
摘要:去O一直是金融保险行业永恒的话题,但去O的难度之大也只有真正经历过的人才知其中的艰辛。此次笔者结合实际去O工作,对去O过程中碰到的DBLINK、SEQUENCE最大值、空串、SQL语句中的别名等等近50个问题进行探讨,绝对是干货满满,诚意十足!

Oracle ACE-A,Oracle 10g OCM,SOUG(中国南方ORACLE用户组)联合发起人,ITPUB 专家。目前任职于某公司,担任技术经理职位,负责公司的软件基础设施的建设和维护工作。
PostgreSQL VS Oracle
站在开发和应用的角度看,底层数据库搭建再好,但如果应用在上面跑不起来,跑的不好,新数据库平台就会变成一座鬼城。
今天,我分享的内容分四大部分,一是技术选型。第二、三是今天的重点,怎么让应用真正在新的数据库平台上面跑起来,这是要探究的一个问题。会涉及到一些比较细节的东西,尤其对于开发人员可能会更加关注一些,当然对于DBA来说,也是需要去注意的。
金融行业技术选型有个特点,当你向公司推荐一个数据库产品时,领导肯定会问个问题,同行业有没有在使用的?
我为什么会选择PostgreSQL?一个很重要的原因是不少同行在用,比如,平安科技。那抛开同行业,PostgreSQL自身有哪些优势?
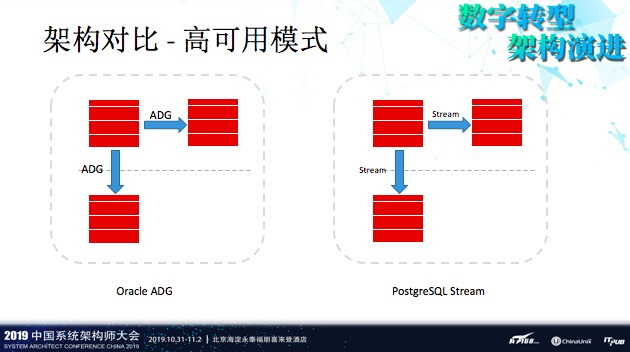
我们做了PostgreSQL与Oracle的对比,就单体模式来说, PostgreSQL完全不输给Oracle,可以做到完全实时的同步,单体保持数据同步方面一点问题都没有。
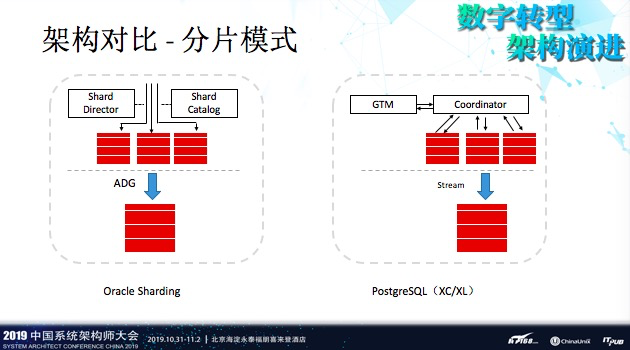
分片模式, Oracle提供了一个Sharding模式。相对应的PostgreSQL有XC/XL解决方案。当然咯,这个方案也不是完美的,比如说GTM可能会成为性能的瓶颈点,很有可能会成为一个瓶颈。
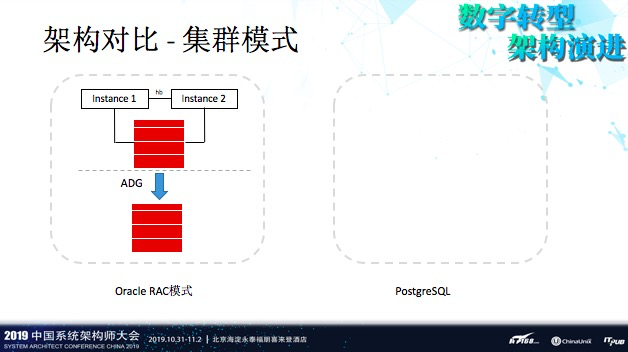
另外,Oracle有个非常强大的功能RAC,这个在PostgreSQL里是没有的。不过PostgreSQL有读写分离的解决方案,在读多写少的场景下,能达到不错的吞吐量。
目前,不管是商业的还是开源的数据库,基本上逃不脱这四种架构。
看下来,PostgreSQL和Oracle是非常像的,包括架构以及数据安全方面,都与Oracle非常像。这也是我们选择PostgreSQL重要的原因。同时,PostgreSQL提供了丰富的可选架构,能满足各种不同场景。PostgreSQL有效遵循SQL标准,让应用迁移难度降低,PostgreSQL有丰富的可选组件,极易扩展等。
在这里顺便也说一下我的观点,现在都在说分布式,但分布式真的适合所有场景吗?我看未必。而且什么是分布式,我觉得这个问题也值得深入思考下。
让应用先跑起来
能不能让应用正确的跑起来,这是事关生存的问题。事关你新系统能不能在公司里面生存下来的问题,这个是非常关键的问题。
下面,涉及到很多往PostgreSQL迁应用时遇到的问题,总结如下:
1、 字符集问题:
PostgreSQL服务端是不支持GBK的,我们用UTF8。PostgreSQL还有个编码EUC CN,这个我们之前测过很多次,有很多生僻字是无法编码的。
比如“瑄”在EUC_CN下就无法编码。因此,不推荐使用EUC_CN。
2、多行注释问题:
/* some comments
/* other comments
/*******************/
• 上述注释在Oracle中是合法的
• 在POSTGRESQL中是非法的
• — 合法的PostgreSQL注释格式:
• — This is a standard SQL comment
• /* multiline comment
• * with nesting: /* nested comment */
• */
• 可以使用PLY(Python-Lex-Yacc)将注释自动改写掉
3、NUMERIC类型问题:

• 上述声明在Oracle中是合法的
• 但在POSTGRESQL中是非法的
• POSTGRESQL不支持负值的scale
• 也不支持scale大于precision
• 负值scale的解决方法:
{ 使用触发器,在触发器中调用round函数 }
SELECT round(123.6, -2);
round
——-
100
(1 row)
scale大于precision的解决方法:
{ NUMBER(2,3) => NUMERIC(3,3) }
{ 增加CHECK (col < 0.1) }
DECLARE
c NUMBER := 1;
pi NUMBER := 3.142;
r NUMBER := 10;
BEGIN
FOR i IN 1..10000 LOOP
c := pi * (r * r) + (mod(r, c) * pi + i);
END LOOP;
END;
/
上述代码在Oracle中是没有任何问题
DO $$
DECLARE
c NUMERIC := 1;
pi NUMERIC := 3.142;
r NUMERIC := 10;
BEGIN
FOR i IN 1..10000 LOOP
c := pi * (r * r) + (mod(r, c) * pi + i);
END LOOP;
END;
$$ LANGUAGE plpgsql;
ERROR: value overflows numeric format
解决方法: 显式指定NUMERIC的精度
DO $$
DECLARE
c NUMERIC(32,2) := 1;
pi NUMERIC := 3.142;
r NUMERIC := 10;
BEGIN
FOR i IN 1..10000 LOOP
c := pi * (r * r) + (mod(r, c) * pi + i);
END LOOP;
END;
$$ LANGUAGE plpgsql;
4、VARCHAR类型问题

上面是经常碰到的VARCHAR问题,值已经超出了目标长度,肯定会报错。但在PostgreSQL里面不一样,会截断但不报错,这要特别注意,因为没有报错,你的应用如果没有注意到这个问题,很有可能你的数据就丢失了,计算结果就出错了,那这个就是很严重的问题了。
5、CHAR类型问题
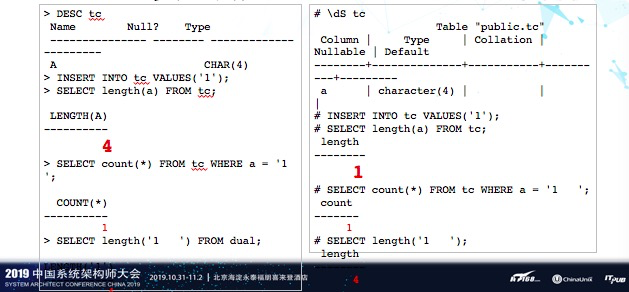
在PostgreSQL中,CHAR类型的长度是实际有效字符的长度,这个和Oracle很不一样。这个在应用中如果不注意的话,就会报很多错误。而且,有时候查起来非常困难。当然我们也可以通过重载函数的方式来模拟Oracle中的行为。
6、SEQUENCE最大值问题
•POSTGRESQL的SEQUENCE最大值:9223372036854775807(bigint)
•而Oracle中的SEQUENCE最大值可达28位十进制值
•一般情况下POSTGRESQL的SEQUENCE是足够的
•但可能也存在一些特殊情况:
{LISCODE.SEQ_YBTBATTRANS_ID ‘10000000000000072561’ }
{ 该值明显已超出最大值}
{ 使用NUMERIC类型,配合触发器使用}
通常情况下PostgreSQL中SEQUENCE足够使用。但上面这个值已经超出最大值,目前,我的解决办法是把它用NUMERIC类型配合触发器使用,用触发器模拟序列类型,如果你是频繁插入,性能下降会非常严重,这是需要注意的问题。
7、类型转换
# CREATE TABLE t1 (id VARCHAR(32));
# SELECT * FROM t1 WHERE id = 27;
ERROR: operator does not exist: character varying = integer
LINE 1: SELECT * FROM t1 WHERE id = 27;
^
HINT: No operator matches the given name and argument type(s). You might need to add explicit type casts.
CREATE CAST (varchar AS integer)
WITH INOUT
AS IMPLICIT;
# SELECT * FROM t1 WHERE id = 27;
id
—-
(0 rows)
# EXPLAIN verbose SELECT * FROM t1 WHERE id = 27;
QUERY PLAN
———————————————————–
Seq Scan on public.t1 (cost=0.00..22.95 rows=4 width=82)
Output: id
Filter: ((t1.id)::integer = 27)
(3 rows)
• 善用CAST
• 根据自己的需求,绘制类型转换矩阵
如果对Oracle熟悉,就会知道Oracle是由明确的类型转换矩阵的,在PostgreSQL里,这方面就差一点。但PostgreSQL提供了自定义创建CAST的特性。在我们实际迁移过程当中,如果你能够把CAST利用好是能解决很大一部分问题的。
7、操作符重载
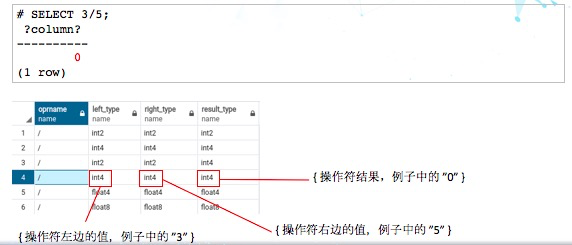
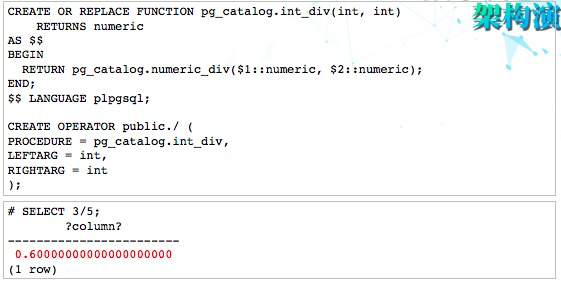
比如说SELECT 3/5是个雷,除了它本身3对应的是INT4,5对应的也是INT4,所以它本身是一个非整型数字,但是,它也是会被截断掉。进行一个重载就可以解决,我们重新定义一个函数,可以用系统的numeric div,这样用户不需要做任何的修改就可以达到跟Oracle一样的效果。
总结一下,操作符重载是PostgreSQL提供的一个非常好的特性,善用操作符重载可以解决一些兼容性问题,以及前面说的CAST是可以解决很多监管系统问题的,在这个过程中也是有很多问题需要注意的。
第一、POSTGRESQL本身它设置了很多类型转换和操作符,这个一定要考虑是否有冲突。
第二、类型转化的操作也需要相互配合,因为在调用操作符时,是要判断类型转换是否需要自己去做的,所以,这两个是需要密切配合才能完美的使用好。
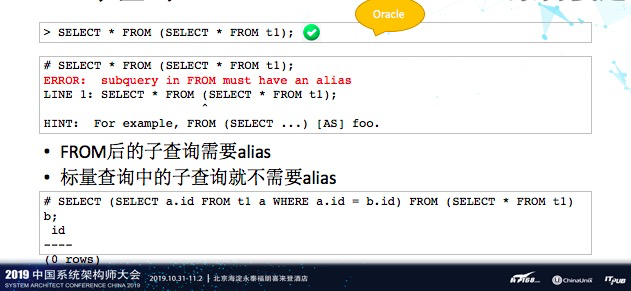
8、子查询
Oracle当中子查询不需要别名alias,但在PostgreSQL当中是不行的。
9、SELECT表达式别名问题
下种这种语句在Oracle里面没有任何问题,但在PostgreSQL就会出问题。
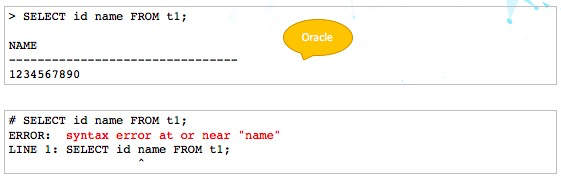
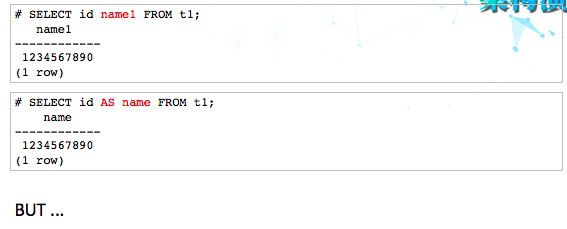
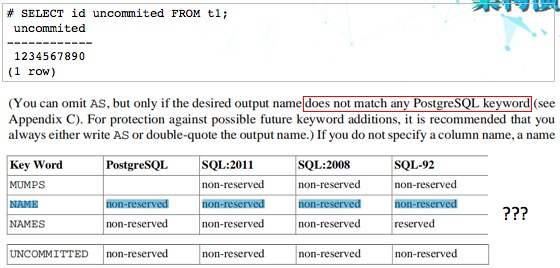
究其原因,是PostgreSQL认为name是关键字,不能使用。但是这也有矛盾的地方。比如uncommited这个关键字和name是一样的级别,但是uncommited就可以用来做别名。这个问题还需要研究。
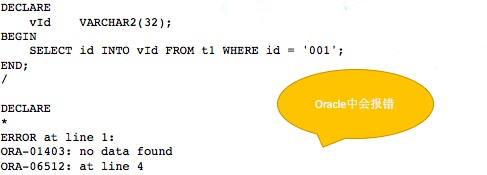
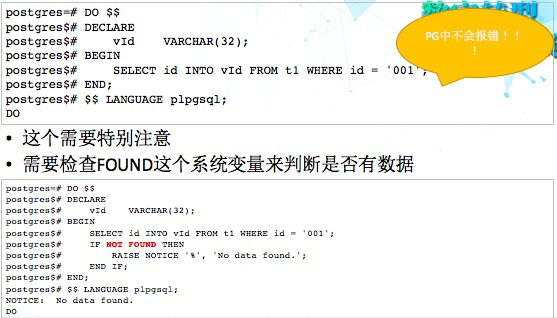
9、SELECT INTO
这个问题也是需要特别注意,如果本身的代码没有这方面的错误处理,很有可能就会导致结果错误。
10、UPDATE语句问题
UPDATE语句中不能使用下面这个在Oracle可能很常见的写法。INSERT也一样。这个也不能说谁对谁错,因为本身SQL标准中就不支持这样的写法的,PostgreSQL只是遵从了这个标准而已。

11、Oracle访问PostgreSQL
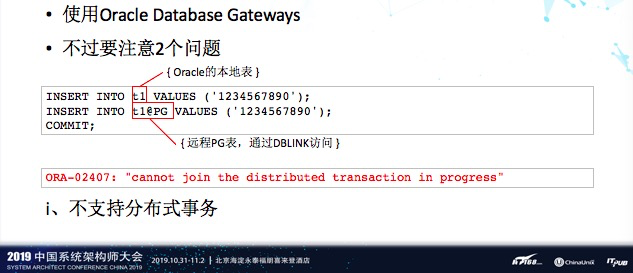
在我们的系统中是有很多通过DBLINK来进行数据交互的,那迁移不太可能所有的系统一起签掉,所以原有的DBLINK功能还得继续保留。我们使用的方法是用Oracle Database Gateway。但是这里面有两个问题,1是分布式事务的问题,在Oracle和Oracle之间没有任何问题,是可以做分布式事务的,如果是PostgreSQL,这个时候是不支持的,Database Gateway还不支持异构数据库间的2PC,这个要特别注意。
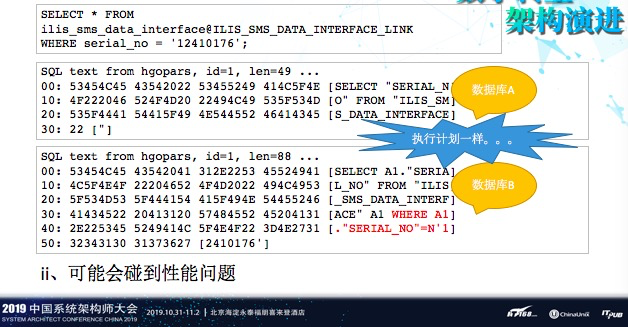
访问的时候还会碰到性能问题,这个问题到目前为止我们也是一直没有解决掉,这个语句非常简单,这个库我们已经给迁走了,迁到PostgreSQL里,通过DBLINK取PostgreSQL里面的数据。
我们发现,在生产环境当中,性能较差,但在测试环境里面性能很好。我们跟踪了一下,发现同样的一个SQL发过去,在Oracle虽然执行计划是一样的,但到达Database Gateway,再由Database Gateway出去后,生产环境它缺少一个WHERE条件。这个问题,我们找Oracle也沟通过好几次,但他们也解决不了。我们用了好多办法去复现测试环境,均告失败,这个问题,也非常诡异,也值得深入研究。
12、PostgreSQL访问Oracle
这是个非常强的现实需求。那我们使用oracle_fdw,Oracle fdw在日常的使用下没有什么问题,而且性能也还不错。但可能会碰到一个错误,发现这个错误的原因主要是Oracle fdw当中使用的事务级别是serializable,那如果有并发更新,就可能会报这样的错误。
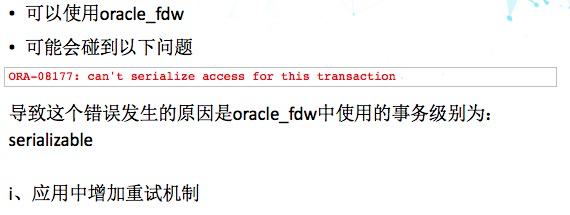
这就需要增加一个重试机制。
不过我们觉得Oracle_fdw事务级别设置的过于严格了,所以我们对源码做了简单的修改,把事务级别降下来.
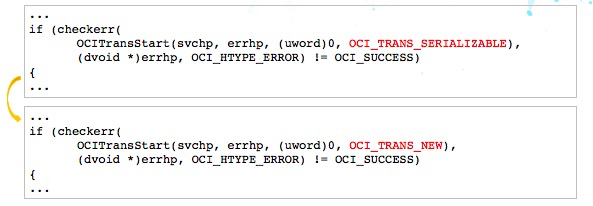
修改后,实际使用中运行良好。
13、空串(”)、NULL问题
空串和NULL也是非常头疼的问题,因为在Oracle当中空串和NULL是等价的,我个人更加偏向于PostgreSQL设计,更严谨。PostgreSQL里面空串是空串,NULL是NULL,但从Oracle牵引过来会碰到很多的问题。
比如说涉及到字符串判断的地方都需要修改,有时候开发不会特别注意这方面的内容。还有涉及到字符串连接的地方都需要修改。另外,所有涉及到字符串转为数值型的都需要修改,空串强制转换会报错。
在我们现在迁移项目中,如果都要修改的话,代码里面差不多有几十万的修改量,这个是非常大的修改量,因为你修改了以后还要重新测试。
我们对PostgreSQL进行了定制化工作,从内核层面使空串与NULL进行等价。
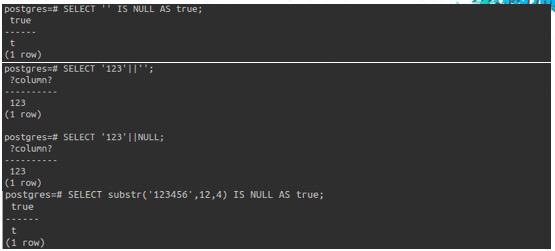
大家可以看到,这是我们修改后的PostgreSQL执行情况,这个时候空串、NULL是等价的。

在做连接的时候,其实也是和Oracle里面的行为是一致的,包括函数的返回,比如说substr,正常应该返回空串,但是在Oracle返回的是NULL,我们修改了以后行为变成一致了。
类型转换,空串的转换也都没有任何问题了。
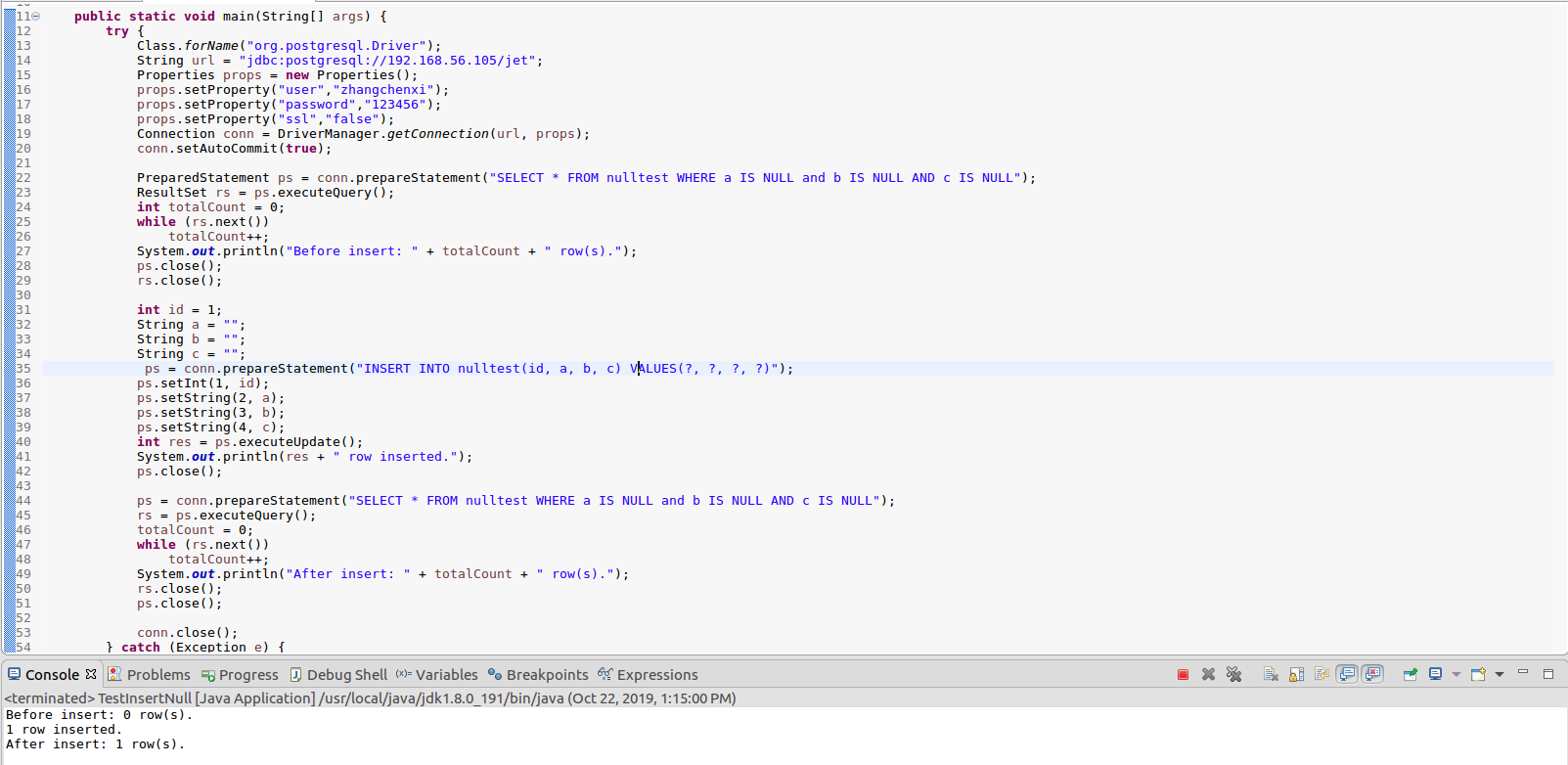
从应用代码当中执行,代码当中包括绑定变量的方式,比如我们先选一下当前有没有NULL值,当前是零,这里是空串,再去执行同样的语句,会发现已经正确插进去了。这个是我们对PostgreSQL本身开源技术上做的一些小优化。
14、SYNONYM问题
PostgreSQL中是没有SYNONYM这个概念的
1、可以通过调整search_path来解决
2、配合使用VIEW
15、列名大小写问题
Oracle中的列名是大写表示的
PostgreSQL中的列名是小写表示的
在使用类似MyBatis这样的工具时,需要将大写转为小写,否则会导致你的列名找不到的问题,这个是需要特别注意的一个地方。
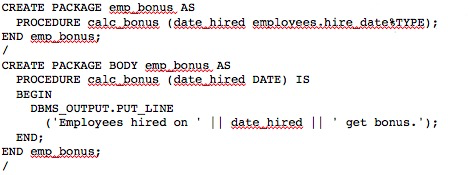
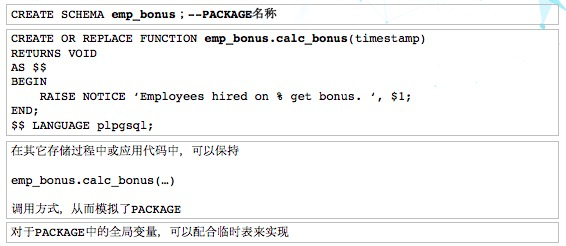
16、如何支持PACKAGE?
PostgreSQL中没有PACKAGE这个概念
我们使用了schema来模拟。这是Oracle官方网站里的一个案例,大家可以自己看一下。
17、其他
其他的还有,decode函数,Wm conca为函数,dual,utl_file,dbms_pipe,dbms_output,package,
我们非常推荐使用orafce开源组件,功能挺强大的。
以上是在实际迁移系统过程中,可能会遇到的各种“坑”点,趟过所有这些“坑”,应用才可以完成生存的第一步:活着!
让应用跑的更好、更快!
在数据库系统里,我认为有两个核心是最重要的。一个是事务管理器,还有一个叫做查询处理器,这两个其实是构成了一个关系与数据库的核心。
其中,代价模型是查询处理器中非常重要的内容,在我们没办法对查询优化器做更多优化的工作时,那我们只能理解系统是怎么来估算执行成本的,那这个对于系统优化也好,SQL优化也好都有非常重要的意义。
(接下来的内容是PostgreSQL中走全表扫描及走索引的成本估算算法的详细介绍,因内容比较难懂,感兴趣的可下载其PPT进行研读)。
另外一种优化方式
SELECT phone
FROM lcaddress
WHERE customerno IN (
SELECT insuredno
FROM lcinsured
WHERE contno = ‘100005522831’
AND sequenceno = 1
AND addressno = lcaddress.addressno
);
这个在Oracle里面只要几十毫秒,但是POSTGRESQL里面几十秒才出来。
对SQL进行简单重写
SELECT phone
FROM lcaddress
WHERE (customerno, addressno) IN (
SELECT insuredno, addressno
FROM lcinsured
WHERE contno = ‘100005522831’
AND sequenceno = 1
);
重写后SQL在Oracle在Plan不变,在PostgreSQL当中的执行计划,已经与Oracle一致了。所以我们方式就是说以Oracle的执行计划为蓝本来优化SQL。
让应用跑的更稳定、更安全
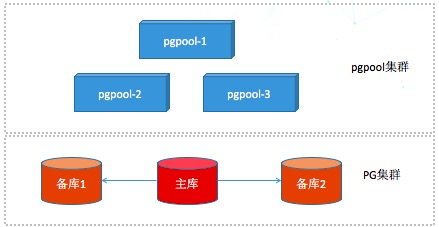
PostgreSQL高可用架构,通过PGpool进行数据库的负载均衡,一主两备的方式,主库与备库间通过stream的方式实现实时同步(配置策略为备库1和备库2只要有一个写完成主库就返回,防止因为某些原因备库1\2均不能用时将主库hang住,提高可用性),这样在备库当中任何一个出现问题不会影响主库的数。
最后一句,备份重如山,对于搞IT的,尤其是做数据库的,这个要时刻牢记在心,谢谢大家!