
导语: BERT模型自诞生以来统治了各项NLP任务的榜单,谷歌也针对中文给出了基于字的模型。然而我们知道词是语言最重要的组成部分,因此,一个自然的想法就是做基于词的BERT模型。但是受限于显存,谷歌原生的BERT模型可以使用的词典比较小,只能覆盖一小部分的汉语的词。在本文中,我们提出了对BERT的一些改进,将中文BERT词模型的词典大小进行了大幅扩充,并在多个下游任务上测试了大词典BERT的表现。此外,我们尝试了一种针对上下文相关词向量的最近邻检索方法,基于BERT的词向量做以词搜词任务,相对于上下文无关词向量在效果上有着明显的提升。
1. 做大词典BERT词模型的意义
词是语言最重要的组成部分。谷歌发布基于字的BERT[1]模型之后,一个很自然的想法就是将词的信息引入到模型之中。词在汉语中扮演了非常重要的词是语言最重要的组成部分。谷歌发布基于字的BERT[1]模型之后,一个很自然的想法就是将词的信息引入到模型之中。词在汉语中扮演了非常重要的角色。很多词所表达的含义与其包括的字的含义没有直接联系,比如音译词“巧克力”、“圣代”。
最近有一些工作尝试将词的信息引入到BERT中去。百度的ERNIE通过遮罩策略将词的信息引入到模型之中,但是其本质仍然是基于字的模型[2]。另外一种方式是对语料进行分词,直接训练基于词的中文BERT模型。不过由于中文词典很大,在谷歌BERT上使用大词典会导致显存溢出。使用小词典的话会导致大量的OOV。为了减缓OOV的影响,我们需要扩大词典。
因此本文引入了一些语言模型训练的技术,提出了训练大词典BERT模型的方法。大词典能提升词语的覆盖度,减缓未登录词(OOV)问题[3]。不过虽然大词典能够减缓OOV,但是相比于字模型,仍然存在一定比例的OOV,会受到OOV的影响。此外,训练基于词的BERT模型能够得到高质量的上下文相关词向量。这些向量可以用于各种应用和下游任务之中。
2. 大词典BERT简介
在谷歌原来的BERT模型中,embedding 层和softmax 层的参数数量随着词典大小呈线性变化。如果在BERT-base模型上使用50万大小的词典,那么embedding层和softmax层会包含500000*768+768*500000=7.68亿个参数。要知道BERT-base的编码器层(12层transformer)也仅仅包含8500万个参数。因此,直接在BERT上使用大词典会造成显存溢出。实际上,对于BERT-base模型(在P40型号的GPU上,batch size为32),当句子长度为128的时候,最多支持16万的词典大小,当句子长度为192的时候,只能支持8万的词典大小。
在下面的章节中,我们针对embedding 层和softmax 层进行优化。对softmax层优化后词典可以达到五十万大小,对softmax层和embedding层同时优化可以把词典扩大到100万大小。

3. Adaptive Softmax
3对softmax层的优化一直是自然语言处理领域研究的重点。这个方向的研究很多,常用的技术包括基于采样的方法[4],基于树的方法[5]等等。这里我们使用facebook提出的adaptive softmax[6]进行优化。之所以选择adaptive softmax,一方面是因为其是针对GPU进行的优化。我们在多机多GPU上进行预训练,使用adaptive softmax能帮助我们在效率上得到显著的提升。另一方面,adaptive softmax可以节约显存,这是我们引入大词典的关键。下面简要介绍adaptive softmax的原理。
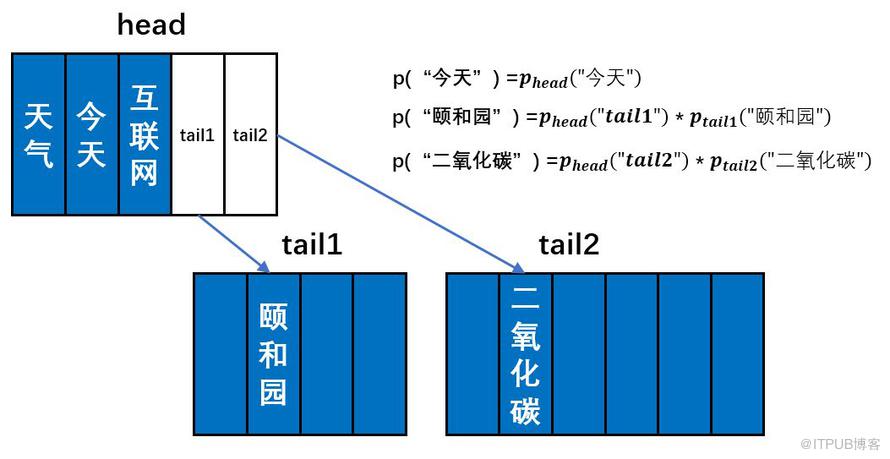
如上图所示,如果我们将词典分成三个部分,那么adaptivesoftmax则由三个前向神经网络构成,我们分别称之为head、tail1、tail2。第一个词典会链到第二和第三个词典。我们根据词频对词语进行排序,令head前向神经网络去预测高频词语;tail1去预测中间频率的词语;tail2去预测低频词语。
因为高频词占据了语料中绝大部分的频数(Zipf’s Law),所以在大多数情况下,我们只需要用head这个规模较小的前向神经网络去做预测,这很大程度上减少了计算量。当遇到低频词的时候(比如上图中的“二氧化碳”),模型先使用head去预测,发现“tail2”的概率值最大,这表明需要继续使用tail2前向神经网络去预测。然后我们得到tail2前向神经网络对于“二氧化碳”的预测值之后,让其与head的“tail2”位置的概率值相乘,就能得到“二氧化碳”这个词的预测概率。在具体实现中,tail1和tail2一般是两层的前向神经网络,中间隐层维度设为一个较小的值,从而实减少模型的参数。下图是PyTorch实现的一个adaptive softmax的示例。词典大小为50万。

可以看到,中间频率的词语的向量维度是192;低频词语的向量维度是48。相对于原来的参数量,adaptive softmax参数减少了500000*768-37502*768-62500*192-400000*48-768*768-192*768-48*768 = 323224320个,相当于原来参数量的84.2%。在使用adaptive softmax之后,词典的规模可以从8万扩展到50万。50万词典已经可以覆盖绝大部分常见词,能有效的减少OOV的情况。
4. Adaptive Input
Softmax层一定程度上可以看作embedding层的镜像。因此可以把softmax上的优化操作搬到embedding层。在今年的ICLR上facebook提出了adaptive input方法[7]。下面简要介绍adaptive input的原理。
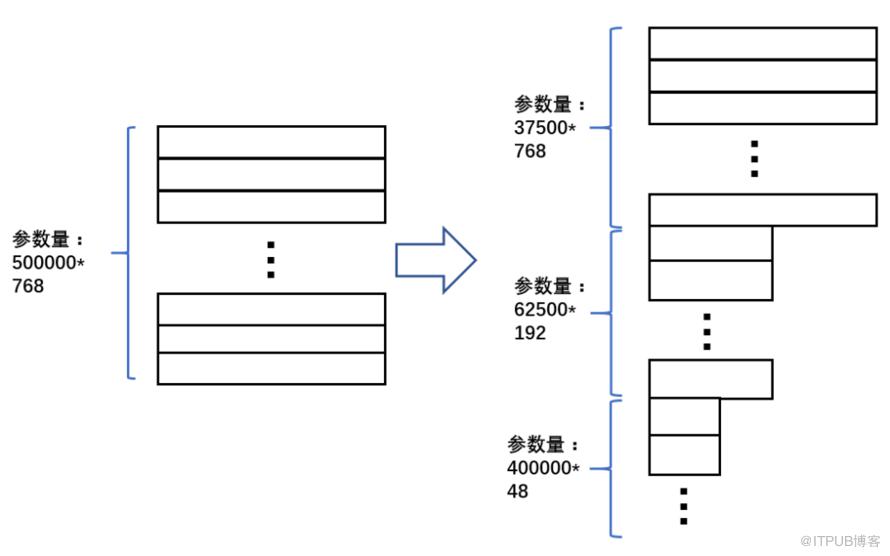
如上图所示,adaptive input对高频词使用较大的维度,对低频词使用较小的维度。更具体的,上图把50万词语按照词频排好序,并分成三个部分:第一部分包括37500个高频词语,词向量维度为768;第二部分包括62500个中间频率的词语,词向量维度为192;第三部分包括40万个低频词语,词向量维度为48。为了使维度可以统一到隐层维度,这里引入了三个不同的前向神经网络,把不同维度的词向量映射到相同的维度。经过计算,我们可以得到adaptive input 减少的参数量是500000*768-37500*768-62500*192-400000*48-768*768-192*768-48*768= 323225856,相当于原来的参数量的84.2%。当模型同时引入adaptive softmax和adaptive input的时候,词典可以进一步扩展到100万。
5. 动态词典
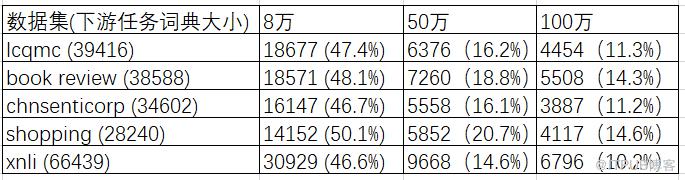
谷歌BERT模型使用固定的词典,即对不同的语料和下游任务,均只使用一个词典。这对基于字的模型是合理的。因为中文字的数量有限,使用谷歌提供的大小为21128的词典不会有OOV的问题。但是对于基于词的BERT模型,使用固定词典则会有严重的问题。下表展示了使用中文维基百科作为预训练语料,在多个下游任务上的OOV词语数量以及OOV词语数量占总词典大小的百分比。其中第一列展示了不同下游任务数据集的名称以及对应的词典大小,第二、三、四列展示了不同大小的维基百科词典与下游任务数据词典相比较时的OOV在下游任务数据集的占比。可以看到,大词典有效的缓解了OOV的问题。但是即使词典扩大到100万,仍然有很多未登录词
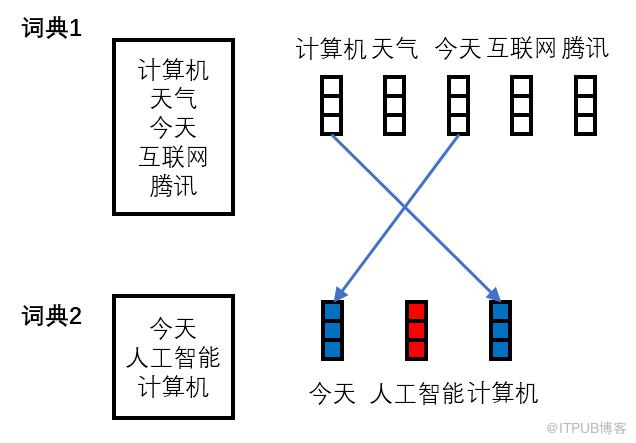
因此,对于基于词的BERT模型,无论是用新的语料进行叠加预训练,还是针对下游任务进行微调,我们都需要生成新的词典(动态词典),并根据新的词典去对预训练模型的embedding层和softmax层进行调整。调整的方式如下图所示(蓝色表示根据预训练模型的参数初始化,红色表示随机初始化)。如果使用固定词表,那么词语“人工智能”会被映射到UNK,这个词语无法在下游任务上进行训练。对于加入adaptive机制的模型,调整的过程会增加一些步骤。后面实验中基于词的BERT模型均默认使用动态词典。动态词典相对于固定词典在效果上有着显著的提升。
6. 基于BERT的以词搜词
本文的另一项工作是尝试了一种上下文相关词向量的最近邻检索方法。在传统的词向量工作中,每个词对应一个固定的向量,我们称其为上下文无关词向量。对这类词向量进行最近邻检索只需要计算词向量之间的cos值,并根据cos值进行排序。对于上下文相关词向量,词向量不仅和词语本身有关,还和词语周围的上下文有关。也就是语料中的每一个token(词语的一次出现),都有一个独有的向量。ELMO[8]为每个token计算一个向量,并利用token向量去寻找其它的token向量。ELMO是基于整个语料寻找token向量的最近邻。这里我们尝试一种基于词典的上下文相关词向量检索方法,具体步骤如下:假如我们需要查找在句子“吉利汽车是中国汽车品牌”中词语“吉利”的最近邻(如下图),我们首先把这句话输入到BERT编码器中,取最上层的词语对应的隐层向量作为词向量。然后我们把词典中的所有词语依次替换到“吉利”的位置,这样就得到每个词语在特定上下文中的向量。我们计算这些向量之间的cos值,即可得到词语的最近邻。
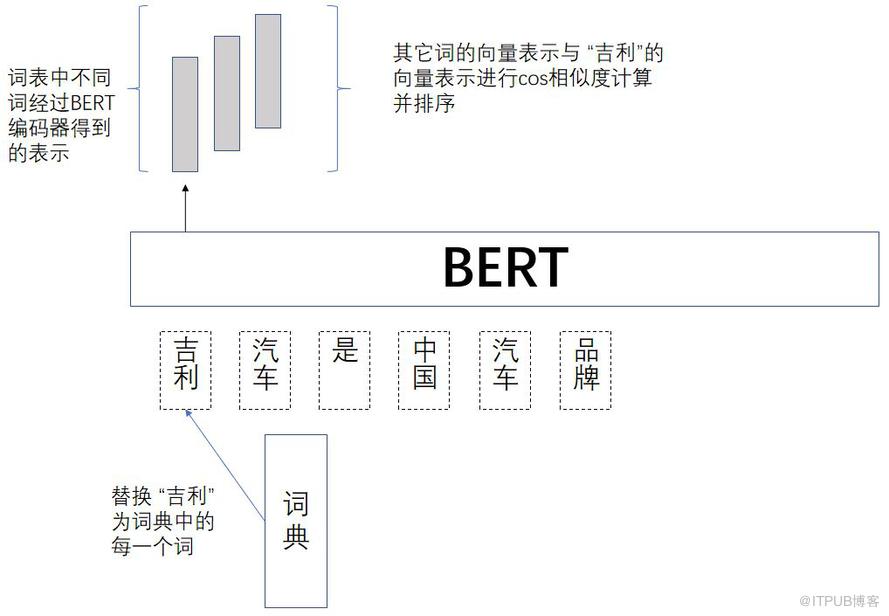
我们还尝试使用基于字的BERT模型进行以词搜词作为基于词的模型的对比。具体步骤和基于词的模型相似,只是在基于字的模型中,每一个字对应一个向量,因此一个词会对应多个向量。我们对BERT编码器最上层的字的隐层向量取平均,从而得到每个词语在特定上下文中的向量。
使用上面介绍的方式进行以词搜词,相对于传统的上下文无关词向量,在多义词的检索效果上有着明显的提升。下面给出几个以词搜词的示例。给定一句话以及这句话中要检索的词语,返回这个词语的最近邻词语以及相似度。
候选词语:“吉利”
候选句子:2010年 6 月 2 日 福特汽车公司 宣布 出售 旗下 高端 汽车 沃尔沃 予 中国 浙江省 的 吉利 汽车 , 同时将 于 2010 年 第四季 停止 旗下 中阶 房车 品牌 所有 业务 , 并 将 其 资源 全数 转移 至 高级车 品牌 林肯 , 2011 年 1 月 4 日 , 福特 汽车 正式 裁彻 品牌 。
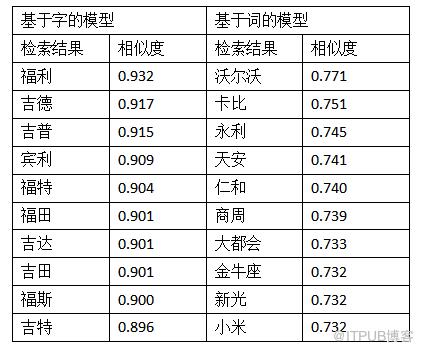
在这个例子中,“吉利”指一种汽车品牌。可以看到基于词的模型的检索效果不错。其中“沃尔沃”、“金牛座”是汽车的品牌。“永利”、“天安”、“仁和”、“新光”均是公司名称,并且这些公司均以一个比较吉利的词语作为公司的名字。基于字的模型效果也不错,会倾向于返回包含“吉”、“利”这两个字的词语。
候选词语:“吉利”
候选句子:主要演员 有 扎克· 布拉 夫 、 萨拉 · 朝克 、 唐纳德 · 费森 、 尼尔 · 弗林 、 肯 · 詹金斯 、 约翰 · 麦 吉利 、 朱迪 · 雷耶斯 、 迈克尔 · 莫斯利 等 。
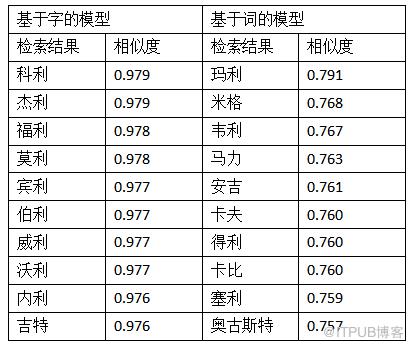
在这个例子中,“吉利”指一个人名。可以看到基于字和基于词的模型均通过上下文捕捉到了这里的“吉利”是人名的信息。基于字的模型返回的人名均包含“利”和“吉”。基于词的模型返回的单词则更加的多样。
候选词语:“吉利”
候选句子:他 出生 时 身上附有 胎膜 , 其母 认为 这是 一个 吉利 的 征兆 。
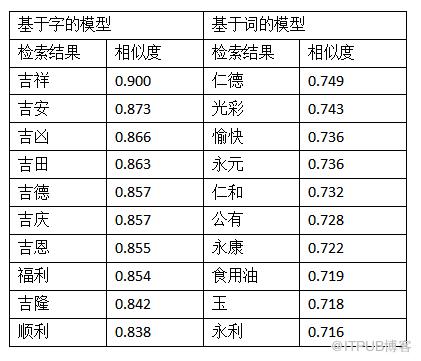
在这个例子中,“吉利”指这个单词的本义。可以看到基于字和基于词的模型均表现不错。基于字的模型返回的单词大多包含“吉”、“利”两字。基于词的模型除了会返回和“吉利”意思相近的词,比如“仁德”、“光彩”、“愉快”,还会返回“食用油”、“玉”这样的名词。这些名字放在原句中比较合适。
候选词语:“苹果”
候选句子: 另外 , 刘德华亦 坚持 每天 喝 一点 混合 果汁 , 比如 苹果 加 红萝卜 一起 榨 的 汁 , 以 保持 自身 的 健康
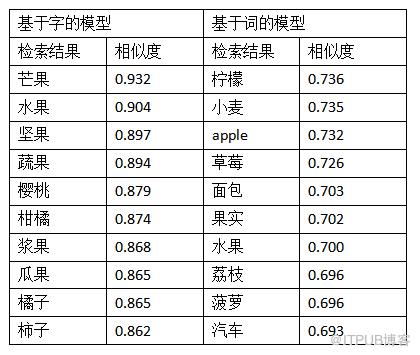
在这个例子中,“苹果”指水果。两种模型效果均不错。基于字的模型倾向返回包含“果”的词。
候选词语:“苹果”
候选句子:苹果 削减 了 台式 Mac 产品线 上 的 众多 产品
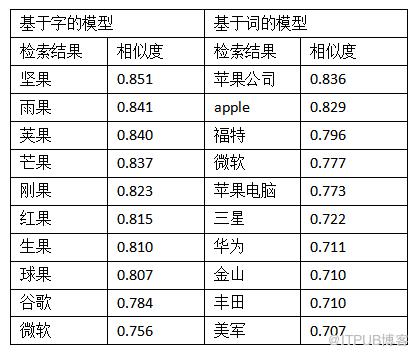
在这个例子中,“苹果”指科技公司。基于词的模型效果不错。但是基于字的模型效果一般,虽然也在topn列表中返回了“谷歌”、“微软”,但是前面几个单词均是包含“果”的词语。
候选词语:“腾讯”
候选句子:马化腾于 1984 年 随 家人 从 海南 移居 深圳 , 14 年后 的 1998 年 11 月 , 他 和 其他 四位 联合创始人一起 创立 腾讯 。
在这个例子中,我们可以看到基于词的模型返回的均是互联网公司或者相关的内容。基于字的模型也会返回和互联网公司相关的单词,比如“微信”、“百度”,但是也会返回一些包含“腾”的词语。这些词语和互联网公司关系较弱。
通过上面的定性分析,我们可以看到使用基于字的BERT模型做词的检索有一定的局限性。基于字的模型的词向量会受到字向量的影响,倾向于返回包含相同字的词语。基于词的模型效果较好,能对多义词进行高质量的检索。
上面使用的检索方法效率较低。假如词典大小为2万,那么进行一次检索,需要通过BERT编码器2万次。如果不加以优化,检索一次的时间需要十几秒以上。目前我们正在进行优化。我们发现合理的减少编码器的层数和attention head的个数,可以在大幅度提升效率的同时,对检索结果质量产生较小的影响。目前,我们对2万词语进行检索,时间可以控制在3秒以内,并能得到较高质量的检索结果。在这个方向上还有很多的优化点,后续我们会进一步探索如何提升检索效率。
7. 实验
和Google BERT一样,我们使用中文维基百科作为语料进行预训练。对于语料中的中文,我们使用jieba默认模式进行分词;对于语料中的英文等其它语言,我们使用和Google相同的分词策略。所有的模型均训练50万步;学习率是1e-4(warmuplinear策略,warmup设为0.01);优化器为BERT默认的AdamW;batchsize为256;序列长度为192。我们使用一个百科词条作为一个文档。文档中根据“。”、“!”、“?”进行分句。目前我们有8万词典和50万词典的模型,100万词典的模型正在训练当中。我们和Google BERT预训练使用的策略基本一样。只是受限于资源,我们的seq_length和训练步数小于Google的预训练模型
7.1 词模型在下游任务的表现
我们用5个公开的中文下游任务数据集来对基于词的BERT模型进行评估。LCQMC是哈工大发布的问题匹配数据集[10];Book review是北师大发布的书评情感分类数据集[11]。Chnsenticorp是百度给出的评论情感分析数据集[2];Shopping是评论数据集;XNLI 是句子关系推理数据集[12]。
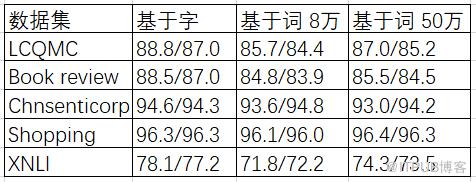
下表展示了基于词的BERT模型在5个公开数据集上的表现。评价指标是不同任务上的分类的准确率(验证集/测试集)。可以看到,词模型在Chnsenticorp以及Shopping数据集上与字模型表现相当,在其他数据集上与字模型相比还有差距。
另外,我们还对基于8万词典和50万词典的BERT模型进行了对比。大词典较大幅度的降低了OOV的情况,50万词典的词模型在四个数据集上的表现都显著优于8万词典的词模型。
7.2 词模型在内部情感分类数据集上的表现
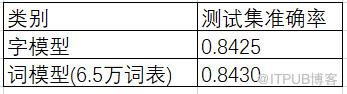
下表展示的是在内部情感分类数据集的结果,与上面测试集不同之处在于,这个测试集以及预训练的词模型的数据集都是同源的,另外由于大词表的情感分类词模型还没有训练出来,这个词模型是一个小词典的词模型,可以看出,词模型的表现比字模型的表现略好一些。
7.3 动态词表的有效性
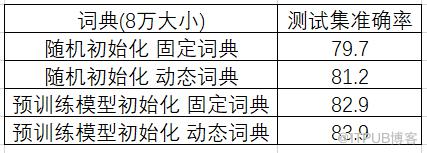
下表展示了使用固定词典和动态词典的模型在书评分类数据集上的效果。不管是使用随机初始化还是预训练模型初始化,动态词典的效果都要显著的好于固定词典。说明动态词表对于词模型去初始化下游任务模型确实非常有用。
7.4 对于实验结果的分析
词模型在公开数据集的表现逊于字模型,我们是不是可以得到词模型一定差于字模型的结论?我们认为答案是否定的。根据内部情感分类词模型的分类结果就可以看出来,词模型还是表现不错。
在公开数据集表现不好,我们认为如下几方面原因,第一是由于OOV的问题,根据上面对于OOV的统计结果,即使词典扩展至100万,也在下游的数据上存在较多OOV的情况,后面虽然加了动态词典,但是这部分新加入的词语向量没有经过预训练。如果预训练语料和下游任务数据集有相似的来源,会一定程度上减缓这个问题。第二是因为词相对于字更加的稀疏(有些词的频率很低),我们使用的预训练语料(中文维基百科)规模较小,这导致对一些词的训练并不充分。在更大规模,更多样的语料上进行预训练有机会带来更好的效果[9]。
此外,词模型在一些数据集表现比较差还有一些其他原因,比如在书评数据集上,测试集包含25988个词语,其中9525个词语不在训练集中。我们认为这是导致在书评数据集上基于词的模型不如基于字的模型的重要的因素,更合适的分词策略(例如细粒度分词)会一定程度上减缓这个问题。总结
在本文中我们介绍了如何通过改进BERT的softmax层和embedding层来扩充中文词模型的词典规模,从而减缓未登录词的问题。此外,在训练好的基于词的BERT模型的基础上,我们给出了一种针对上下文相关词向量进行检索的方法, 展示了使用BERT词向量进行以词搜词的效果。
参考资料:
- Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. NAACL 2019.
- https://github.com/PaddlePaddle/LARK/tree/develop/ERNIE
- Yan Song, Shuming Shi, Jing Li, and Haisong Zhang. Directional Skip-Gram: Explicitly Distinguishing Left and Right Context for Word Embeddings. NAACL 2018.
- Bengio Y, Ducharme R, Vincent P, et al. A neural probabilistic language model[J]. JMLR, 2003.
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Gregory S. Corrado, and Jeffrey Dean:Distributed Representations of Words and Phrases and their Compositionality. NIPS 2013.
- Edouard Grave , Armand Joulin, Moustapha Cisse, David Grangierd, Herve Jegou et al. Efficient softmax approximation for GPUs, ICML 2016.
- Alexei Baevski , Michael Auli. Adaptive Input Representations for Neural Language Modeling. ICLR 2019.
- Peters, Matthew E., et al. Deep contextualized word representations. NAACL 2018.
- https://github.com/dbiir/UER-py
- Liu, X., Chen, Q., Deng, C. , et al. LCQMC: A Large-scale Chinese Question Matching Corpus. COLING 2018.
- Qiu Y, Li H, Li S, et al. Revisiting Correlations between Intrinsic and Extrinsic Evaluations of Word Embeddings. CCL & NLP-NABD.
- https://github.com/facebookresearch/XNLI