

在本文中,我们将了解如何使用 Word2Vec 创建反向字典。我们将使用 Word2Vec,但使用任何单词嵌入模型都可以获得相同的结果。不要担心,如果你不知道这意味着什么,我们将解释它。反向字典只是输入定义并返回与该定义匹配的单词的字典。
您可以在配套存储库中找到代码。
寻找神经网络的不同起点?读
使用 TensorFlow 实现神经网络的简介
实践中的自然语言处理
自然语言处理是一个很好的领域:我们发现它非常有趣,我们的客户需要在其应用程序中使用它。我们写了一个伟大的解释文章:分析和理解文本:自然语言处理指南。现在,我们希望编写更多实用的,以帮助您在项目中使用它。我们认为它很有用,因为它可能很难进入它:你永远不知道一个问题是否可以在一天内解决,与一个现成的图书馆,或者你需要两年和一个研究小组,以获得体面的结果。简单地说:困难的不是技术方面,而是了解如何成功应用它。
如果一个问题可以通过机器学习来解决,情况就更是如此。您需要一些背景来理解机器学习。即使解决方案有效,您仍可能需要数周的调整权重和参数才能正确使用。
因此,在本文中,我们将只看到一种技术和一个简单的应用程序:反向字典。也就是说,如何从它的定义中得到一个词。这是一个整洁的应用程序,你不能真正得到一个传统手段。没有官方反向字典书,你可以买,你不能用确定性算法编码。
在机器学习中表示单词
机器学习问题的第一步是了解如何表示必须使用的数据。最基本的方法是使用一热编码。使用此方法::
- 收集所有可能值的列表(例如,10,000 个可能的值)
- 每个可能的值都用具有与可能值一样多的分量的矢量表示(例如,每个值由具有 10,000 个分量的矢量表示)
- 表示每个值,则在所有组件中分配 0,但一个组件除外,该组件将具有 1(即,每个组件为 0,但一个组件为 1 除外)
例如,应用于单词,这意味着:
- 你有一万个单词的词汇
- 每个单词由矢量表示,并且向量有 10,000 个分量
- 单词
dog由 [1, 0, 0 …]表示, 单词cat由 {0, 1, 0 …]等表示.
此方法能够表示所有单词,但它有几个大缺点:
- 每个向量非常稀疏;大多数组件为 0
- 表示形式不持有任何语义值;父亲和母亲是接近的意义,但你永远不会看到,使用一热编码
单词嵌入到救援
为了克服这两个限制,我们发明了词嵌入这允许具有更密集的向量 -并捕获单词的含义,至少相对于其他单词。第二个语句简单意味着,嵌入的单词并不真正捕获 father 含义,但其表示形式将与 的表示形式 mother 类似。
这是一个非常强大的功能,并允许各种很酷的应用程序。例如,这意味着您可以解决这样的问题:
父亲当妈妈对女儿说的是什么词?
第一个单词嵌入模型是Word2Vec(来自谷歌),我们将用它来构建反向字典。这种模式彻底改变了该领域,并激发了许多其他模型,如FastText(来自 Facebook)或GloVe(斯坦福德)。这些模型之间有细微的差别 – 例如,GloVe 和 Word2Vec 在单词上训练,而 FastText 列车在字符 n-gram上。然而,原理、应用和结果非常相似。
Word2Vec 的工作原理
Word2Vec的有效性依赖于一种技巧:我们将为一项任务训练神经网络,但随后我们将将其用于其他任务。这不是 Word2Vec 所独有的。这是机器学习中常用的方法之一。基本上,我们将训练神经网络以产生一定的输出,但随后我们将丢弃输出层,并保留神经网络隐藏层的权重。
训练过程照常工作:我们为神经网络提供输入以及此类输入的预期输出。这样,神经网络可以慢慢学习如何生成正确的输出。
此训练任务是计算某个单词在上下文中出现的概率,给定我们的输入词。例如,如果我们有 programmer 这个词,那么在 computer 短语中看到靠近它的单词的概率是多少?
Word2Vec 培训策略
训练 Word2Vec 有两种典型的策略:CBOW 和跳过克 – 一种是另一种相反的策略。通过连续的单词袋 (CBOW),我们将在输入中给出一个词的上下文,在输出中,我们应该生成我们关心的单词。使用跳过克,我们将做相反的事情:从一个词中,我们将预测它出现在上下文。
最基本的术语上下文只是指目标词周围的单词,如目标词之前和之后的单词。但是,您也可以在句法意义上使用上下文(例如,如果目标词是动词,则主题)。在这里,我们将集中讨论上下文最简单的含义。
例如,假设该短语:
the gentle giant graciously spoke
使用 CBOW 时,我们将输入 [gentle, graciously] 以在输出中 giant 输入 。而使用跳过克时,我们将输入 giant 并 [gentle, graciously] 输出。培训是用单个单词完成的,因此在实践中,对于 CBOW:
- 第一次,我们在
gentlegiant输出中输入和预期。 - 第二次,我们在
graciouslygiant输出中给出预期。
对于跳过克,我们将反转输入和输出。
我们从神经网络得到什么
正如我们所说,在培训结束时,我们将丢弃输出层,因为我们并不真正关心一个单词出现在靠近输入词附近的可能性但是,我们将保留神经网络隐藏层的权重,并用它来表示单词。这是怎么回事?
它之所以有效,是因为我们的网络结构。我们网络的输入是一个词的一热编码。例如,由 dog [1, 0, 0 … ] 表示。在训练期间,输出也将是一个词的一热编码(例如,使用CBOW,对于 the dog barks 短语,我们可以 dog 在输入中给出并放入 barks 输出)。最后,输出层将具有一系列概率。例如,给定输入 cat 字,输出层将具有该单词 dog 出现接近 cat 的概率。另一种可能性是该单词 pet 将出现接近,等等。
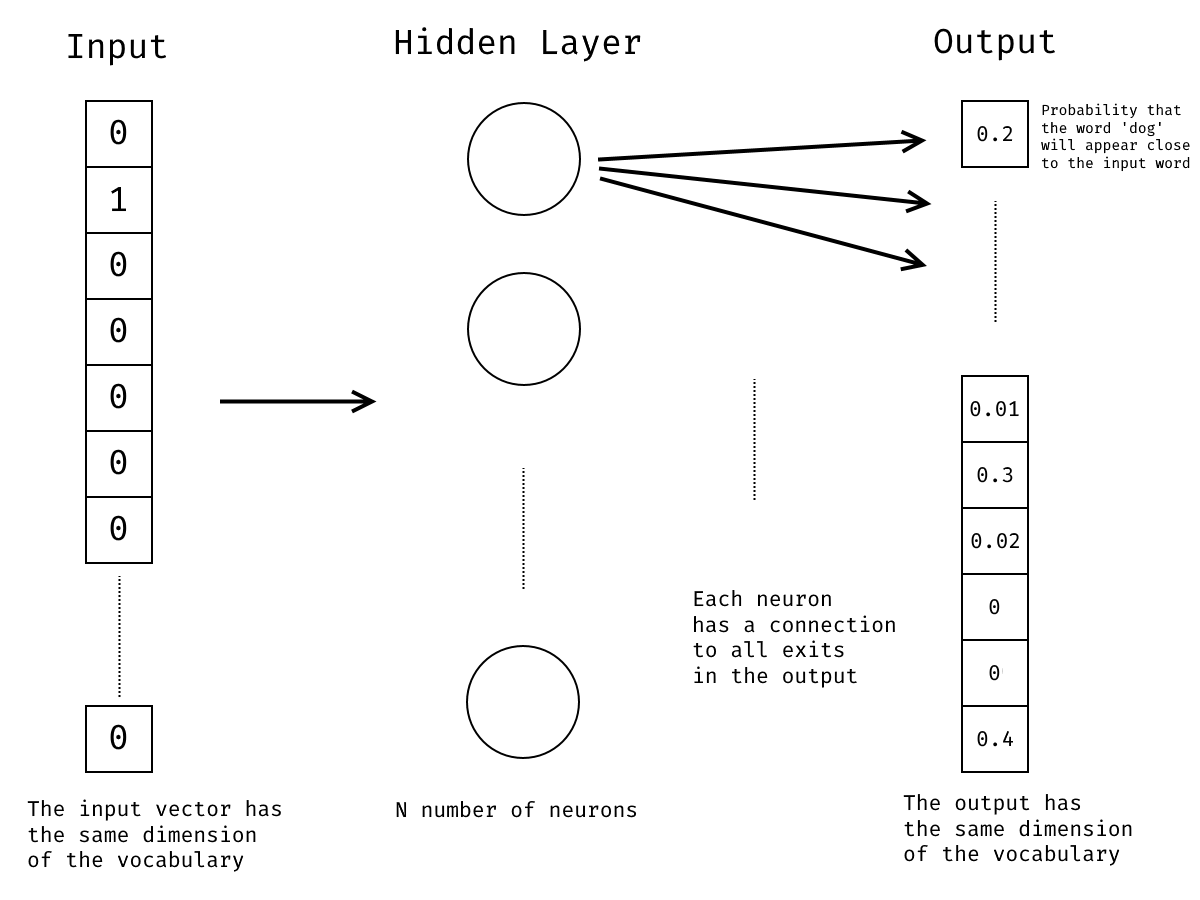
每个神经元都有每个单词的权重,因此在训练结束时,我们将有 N 个神经元,每个神经元的词汇的每个单词都有一个权重。此外,请记住,表示单词的输入向量都是零,但只保存一个位置 , 其中 1。
因此,根据矩阵乘法的数学规则,如果我们将输入向量与神经元的矩阵相乘,输入向量的0将取消神经元中的大多数权重,而每个神经元中剩下的将是一个权重,与输入词相连。每个神经元中的非空权重序列将是表示 Word2Vec 中单词的权重。
具有相似上下文的单词将具有类似的输出,因此它们具有特定单词旁边的类似概率。换句话说,狗和猫会产生类似的输出。因此,它们也将具有类似的权重。这就是意思接近的单词用 Word2Vec 中也接近的矢量表示的原因。
Word2Vec 的直觉非常简单:类似的单词将出现在类似的短语中。然而,它也是相当有效的。当然,前提是您有足够的数据集进行培训。我们稍后会处理这个问题。
Word2Vec 中的含义
现在,我们已经了解了 Word2Vec 的工作原理,我们可以看看这如何导致反向字典。反向字典是从输入定义中查找单词的字典
让我们从显而易见的开始:词嵌入的自然使用将是同义词的字典。这是因为,正如我们说过的,在这个系统中,类似的词语也有类似的表示形式。因此,如果您要求系统查找靠近输入的单词,它会找到一个含义相似的单词。例如,如果您有 happiness ,则期望获得 joy 。
从这个,你可能会认为,也做相反的可能,如找到输入词的反义词。不幸的是,这不能直接实现,因为表示单词的向量无法捕获如此精确的单词之间的关系。基本上,单词的矢量 sad 位于 的镜像位置,这 happy 不是真的。
为什么它工作
查看以下单词向量的简化表示,以了解其工作原因。
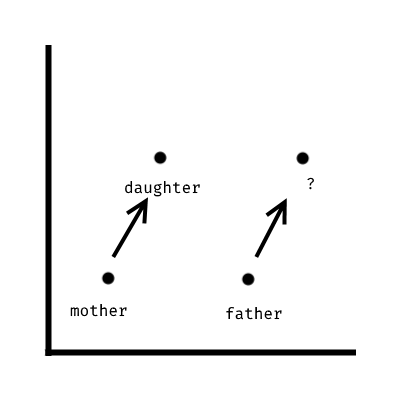
系统可以找到由指示的单词, ? 因为它可以从向量中添加 father 两个给定的单词向量 ( mother 和 ) daughter 之间的差异。系统确实捕获了单词之间的关系,但它不能以易于理解的方式捕获它们之间的关系。换句话说:向量的位置是有意义的,但它意味着它不是以绝对方式定义的(例如,相反的),仅在相对位置(例如,看起来像 A 减去 B 的单词)中定义。
这也解释了为什么不能直接找到反义词:在 Word2Vec 表示形式中,没有可用于描述这种关系的数学运算。
反向词典的工作原理
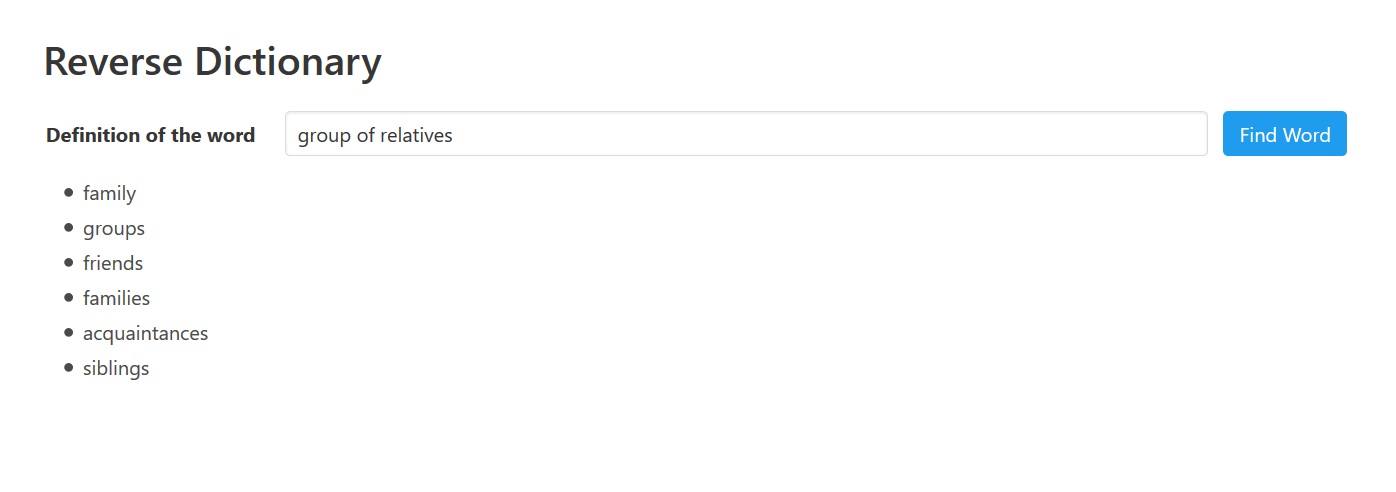
现在,您已经完全理解了单词矢量的强大功能,您可以了解如何使用它们来创建反向字典。基本上,我们将使用它们来查找一个类似于输入词组合的单词,即定义。这将工作,因为系统使用矢量数学来查找更接近作为我们输入的单词集的单词集我们还能够在定义中使用否定的单词来帮助识别一个单词。例如, group of -relatives 解析为 organization 。稍后我们将看到否定一个词的确切含义。
Word2Vec 模型的数据
现在,理论已经很清楚了,我们可以看看代码并构建这个东西。
第一步是建立字典。这本身并不难,但这样做可能需要很长时间。更重要的是,我们可以使用的内容越多越好。对于普通用户来说,下载和存储大量数据并不容易。仅英语维基百科的转储,提取时,可以占用超过50GB(只有文本)。公共爬网(可自由获取的爬网页)数据可能需要数 PB 的存储空间。
出于实际原因,最好使用 Google 基于 Google 新闻数据共享的预训练模型:GoogleNews 矢量-负300.bin.gz。如果搜索此文件,可以在很多地方找到它。以前,官方来源是在谷歌代码项目,但现在最好的来源似乎是在谷歌驱动器。它是 1.6GB 压缩,您不必解压缩它。
一旦我们下载了数据,我们可以把它放在 models 我们项目下的目录中。Word2Vec 有许多库,因此我们可以使用多种语言,但鉴于 Python 在机器学习中很受欢迎,我们将选择 Python。我们将使用库gensim的Word2Vec实现,因为这是最优化的。对于 Web 界面,我们将使用 Flask。
加载数据
首先,我们需要用3条简单的行在内存中加载Word2Vec。
model = KeyedVectors.load_word2vec_format("./models/GoogleNews-vectors-negative300.bin.gz", binary=True)
model.init_sims(replace=True) #
model.syn0norm = model.syn0 # prevent recalc of normed vectors第一行是加载数据的唯一真正需要行。其他两行需要在开始时进行一些初步计算,以便以后无需为每个请求执行这些计算。
但是,这 3 行可能需要 2-3 分钟才能在普通计算机上执行(是的,使用 SSD)。你这段时间只等一次,在开始的时候,所以它不是灾难性的,但它也不理想。另一种方法是一劳永逸地进行一些计算和优化。然后,我们保存它们,并在每次启动时,从磁盘加载它们。
我们添加此函数以创建数据的优化版本。
def generate_optimized_version():
model = KeyedVectors.load_word2vec_format("./models/GoogleNews-vectors-negative300.bin.gz", binary=True)
model.init_sims(replace=True)
model.save('./models/GoogleNews-vectors-gensim-normed.bin')在主函数中,我们每次都使用此代码加载 Word2Vec 数据。
optimized_file = Path('./models/GoogleNews-vectors-gensim-normed.bin')
if optimized_file.is_file():
model = KeyedVectors.load("./models/GoogleNews-vectors-gensim-normed.bin",mmap='r')
else:
generate_optimized_version()
# keep everything ready
model.syn0norm = model.syn0 # prevent recalc of normed vectors这将加载时间从几分钟缩短到几秒钟。
清理字典
我们还有一件事要做:清理数据它使我们能够获得比构建我们自己的模型更好的结果。但是,由于它基于新闻,它还包含大量拼写错误,更重要的是,它包含我们不需要的实体模型。
换句话说,它不仅包含个别的词语,还包括新闻中提到的建筑物和机构的名称。由于我们想要建立一个反向字典,这可能会阻碍我们。例如,如果我们在输入中给出一个类似这样的定义, a tragic event 会发生什么情况?系统可以发现,这组词语最相似的项目是发生悲惨事件的地方。我们不希望这样。
因此,我们必须筛选模型输出的所有项,以确保只向用户显示您在字典中实际可以找到的常用单词。我们的此类单词列表来自SCOWL(面向拼写检查器的单词列表)。使用链接网站中的工具,我们创建了一个自定义字典并将其放入我们的 models 文件夹中。
# read dictionary words
dict_words = []
f = open("./models/words.txt", "r")
for line in f:
dict_words.append(line.strip())
f.close()
# remove copyright notice
dict_words = dict_words[44:]现在,我们可以轻松地加载单词列表,以比较 Word2Vec 系统返回的项目。
反向词典
反向字典功能的代码非常简单。
def find_words(definition, negative_definition):
positive_words = determine_words(definition)
negative_words = determine_words(negative_definition)
similar_words = [i[0] for i in model.most_similar(positive=positive_words, negative=negative_words, topn=30)]
words = []
for word in similar_words:
if (word in dict_words):
words.append(word)
if (len(words) > 20):
words = words[0:20]
return words从用户中,我们收到描述所需单词的输入正词。我们也收到负词,从数学上讲,这些词的向量必须从其他单词中减去。
很难理解这个操作的含义:我们并不是把单词的对立面都包括在内。相反,我们说我们要删除否定词的意思。例如,假设定义为 group of -relatives ,带有 relatives 否定的单词 和 group 正 of 词。我们说我们想要的词与 和 所标识的词集的词关系最密切, group of 但从该含义中,我们删除了由 中专门添加的任何 relatives 意义。
这发生在第 5 行,其中我们称之为发现前 30 个单词最类似于由正词和意义词的组合标识的含义的方法。函数返回单词和相关分数,因为我们只对单词本身感兴趣,所以我们忽略分数。
代码的其余部分很容易理解。从之前返回的单词中,我们仅选择真实单词,而不是地点或事件。我们通过比较我们之前加载的字典单词数据库中的单词来做到这一点。我们还将列表减少到最多 20 个元素。
从输入中清除单词
在 find_words 方法中,在第 2 行和第 3 行上,我们调用 determine words 函数 。此函数基本上从输入字符串生成单词列表。如果单词被减号预置,则被视为负字。
def determine_words(definition):
possible_words = definition沃卡布:
德尔可能[单词]i_
可能 [表达式 ]
对于 w 在 [可能]单词[i:i_3] 对于 i 在范围 (伦 (可能 [单词)-3]) :
可能_表达式.追加(””.join(w))
前删除 [ ]
i 在范围内(len(可能_表达式)):
如果可能[表达式_i]在模型.vocab中:
前删除.追加(i)
单词[删除]
在 ex_to_删除中为 i:
单词[删除][i,i,i=1,i=2]
单词_要删除= 排序(设置(单词_要删除))
单词 = [可能 ]表达式 [i] 在 ex_____________________________________________________________________________________________________________________________________________________
i 在范围内(len(可能_单词)):
如果我不用语言[删除]:
单词.追加(可能[单词]i_)
返回词
此函数首先生成单词列表,但随后还会添加表达式。这是因为除了简单单词之外,Google News 模型还具有短语的矢量表示形式。我们尝试简单地将 3 克单词(即滑动 3 个单词集)组合起来来查找表达式。如果在 Google 新闻模型(第 14 行)中找到表达式,我们必须将表达式作为一个整体添加并删除各个单词。
Web 应用程序
为了便于使用,我们创建了一个简单的Flask应用程序:一个基本的Web界面,让用户提供定义并读取单词列表。
def create_app():
app = Flask(__name__)
return app
app = create_app()
@app.route('/', methods=['GET', 'POST'])
def index():
if request.method == 'POST':
words = request.form['definition'].split()
negative_words = ''
positive_words = ''
for i in range(len(words)):
if(words[i][0] == '-'):
negative_words += words[i][1:] + ' '
else:
positive_words += words[i] + ' '
return jsonify(find_words(positive_words, negative_words))
else:
return render_template('index.html')应用回答根路由:它显示包含提供定义的窗体的页面,并在收到定义时返回相应单词的列表。多亏了Flask,我们可以用几行来创建它。
 它是如何工作的?那么,这种方法非常适合描述性定义,也就是说,如果我们使用描述我们要找的词的定义。也就是说,您可能会在应用返回的列表中找到正确的单词。它可能不是最顶端的词,但它应该在那里。它对于逻辑定义(
它是如何工作的?那么,这种方法非常适合描述性定义,也就是说,如果我们使用描述我们要找的词的定义。也就是说,您可能会在应用返回的列表中找到正确的单词。它可能不是最顶端的词,但它应该在那里。它对于逻辑定义( female spouse 例如,) 不起作用。因此,它肯定不是一个完美的解决方案,但它适用于如此简单的东西。
总结
在本文中,由于 Word2Vec 和随时用型库的强大功能,我们用几行错误创建了一个有效的反向词典。对于一个小教程来说,这是一个不错的结果。但是,在机器学习方面,您应该记住一些事情:应用的成功并不取决于代码。对于许多机器学习应用程序,成功很大程度上取决于您拥有的数据。在您使用的培训数据中以及如何将数据馈送到程序。
例如,我们遗漏了一些用于选择数据集的试验和错误。我们已经预料到 Google 新闻数据集会有一些问题,因为我们知道它包含新闻事件。因此,我们尝试基于英语维基百科构建我们自己的数据集。我们惨败:结果比我们使用谷歌新闻数据集的结果更糟。部分问题在于数据较小,但真正的问题是,我们的能力不如最初的谷歌工程师。为训练选择正确的参数需要一种黑魔法,你只有获得很多经验才能学习。最后,对我们来说,最好的解决方案是使用 Google 新闻数据集并筛选输出,以消除应用程序不需要的结果。有点谦卑,但有些东西是值得记住的。