据来了解现有的表、列及其依赖关系。
最后,我通过提出以下问题来测试聊天界面:
- 我们大部分动作片是在哪几年发行的?为我争取前三年。
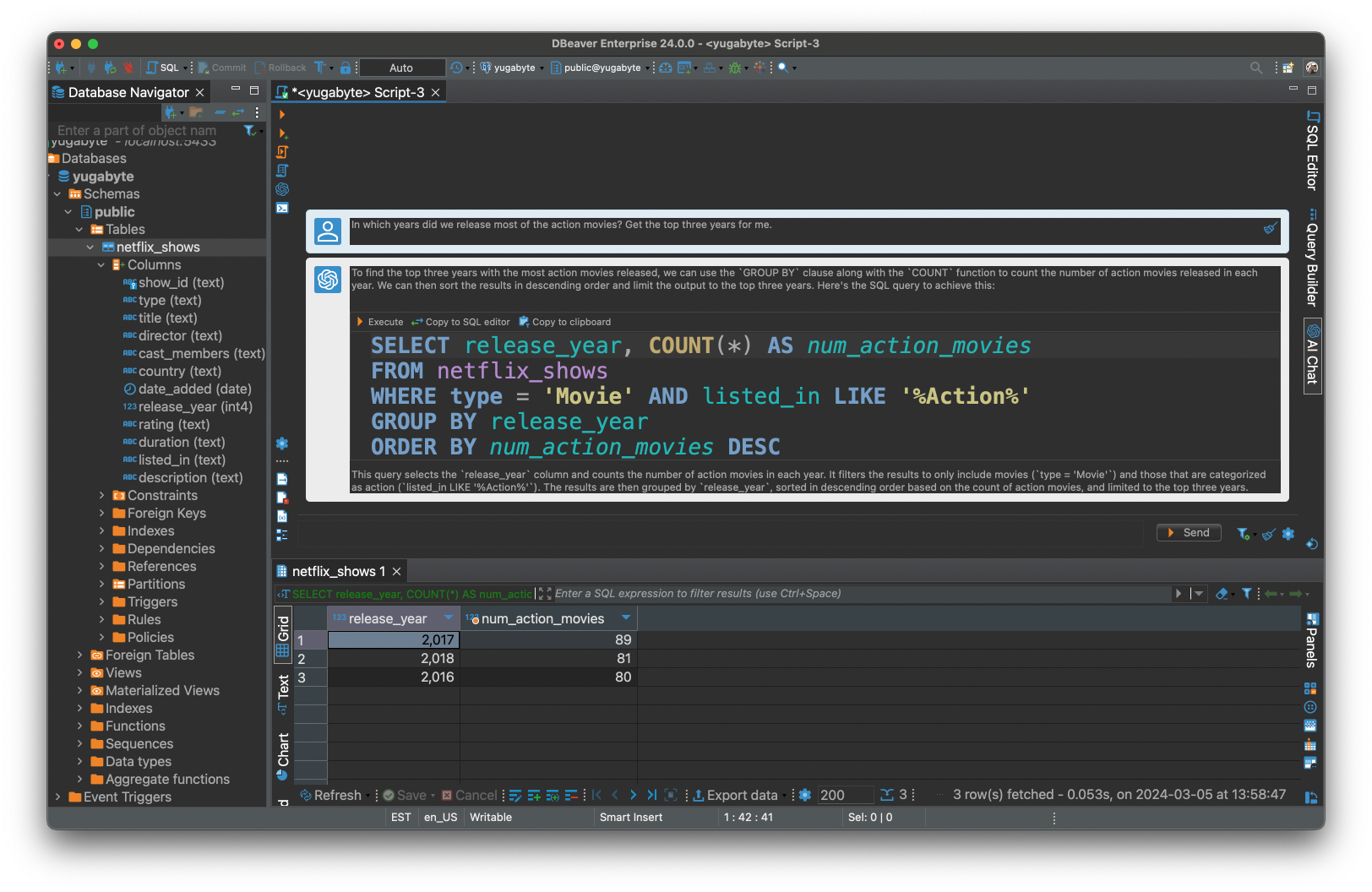
OpenAI GPT 模型使用 PostgreSQL 方言成功生成了有效的 SQL 请求(识别 YugabyteDB是Postgres的分布式版本),然后DBeaver帮我检索了数据。
设置 AI 数据分析师角色
DBeaver 的 AI Chat 界面将成为业务用户和 AI 数据分析师之间的沟通渠道。然而,仅拥有聊天功能是不够的。我希望人工智能能够在没有我持续监督的情况下自主工作。为了实现这一点,我首先需要创建一个具有一组精细权限的角色,其次,可以了解人工智能生成的查询(如果我想与人工智能分享更多知识或微调其)行为)。
我设法使用 DBeaver 生态系统 Team Edition 中的另一个解决方案来满足这两个要求,这是一种用于团队合作的高级数据管理工具。使用 Team Edition,您可以为 AI 数据分析师配置角色并监控其行为。
首先,我安装了 Team Edition 服务器 在我本地的 Docker 环境中。您需要服务器来管理用户级别的数据访问,并密切关注数据在团队中的使用方式。

接下来,我创建了 Netflix 流媒体平台项目,该项目将与 AI 分析师共享:

之后,我跳转到访问管理菜单并创建ai_analyst角色:
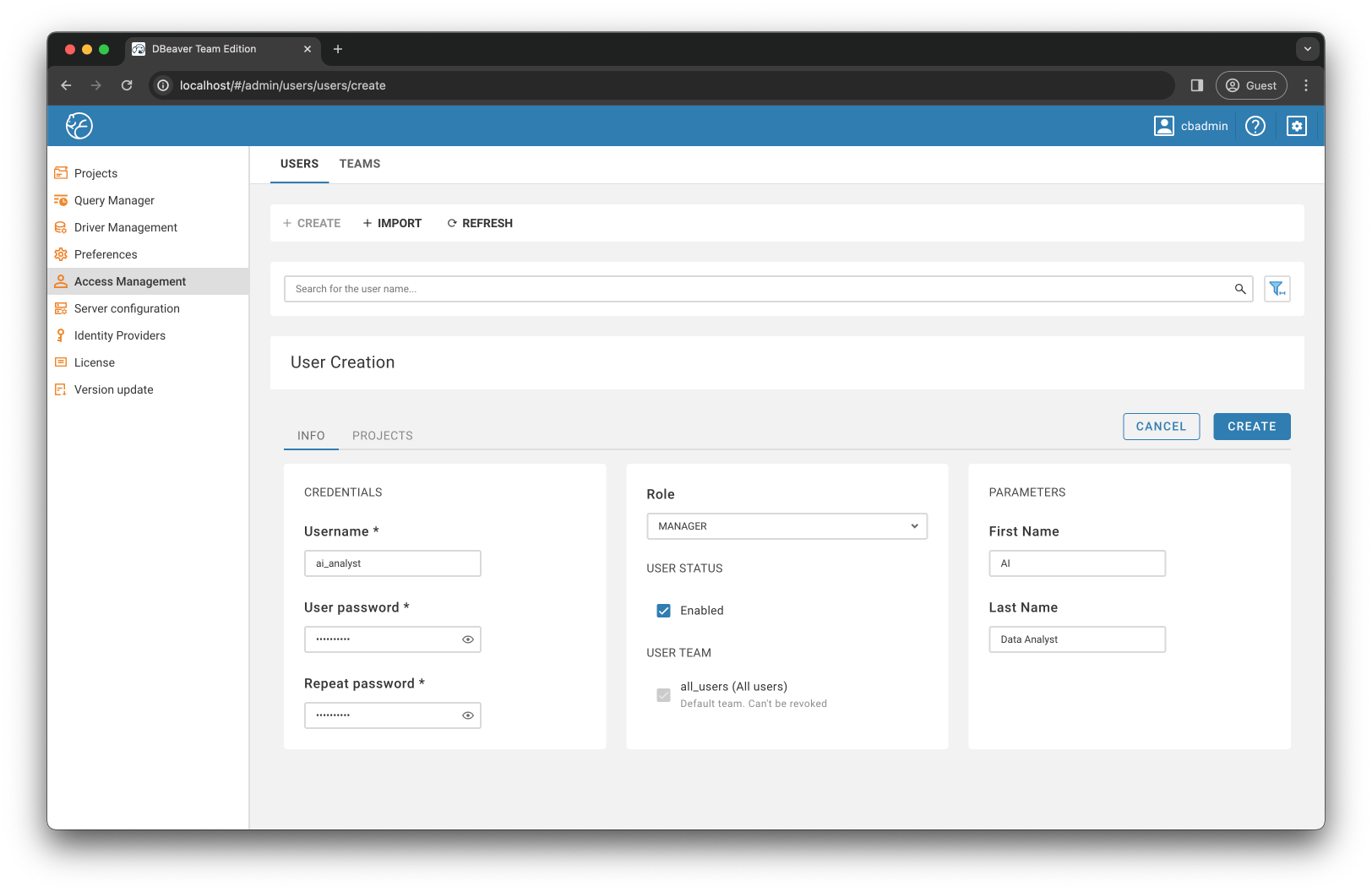
团队版支持各种角色,适合具有不同技能和职责的团队成员。我为 AI 分析师选择了经理角色,因为该角色适合精通 SQL 查询编写并需要直接访问数据库的专家。
创建角色后,我授予其访问 Netflix Streaming Platform 项目的权限:

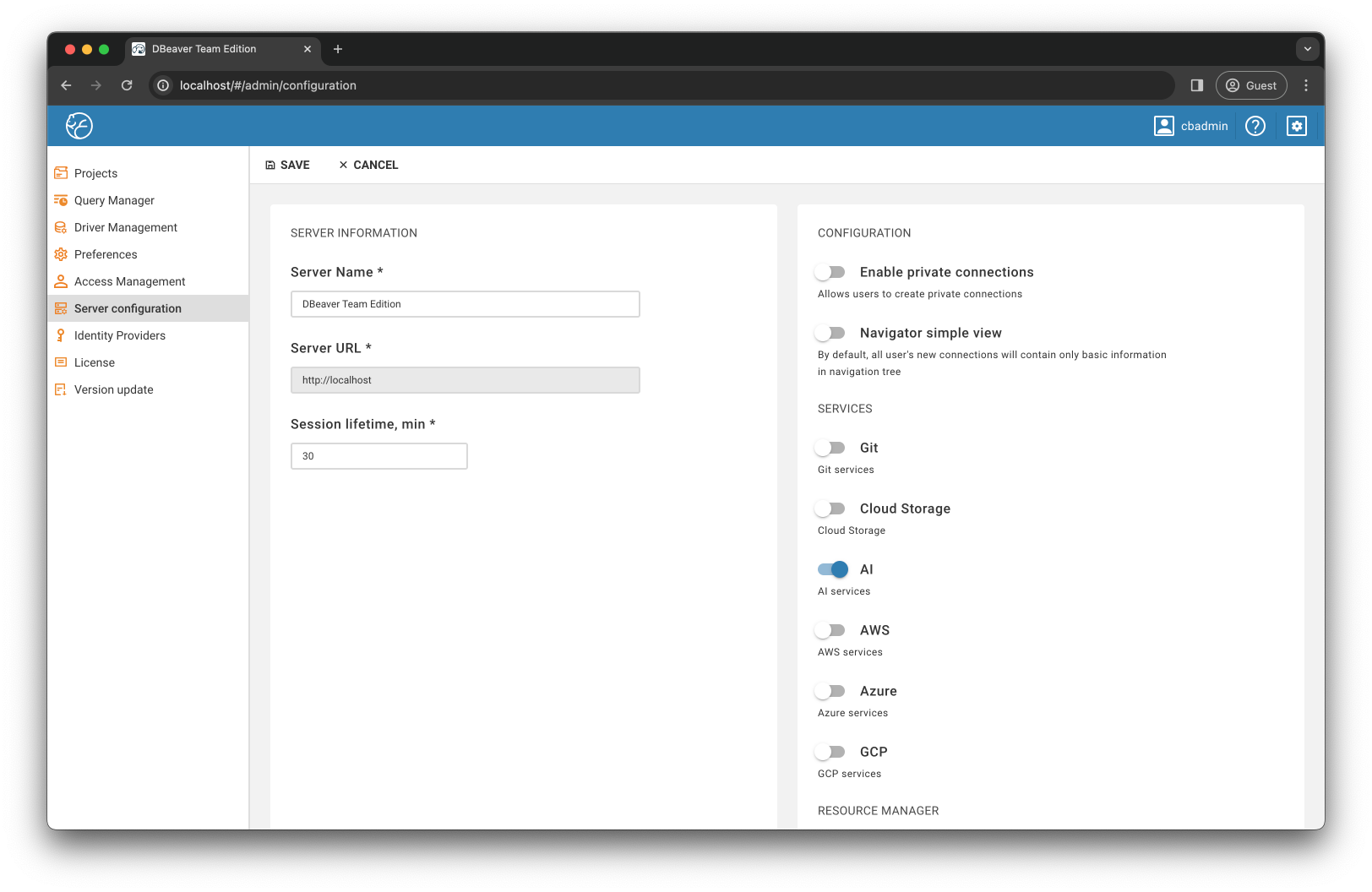
下一步,我在服务器端配置了 AI 相关设置:
- 启用AI 服务:
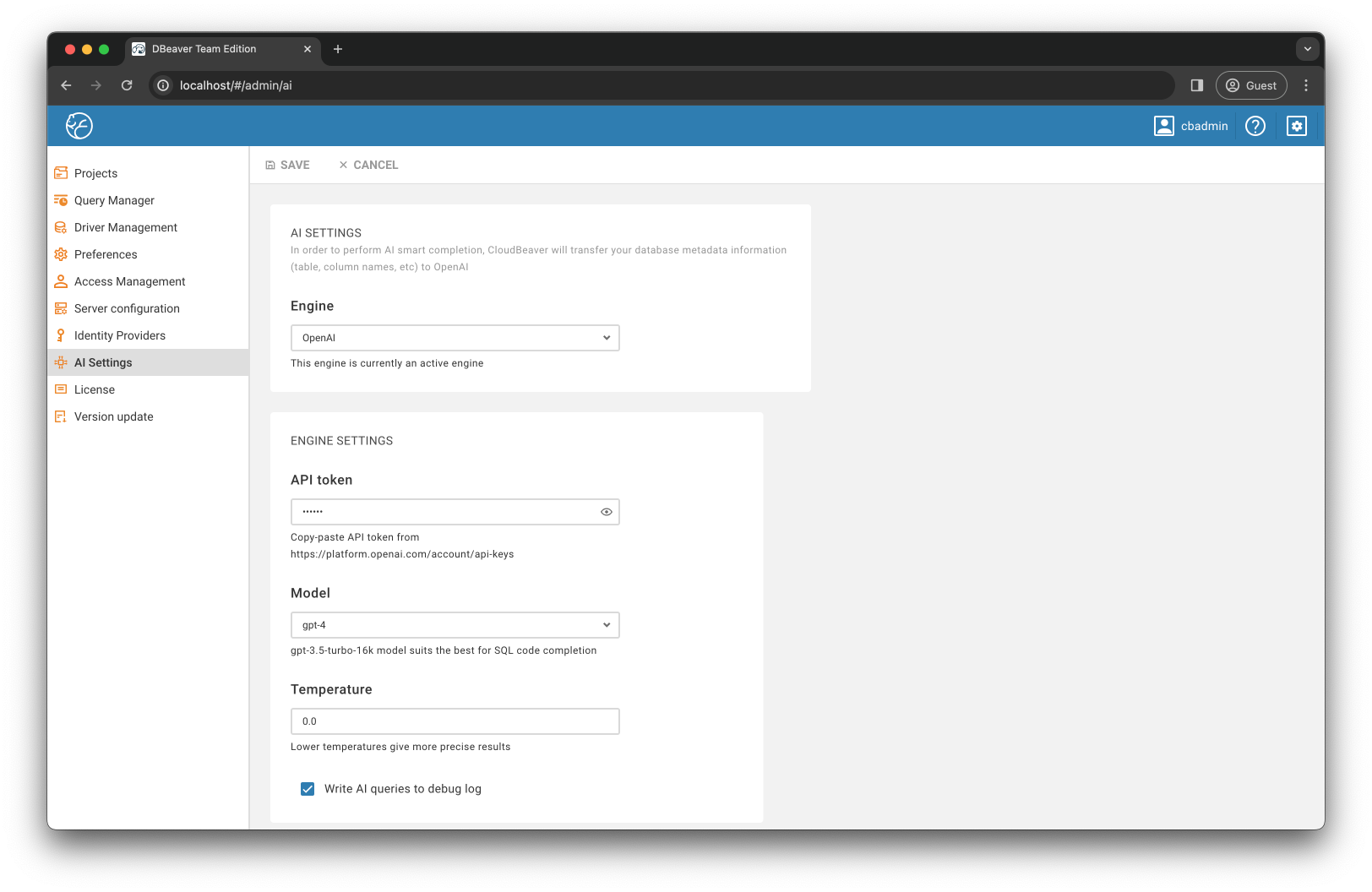
- 选择了具有模型的 LLM 提供商,并提供了我的 API 密钥:

然后,我通过向 Netflix Streaming Platform 项目添加 YugabyteDB 连接来完成 Team Edition 端配置,这将允许 AI 数据分析师直接使用指定的连接访问数据库。< /p>
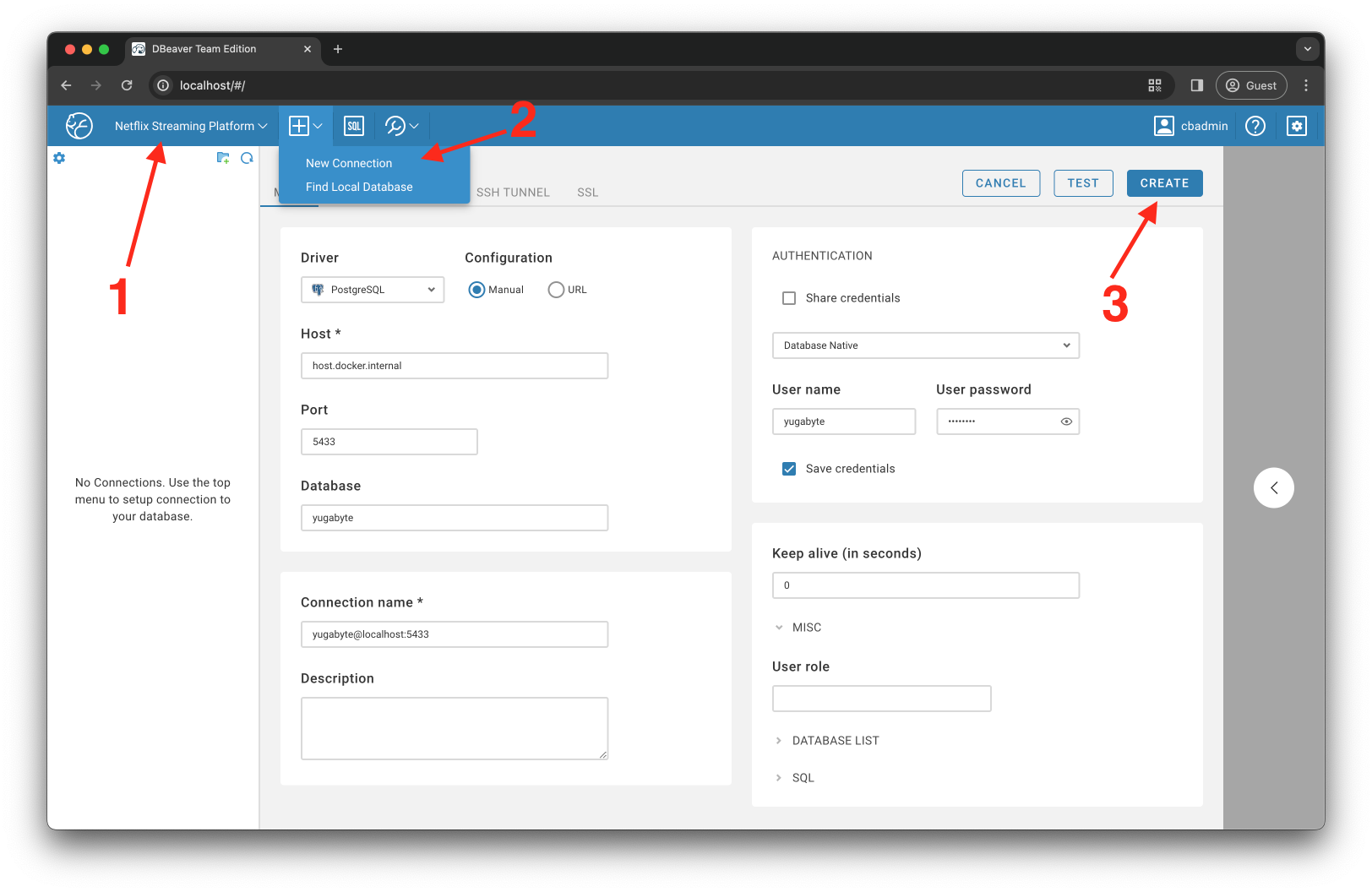
最后,我使用这个新的数据库连接在数据库级别创建了一个只读 ai_analyst 角色:
此数据库级角色与我们之前使用 Team Edition 创建的角色有何不同?两种角色都有不同的目的:
- Team Edition 级角色用于向 Team Edition 服务器进行身份验证并获取对预定义项目、连接和数据集列表的访问权限。业务用户将使用此角色通过登录 DBeaver Team Edition 客户端(如下所述)并通过 AI 聊天界面提问来“激活”AI 分析师。
- 数据库级角色用于控制允许 AI 分析师对数据库执行的查询类型。为了响应用户提示,人工智能分析师可能会生成可以修改数据的查询。创建的角色确保 AI 只能选择数据,而不能对数据库对象执行任何操作。
使用 AI 数据分析师完成工作
业务用户将通过 团队版桌面客户端。让我们来探索一下这种体验是什么样的。
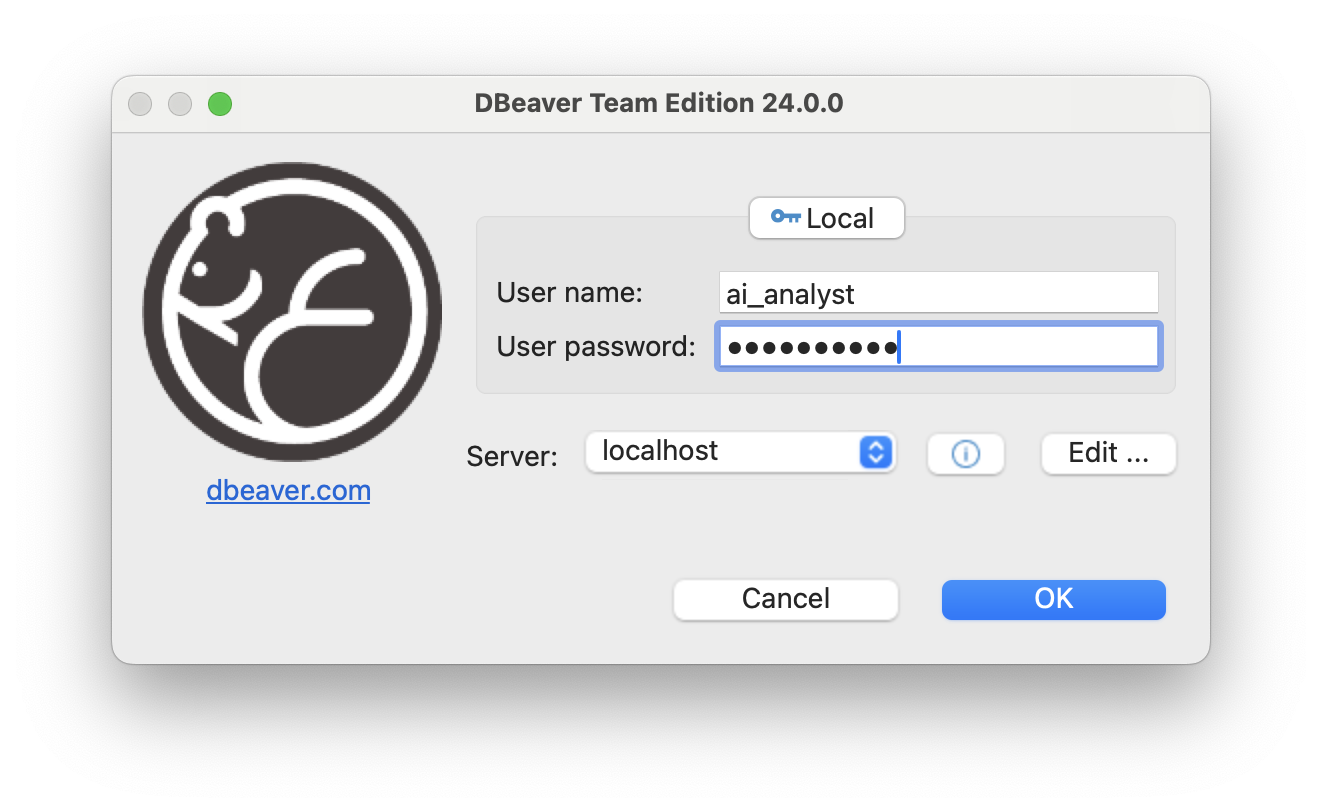
安装桌面客户端后,我通过使用分析师的角色登录来“激活”分析师:
- 使用 ai_analyst 角色通过 Team Edition 服务器进行身份验证。

- 接下来,我使用只读数据库级角色连接到数据库。

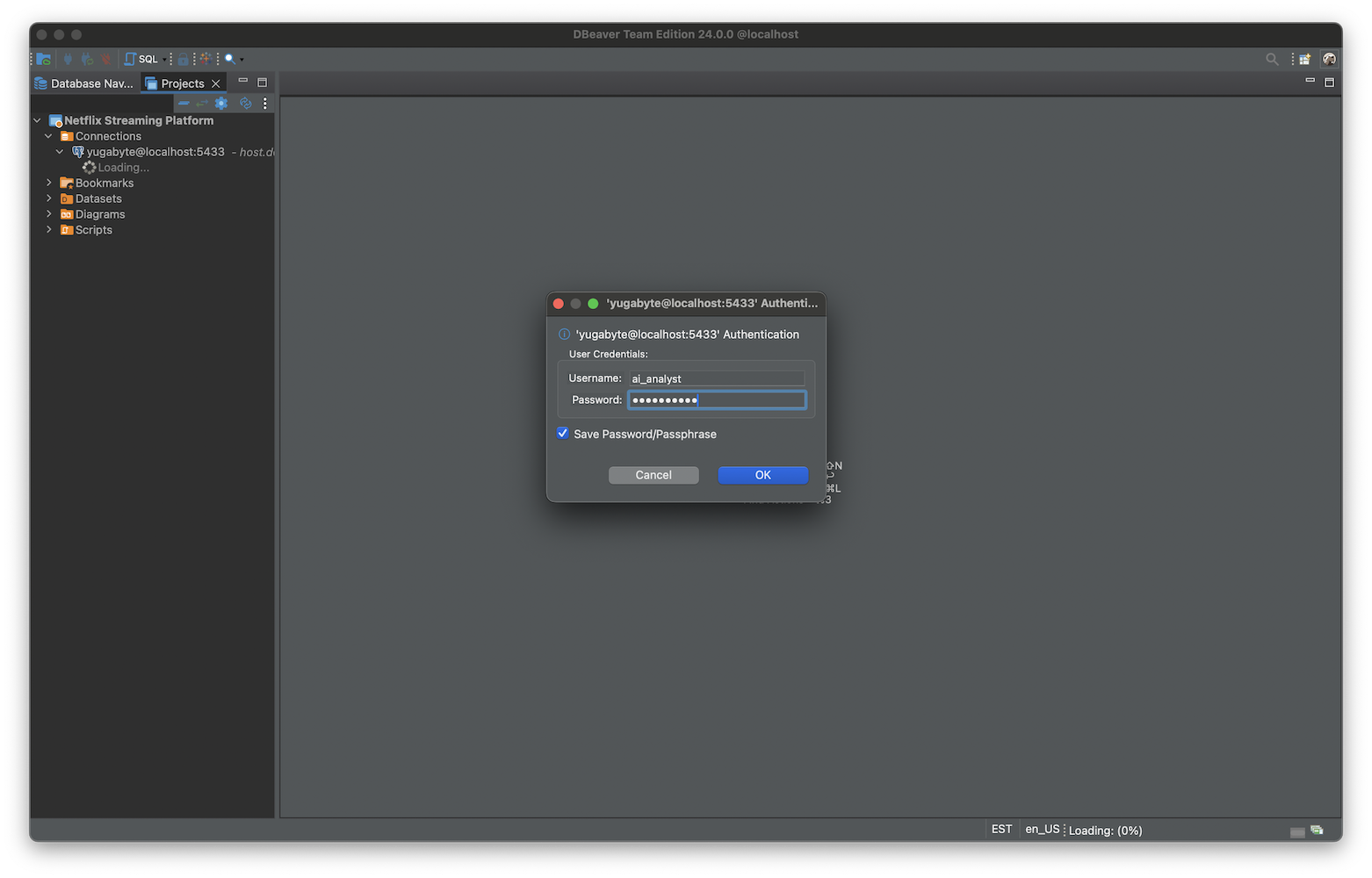
之后,我前往 AI Chat 界面,请 AI 分析师回答我以下问题:
- 我们大部分动作片是在哪几年发行的?为我争取前三年。
- 亚当·桑德勒主演了哪些电影?
- 我需要知道这些电影的类别和上映日期。
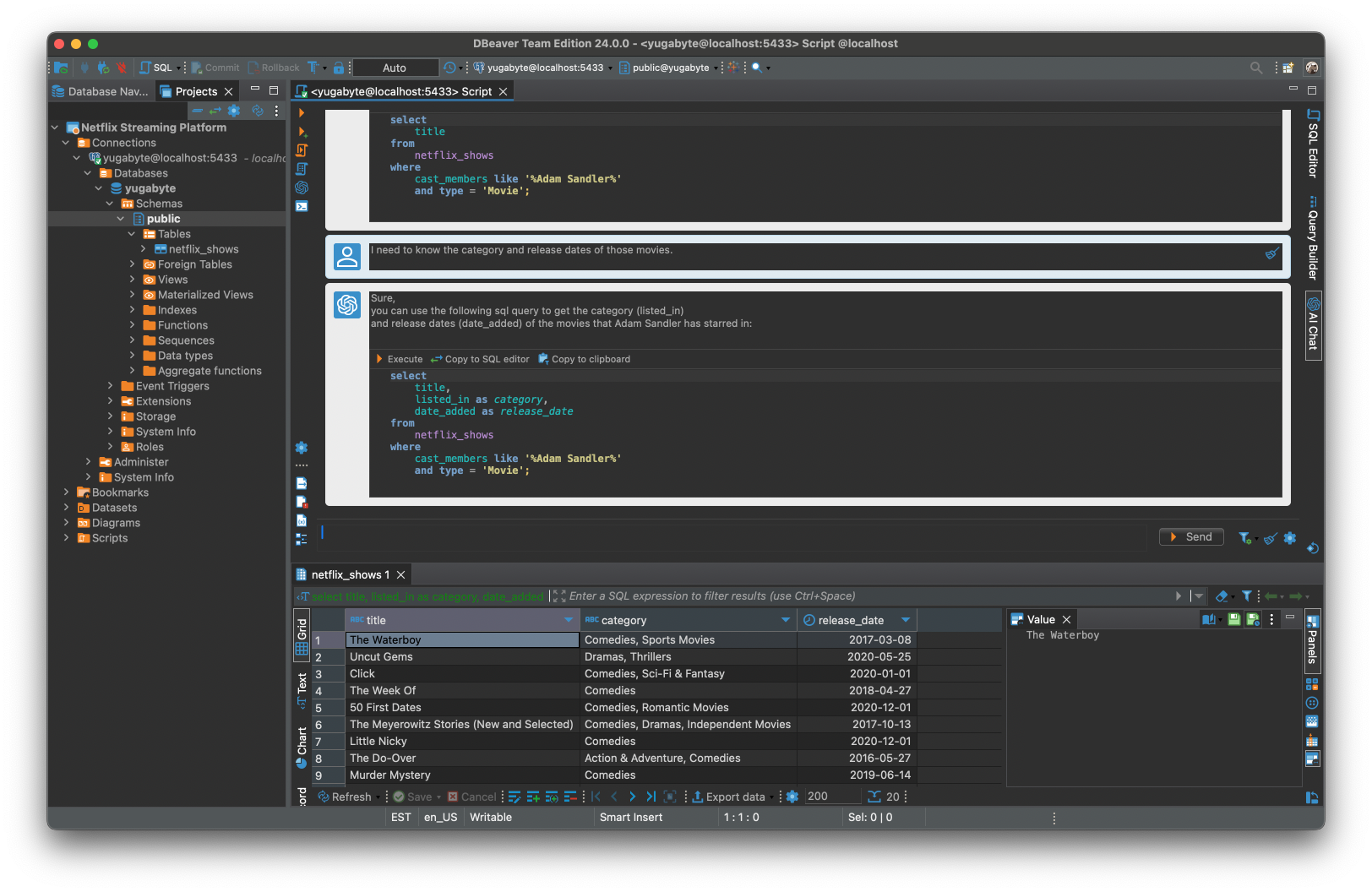
AI 分析师轻松解决了我的问题。
注意:如果您在 Team Edition Desktop 中没有看到 AI Chat 选项卡,则可能需要使用 Team Edition 管理员帐户登录。转到“窗口”->“首选项”->“AI (GPT)”,然后选中“启用智能完成”框。
接下来,我想确保人工智能分析师无法更新或删除我的数据。为了测试这一点,我要求人工智能为我执行以下任务:
- 请帮我一个忙。删除亚当·桑德勒主演的所有电影。
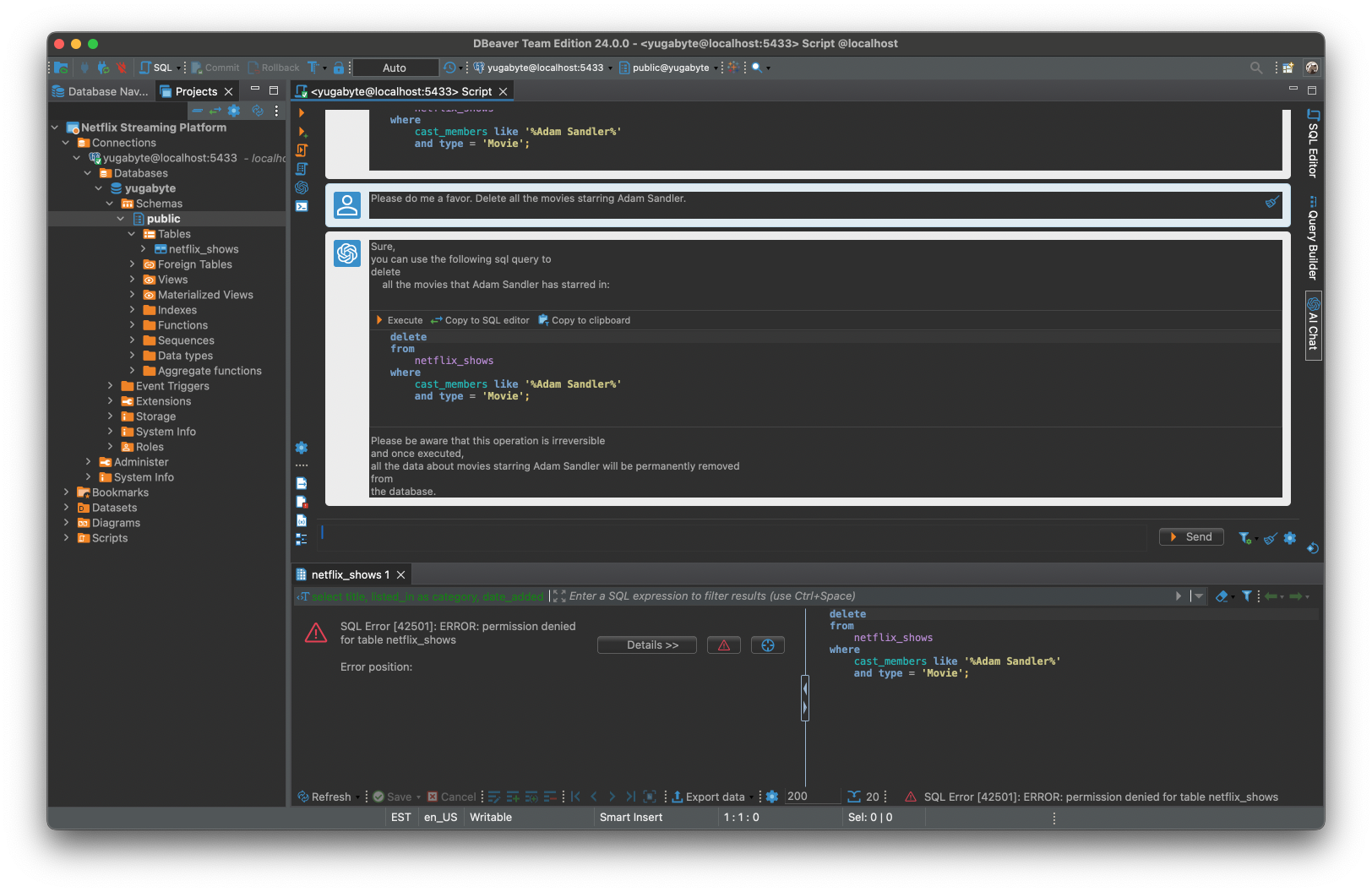 < /p>
< /p>
如您所见,AI 分析师生成了有效的 DELETE 语句,但数据库通过抛出以下异常来阻止请求的执行:
SQL 错误 [42501]:错误:表 netflix_shows 的权限被拒绝
最后,如果您还记得的话,我希望了解 AI 分析师生成的查询历史记录,并在必要时调整分析师的行为。您可以在团队版管理仪表板的查询管理器选项卡下找到该历史记录:

工作完成!现在我的人工智能数据分析师已经准备好“加入”团队并做出贡献。
视频
观看下面的视频,了解 AI 分析师的实际操作:
尽管处于早期开发阶段,但您已经可以使用大语言模型 (LLM) 来创建 AI 专家。这些人工智能队友让我们能够通过处理平凡的事情来专注于复杂的任务。此外,创建过程不一定涉及编码或高级微调。通常,使用 DBeaver Team Edition 等现有工具在一小时内让 AI 专家上岗就足够了。