
在本文中, 我将做回归分析与 Oracle 数据挖掘。
数据科学和机器学习今天很受欢迎。但这些科目需要广泛的知识和应用专业知识。我们可以通过各种公司开发的各种产品和软件解决这些问题。在 Oracle 中, 将解决这些问题的方法和算法呈现给使用该 DBMS_DATA_MINING 包的用户。
通过该 DBMS_DATA_MINING 包, 我们可以创建诸如聚类、分类、回归、异常检测、特征提取和关联等模型。我们可以用我们创建的模型来解释效率。我们从这些模型获得的结果可以放到我们的业务场景中。
在 DBMS_DATA_MINING Oracle 数据库中默认情况下不出现该包。因此, 必须首先安装此程序包。通过跟踪此链接, 您可以使用 Oracle 数据挖掘设置数据库。
安装 Oracle 数据挖掘包后, 将创建三个新字典表:
SELECT * FROM ALL_MINING_MODELS;
SELECT * FROM ALL_MINING_MODEL_SETTINGS;
SELECT * FROM ALL_MINING_MODEL_ATTRIBUTES;该 ALL_MINING_MODELS 表包含有关所有模型的信息。
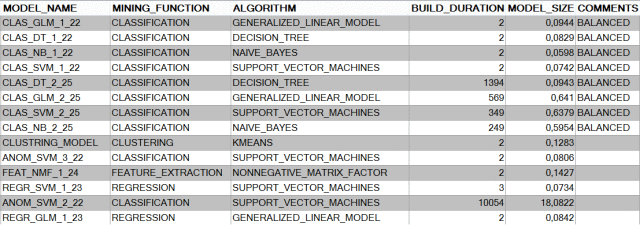
ALL_MINING_MODELS_SETTINGS和 ALL_MINING_MODELS_ATTRIBUTES 表包含有关这些模型的参数和特定详细信息。
现在, 让我们准备一个易于理解的数据集做市场篮分析。
我们需要一个数据集来做这个例子。我们将通过从kaggle下载的BOSTON_HOUSING数据集来执行此示例。
让我们首先检查BOSTON_HOUSING数据集。
| 列名 | 描述 | 数据类型 |
| 犯罪大 | 按城镇计算的人均犯罪率。 | 数量 |
| 锌 | 占地面积超过2.5万平方呎的住宅用地比例 | 数量 |
| 梧桐 | 每个城镇非零售业务英亩的比例。 | 数量 |
| 查斯 | 查尔斯河虚变量 (= 1 如果道界限河; 0)。 | 数量 |
| Nox | 氮氧化物浓度 (每1000万件) |
数量
现在, 我们已经查看了数据集的详细信息, 让我们加载我们下载到 Oracle 数据库的BOSTON_HOUSING 。
首先, 创建 Oracle 表, 我们将在其中加载我们下载的数据集 (培训. csv)。
CREATE TABLE BOSTON_HOUSING
(
ID NUMBER,
CRIM NUMBER,
ZN NUMBER,
INDUS NUMBER,
CHAS NUMBER,
NOX NUMBER,
RM NUMBER,
AGE NUMBER,
DIS NUMBER,
RAD NUMBER,
TAX NUMBER,
PTRATIO NUMBER,
BLACK NUMBER,
LSTAT NUMBER,
MEDV NUMBER
);现在, 我们已经创建了我们的表, 我们将加载数据集, 我们下载为 CSV 到表中;我们有多种方法来做到这一点:
-
使用 Oracle 外部表
-
使用 Oracle SQL 加载程序
-
使用 sql PL/sql 编辑器 (Oracle sql 开发人员、蟾蜍、PL/sql 开发人员等)
我将加载与我使用的编辑器的数据集。我用蟾蜍做编辑。使用蟾蜍, 您可以按照以下步骤执行数据加载过程。
数据库>导入>导入表数据
您可能不使用此编辑器, 因为蟾蜍是有偿的。此功能对其他编辑器是可用的, 因此您可以轻松地与其他编辑器一起使用。例如, 对于 oracle sql 开发人员来说, 您可以使用 oracle sql 开发人员按如下方式加载数据。
SELECT * FROM BOSTON_HOUSING;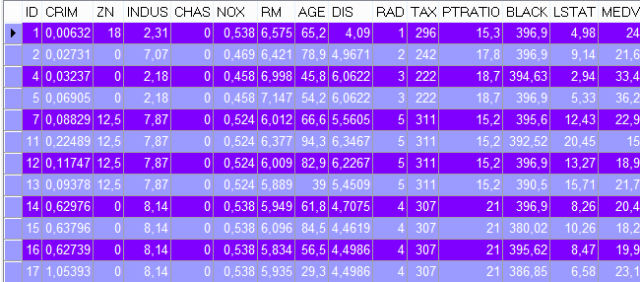 我们已经完成了数据集安装过程。
我们已经完成了数据集安装过程。
当我们观察数据时, 我们会根据房屋的各种特征来了解细节。每一行都包含有关房子的具体特征的信息。本表介绍了回归分析的基本参数。在这个表中, 我们预测回归分析的结果。MEDV 列是我们将在该分析中使用的目标变量。
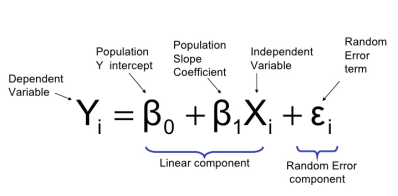
在开始回归分析之前, 我将给出一些关于这个算法的信息, 以更好地理解这个主题。
DBMS_DATA_MINING 包由广义线性模型算法实现。要使用这个算法, 我们需要定义一些参数cheeli/wp-内容/上传/2018/10/odmreg. png 现在让我们创建一个表, 在那里我们将读取算法设置。
CREATE TABLE SETTINGS_GLM
AS
SELECT *
FROM TABLE (DBMS_DATA_MINING.GET_DEFAULT_SETTINGS)
WHERE SETTING_NAME LIKE '%GLM%';
BEGIN
INSERT INTO SETTINGS_GLM
VALUES (DBMS_DATA_MINING.ALGO_NAME, 'ALGO_GENERALIZED_LINEAR_MODEL');
INSERT INTO SETTINGS_GLM
VALUES (DBMS_DATA_MINING.PREP_AUTO, 'ON');
INSERT INTO SETTINGS_GLM
VALUES (
DBMS_DATA_MINING.GLMS_RIDGE_REGRESSION,
'GLMS_RIDGE_REG_DISABLE');
INSERT INTO SETTINGS_GLM
VALUES (
DBMS_DATA_MINING.ODMS_MISSING_VALUE_TREATMENT,
'ODMS_MISSING_VALUE_MEAN_MODE');
COMMIT;
END;是的, 我们创建了表来读取算法参数。现在我们可以继续创建我们的模型了。
CREATE OR REPLACE VIEW VW_BOSTON_HOUSING AS SELECT * FROM BOSTON_HOUSING;
BEGIN
DBMS_DATA_MINING.CREATE_MODEL(
model_name => 'MD_GLM_MODEL',
mining_function => DBMS_DATA_MINING.REGRESSION,
data_table_name => 'VW_BOSTON_HOUSING',
case_id_column_name => 'ID',
target_column_name => 'MEDV',
settings_table_name => 'SETTINGS_GLM');
END;我们的模型已经发生了, 现在从字典中看看我们模型的细节。
SELECT MODEL_NAME,
ALGORITHM,
COMMENTS,
CREATION_DATE,
MINING_FUNCTION,
MODEL_SIZE
FROM ALL_MINING_MODELS
WHERE MODEL_NAME = 'MD_GLM_MODEL';
SELECT SETTING_NAME, SETTING_VALUE
FROM ALL_MINING_MODEL_SETTINGS
WHERE MODEL_NAME = 'MD_GLM_MODEL';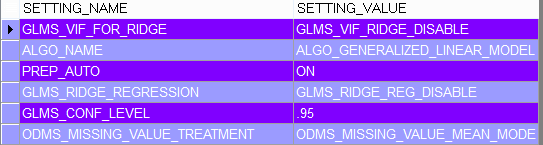 我们创建的回归模型的方差分析表可以如下所示访问。
我们创建的回归模型的方差分析表可以如下所示访问。
SELECT * FROM
TABLE (DBMS_DATA_MINING.GET_MODEL_DETAILS_GLM ('MD_GLM_MODEL')); 让我们看看我们如何可以测试我们的模型现在。首先, 我们创建了需要加载测试的表. csv 数据, 我们已经从 kaggle 下载, 我们导入其中的数据。
让我们看看我们如何可以测试我们的模型现在。首先, 我们创建了需要加载测试的表. csv 数据, 我们已经从 kaggle 下载, 我们导入其中的数据。
CREATE TABLE BOSTON_HOUSING_TEST
(
ID NUMBER,
CRIM NUMBER,
ZN NUMBER,
INDUS NUMBER,
CHAS NUMBER,
NOX NUMBER,
RM NUMBER,
AGE NUMBER,
DIS NUMBER,
RAD NUMBER,
TAX NUMBER,
PTRATIO NUMBER,
BLACK NUMBER,
LSTAT NUMBER,
MEDV NUMBER
);数据库– > 导入– > 导入表数据 (测试. csv)
SELECT * FROM BOSTON_HOUSING_TEST; 现在运行我们用测试数据创建的模型并查看结果。
现在运行我们用测试数据创建的模型并查看结果。
SELECT T.*,
PREDICTION (MD_GLM_MODEL USING *) MODEL_PREDICT_RESPONSE
FROM BOSTON_HOUSING_TEST T;