

图片由 thinboyfatter 在 Flickr (CC 2.0)
假设你有一个学校项目要完成。你需要写一些你不知道的特定主题。所以, 你去图书馆, 坐在一排书, 覆盖主题。您可以搜索该行, 阅读书籍, 并找出您需要什么。你可能需要从一本基本的书开始, 建立一些关于这个主题的关键方面的知识, 然后你可以在更高级的书籍索引中查找这些元素, 来回翻转, 直到你掌握了这个主题。
就像你即将开始, 在徘徊一个大学教授与多年的知识存储在她的脑海中。她已经读了图书馆里那个书架上的所有书, 事实上, 她写了一些。她坐在你的桌子上说: “我是一个主题 x 的专家问我什么。
通过提问, 你不仅可以利用她指尖上的事实, 而且还能让她在这些年间建立起的联系。你可以用你的语言技巧快速地掌握知识的核心来质疑她。如果她没有到达, 你就会用书本中的查找机制从头开始为自己构建那些: 章节标题和索引。
好吧, 这是一个稍微笨拙的类比, 因为你必须相信这个教授有一个最新的, 全面的知识, 是没有偏见。而且, 由于人的能力是有限的, 虽然她可能是这个项目的专家, 她将无法帮助你写一篇关于行星物理学的论文, 或在苏格兰的地理和中世纪的建筑, 这也是下周 (你是在一所学校高 achievers!你需要追捕一些不同的人去问那些问题, 或者再去找些书。
如果你跳起来说 “使用互联网!”, 考虑它是如何工作的。它更像是图书馆还是像教授?在 web 上, 信息存储在一系列网站的一组页面中。它类似于库, 因为你必须找到最相关的页面来确定最重要的事实, 并揭示突出的术语, 以进入额外的 web 搜索, 以找到更多的信息。你正在努力提取和连接的关键事实, 即使你不必离开房子, 坐公交车, 因为你的搜索引擎提供了你需要阅读的页面, 而不是你想知道的答案。
搜索引擎
这给我们带来了搜索引擎的能力。在表面上, 它似乎理解一个问题足以回答它与传播的关键主题的信息。询问谷歌关于演员加里. 老人, 你会得到的东西像下面的屏幕截图, 其中返回的结果包括一系列不同的资源 (图像, 视频, 文本) 加上一个信息框从维基百科的一些关键事实和链接到相关信息, 如他的电影和他的出生地。您还将根据其他人所做的搜索, 查看可能与之相关的人员和问题列表。
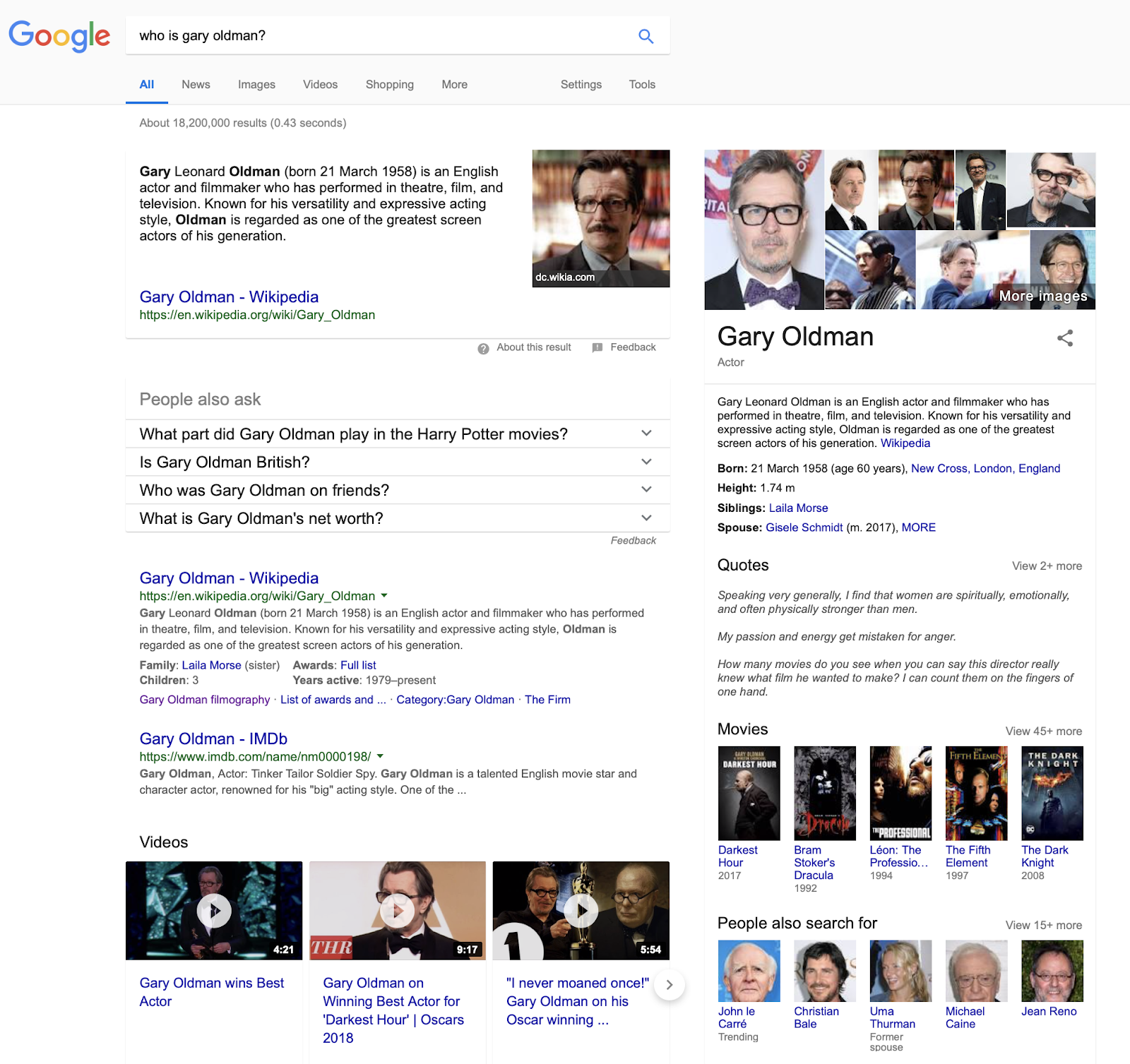
我上面显示的信息框来自一个产品, 称为 “本文是一个有用的资源, 但没有关于产品如何工作的官方信息。我们知道, 它吸引了诸如维基百科这样的公共资源, 也集结了人们在网络上搜索的数据, 并以某种程度的人力投入形式进行了策划。仅凭这个原因, 谷歌的知识图表可以说是有限的, 尤其是当你认为维基百科的数据只限于值得注意的人、公司和地点, 而不是每个人都记录在网上。该产品被驱动为谷歌广告客户的服务, 并提供内容供谷歌主页使用的智能扬声器使用。
举个例子, 如果你问 “加里?老人结婚了吗?” 你可能不会得到一个直接的答案, 但是, 相反, 你会看到一组链接, 跟随和阅读, 而不是像从我们的类比的图书馆书行。这当然是在信息框中提供的任何问题超出了侧面的情况。我最近注意到, 谷歌现在能够提供一些直接的答案。例如, 如果你搜索它 “是加里老人是唯一的孩子吗?你会拿回一个关于他妹妹(莱拉莫尔斯) 的信息箱。但是, 这些信息来自 Google 是否对您的问题有一个直接的回答, 它的形式是在 web 上找到的某处文本的字符串, 例如 “莱拉莫尔斯是加里。
如果还没有写下来, 谷歌无法从其他信息中推断出人类的方式 (例如, 找出他母亲生了多少孩子)。
对于这种推断, 我们需要回到我们的虚构的教授或找到一种技术, 可以自动确定的答案, 建立在网上存储的丰富信息的连接。
介绍 Diffbot
今年 8月, Diffbot硅谷初创公司发布了他们所称的 Diffbot 知识图 (DKG), 为智能应用提供 “知识即服务”。他们使用机器学习、计算机视觉和自然语言处理的组合, 将整个 web 的内容刮到知识图中。请注意, 这不像 Google 产品的 “知识图”, 而是指更一般的概念 (如果你不确定什么是知识图表, 我以前在一篇文章中写的 “跆拳道” 是一个知识图?总结, 知识图是一个单一的、结构化的数据源, 它存储为具有语义 (自描述性) 属性和对推断的支持的图形。
Diffbot 使用一个名为Gigablast的搜索引擎来抓取和存储整个网站, 收集各种格式的文档, 如 HTML 网页和 PDF 附件。然后, Diffbot 使用计算机视觉来了解这些文档的结构, 将它们分解为结构元素, 如页眉、文本块、表等。在计算出结构后, 使用自然语言处理和机器学习的组合来分析内容, 将事实、数字和关系与人的准确性相结合, 并建立一个知识语料库, 这是添加到 DKG。
Diffbot 有效地捕获数据库中的 web 知识, 并将其连接起来, 以便它可以用于提供查询所构成的复杂问题的答案
在发布的时候, DKG 包含了超过1个事实和100亿个实体, 这比谷歌知识图产品大了将近500倍, 并且一个月增加了1亿多个事实。DKG 是完全自主的, 仅使用人工智能构建, 而不是依赖于手动策划的水平。这种方法的价值在于, 知识图表可以不断地重建, 从头开始, 保持 DKG 数据的新鲜和准确, 因为不一致或被认为是纯不准确的来源可以简单地排除, 其他人添加。在反对 “假消息” 的战斗中, 这是一项有用的武器。
在图形中存储知识使其快速可用: 可以生成使用所连接数据的产品。知识图是最接近的一台计算机可以通过相关概念和项目相互关联的上下文了解我们的世界是如何工作的。如果您正在构建一个能够理解复杂查询的 AI 助手, 则需要了解复杂的关系。
例子
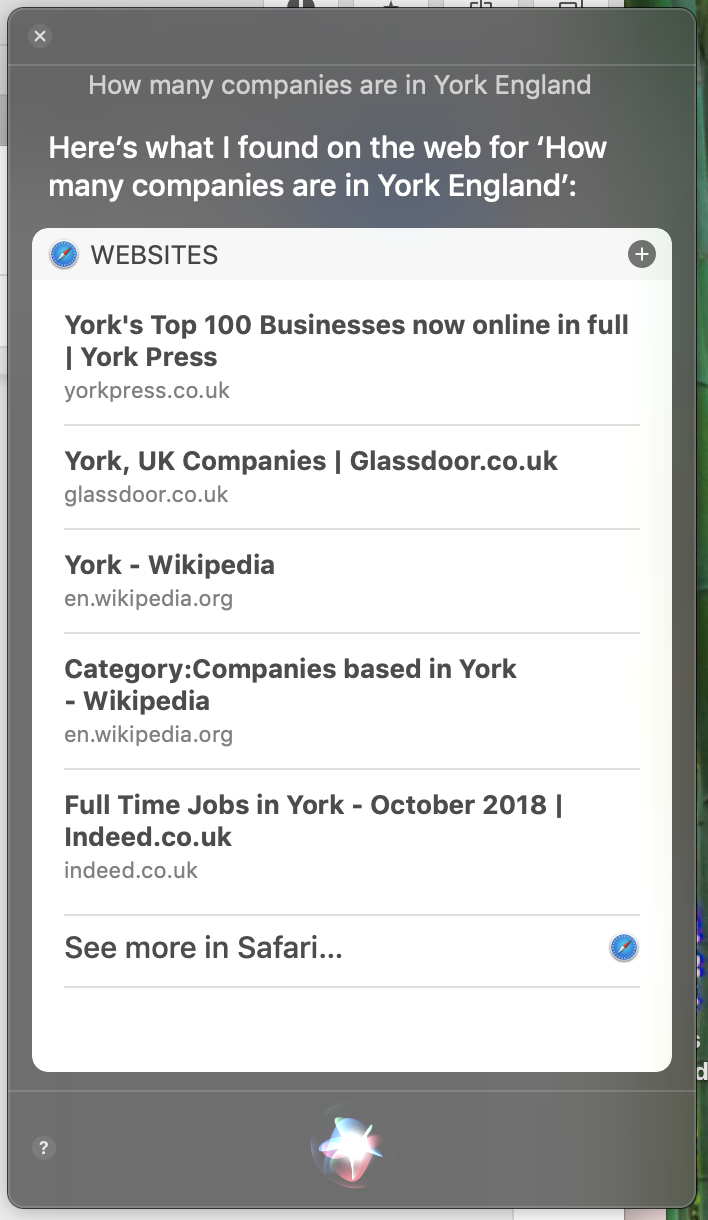
让我们关闭一个示例用例。向您的 AI 助手 (Siri、Alexa、Google 助手) 询问以下内容: “纽约有多少家公司?
如果你收到一个答案, 它是一个从一个网页被刮掉的地方, 是基于一串在线找到的文本和存储作为事实。如果你问的是更晦涩的问题 “在英国的约克有多少家公司?” 你可能不会得到一个直接的答案, 但一个列出了一组链接的地方, 你可以找到的信息 (虽然它不是保证)。以下是 Siri 在我最近询问时的响应屏幕:
回到纽约, 问一个多方面的问题:
“纽约有多少家公司雇佣有 JavaScript 技能的人?”
同样, 助理无法回答, 因为它没有记录为 scrapable 文本在网页上, 他们没有能力, 根据他们的其他知识来解决答案。
但是, 如果助手绘制了一个知识图的内容, 让它理解 “事物” 和这些事物之间的联系, 那么它就能够使用它的本体来解决:
Companies have:
Locations
Employees
Employees have:
Employers
Skills
Skills have:
People who have them这就赋予了理解问题的能力, 并利用主题的上下文知识来找到答案。这就是 Diffbot 的知识图正在开发的目的。
Diffbot 的创始人兼首席执行官迈克. 董说: “我们构建的是第一个知识图, 组织可以使用它来访问 web 上包含的全部信息。解锁这些数据, 让组织能够即时访问这些深度连接, 完全改变我们所知道的基于知识的工作。您可以在纽约市的 “莱利媒体的岩层数据会议” 中看到Mike 董建华最近的视频, 他描述了使用大型知识图实现业务处理自动化的未来。
点击查看 Diffbot 的更多信息!
-
文章XConomy:与谷歌媲美, 网络挖掘启动 Diffbot 打开知识图到所有
闭幕评论
我想指出的是, 我没有被 Diffbot 写这篇文章, 我不隶属于他们以任何方式。知识图表是一个持久的兴趣和一些我以前写过的东西, 当我在GRAKN 工作。AI。这种技术看起来像一个伟大的方式, 以一种新的方式与知识工作, 我希望能写更多关于 Diffbot 很快通过采取它的旋转和写一个教程关于它。
让我知道你在评论中的想法, 如果你自己试过, 你是怎么开始的?