
在上一篇文章中,我们介绍了深度学习和神经网络。在这里,我们将探讨如何根据我们想要解决的任务来设计网络。
使用神经网络时,确实需要处理大量参数和拓扑选择。我应该设置多少个隐藏图层?他们应该使用什么激活功能?学习率的好值是什么?我应该使用经典的多层神经网络、卷积神经网络 (CNN)、循环神经网络 (RNN) 还是其他可用的体系结构之一?在决定使用这些技术解决问题时,这些问题只是冰山一角。
您可能还喜欢:
所有您需要了解的神经网络:第 1 部分
有很多其他的参数,算法和技术,你将不得不猜测和尝试之前,看到某种体面的结果。不幸的是,没有这方面的好蓝图。大多数时候,从无休止的试验和错误实验的经验可以给你一些有用的提示。
但是,有一件事可能比其他事情更清晰:输入和输出维度和映射。毕竟,第一个(输入)和最后一个(输出)层是网络与外界的接口,其API以一种说话方式。
如果您仔细设计了这两个层,以及如何将培训集的输入和输出映射到它们,那么,您可以保留训练集并根据需要重用它,同时更改许多其他内容,例如:
- 隐藏图层的数量
- 网络类型
- 激活功能
- 学习率
- 数十个其他参数
- (但也)编程语言
- (甚至)深度学习库或框架
我知道我可能错过了一些其他的东西
请记住:无论问题是什么,您都需要考虑如何构建训练集以及输入和输出对列表,以便网络学习和概括解决方案。
让我们看一个例子。一个经典的起点是MNIST数据集,它在某种程度上被认为是深度学习路径中的一种”你好世界”。嗯,这远不止于此。它就像一个参考示例,您可以根据该示例测试新的网络范例或技术。
那么这是什么MNIST?它是一个包含 70,000 个 28×28 像素的图像的数据集,表示手写的 0-9 位数字。60,000 是训练集的一部分,用于训练网络,而其余 10,000 是测试集的一部分,用于测量网络如何真正学习(实际上,这组被排除在培训之外,扮演”第三方法官”的角色。
在此数据集中,我们将找到可能如下所示的输入(_image)和输出对(=0-9 分类):

但是,正如我们在上一篇文章中所看到的,每个输入和输出在提交到网络时都必须是二进制形式,不仅用于培训,而且在测试阶段。
那么,我们如何把上述样本(人类很容易解释)转换为适合神经模型的二进制模式呢?
嗯,我们能找到很多方法来完成这个任务
首先,我们需要关注输入和输出数据的数据类型。在这种情况下,我们有图像(即二维矩阵)作为输入,而作为输出,我们有一个离散值,只有 10 个机会。
很显然,至少在这个特定情况下,找到输出的模式比输入要容易得多,所以我们从前者开始。
在二进制模式中映射此类输出的常见方法是在输出层中使用 10 个节点(通常 N,其中 N 是分类任务中的可能输出数),将每个节点与可能的结果相关联,然后只启动其中一个节点,这是与结果相对应的。
这样,我们为每个输出提供了以下二进制表示形式

关于输入,一个非常基本的方法包括”序列化”二维图像矩阵的每一行。
例如,我们有一个 3×3 图像(这很简单,只是为了专注于概念)

我们可以用以下矩阵表示

然后我们可以将其映射到 9 位值 00101010。
返回 MNIST 数据集,其中每个图像是 28×28 像素的图像,我们将有一个由 784 位二进制数字组成的输入。
数据集可以由 70,000 行的序列表示,每个行具有 784(输入)= 10(输出)值。

在这 70,000 个项目中,我们必须拿出一个子集(例如 10,000 个)并将其用于测试数据集,将其他 60,000 项留给培训集。
无论您采用什么机器学习框架,几乎可以肯定的是,您都会发现 MNIST 是首批示例之一。它被认为是非常基本的,你会发现它被打包和组织使用只有几行现成的代码。
这是非常方便的,因为它只是工作,没有麻烦!
但是这种方法可能有缺陷。您可能无法清楚地看到数据集的制作方式。换句话说,当您决定将 MNIST 中使用的同一神经网络应用于类似但不同的用例时,可能会遇到一些困难。例如,您有一组 50×50 个图像,分为 2 个类别。如何继续?
我们将从 MNIST 图像开始,但我们将详细了解如何将它们转换为数据集。
由于我们很实用,并且希望看到一些代码运行,我们必须选择一个框架来做到这一点。我们将使用深度学习4j,一个适用于Java语言的深层学习框架。
为了运行第一个 MNIST 示例代码,您可以转到此页面并复制并运行此 Java 代码。有两条关键行过于简洁,无法理解训练和测试数据集的构建方式。
DataSetIterator mnistTrain = new MnistDataSetIterator(batchSize, true, rngSeed);
DataSetIterator mnistTest = new MnistDataSetIterator(batchSize, false, rngSeed);在本教程中,我们将用更详细的代码行替换这些代码行你可以从多个来源和格式下载它,但在这里我们有一个提示。
如果您查看同一 GitHub 存储库中的一些其他 Java 类,例如,在注释中,我们将阅读:
* Data is downloaded from
* wget http://github.com/myleott/mnist_png/raw/master/mnist_png.tar.gz
* followed by tar xzvf mnist_png.tar.gz好的,让我们下载这个并解压缩某处,例如在 /home/<用户>/dl4j/,所以我们有以下情况:
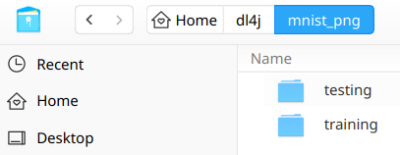
如您所见,数据集被拆分为两个文件夹:训练和测试,每个文件夹包含 10 个子文件夹,标记为 0 到 9,每个文件夹包含数千个(近 6,000 个)手写数字的图像样本,与子文件夹标识的标签对应名字。
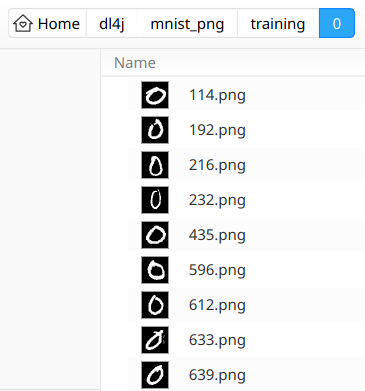
例如,培训/0 子文件夹如下所示:
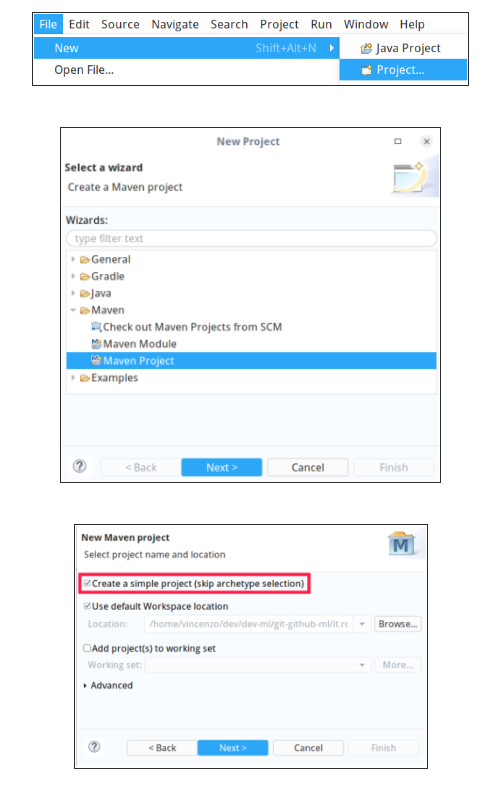
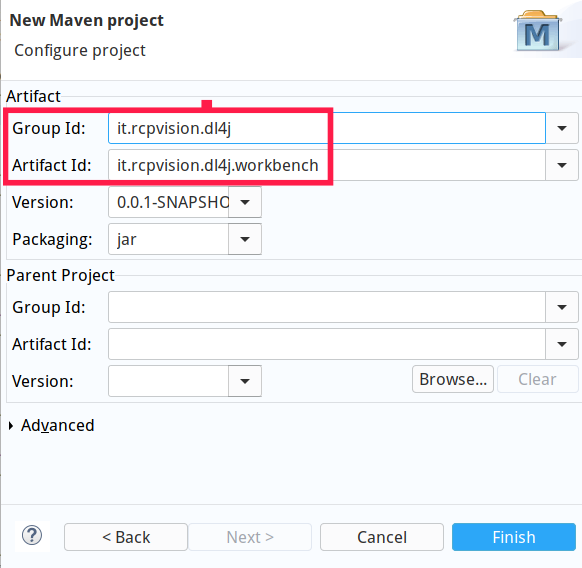
现在,我们已准备好开始使用 Eclipse:让我们从全新的工作区开始,并创建一个新的简单 Maven 项目(跳过原型选择)。
给它一个组ID和一个工件ID,例如它.rcpvision.dl4j和它.rcpvision.dl4j.工作台。
现在打开文件pom.xml,并将依赖项添加到深度学习4j和其他需要的库中。
<dependencies>
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-native-platform</artifactId>
<version>1.0.0-beta4</version>
</dependency>
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-core</artifactId>
<version>1.0.0-beta4</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-jdk14</artifactId>
<version>1.7.26</version>
</dependency>
</dependencies>然后创建一个名为.rcpvision.dl4j.workbench的包,以及一个名为MnistStep1的Java类,该类具有一个空的主方法。
为了避免对后续类的导入产生怀疑,以下是所需的导入:
import java.io.File;
import java.io.IOException;
import java.util.Collections;
import java.util.List;
import java.util.Random;import org.datavec.image.loader.NativeImageLoader;
import org.deeplearning4j.datasets.iterator.impl.ListDataSetIterator;
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.nn.weights.WeightInit;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.nd4j.evaluation.classification.Evaluation;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org利纳格.数据集.api.预处理器.图像预处理量尺;
进口 org.nd4j.linalg.工厂.Nd4j;
进口org.nd4j.linalg.learning.config.Nesterovs;
导入 org.nd4j.linalg.loss 函数.lossfunctions.loss 函数;
进口 org.slf4j.Logger;
进口 org.slf4j.记录器工厂;
让我们定义我们将在代码的其余部分中使用常量:
//The absolute path of the folder containing MNIST training and testing subfolders
private static final String MNIST_DATASET_ROOT_FOLDER = "/home/vincenzo/dl4j/mnist_png/";
//Height and widht in pixel of each image
private static final int HEIGHT = 28;
private static final int WIDTH = 28;
//The total number of images into the training and testing set
private static final int N_SAMPLES_TRAINING = 60000;
private static final int N_SAMPLES_TESTING = 10000;
//The number of possible outcomes of the network for each input,
//correspondent to the 0..9 digit classification
private static final int N_OUTCOMES = 10;现在,由于我们需要构建两个单独的数据集(一个用于培训,另一个用于测试),它们的工作方式相同,并且仅与它们包含的数据不同,因此为两者创建一个可重用的方法是有意义的。
因此,让我们定义一个具有以下签名的方法:
private static DataSetIterator getDataSetIterator(String folderPath, int nSamples) throws IOException第一个参数是包含带有示例的 0..9 子文件夹的文件夹(训练或测试)的绝对路径,第二个参数是文件夹本身中包含的示例映像总数。
在此方法中,我们首先列出 0.9 子文件夹。
File folder = new File(folderPath);
File[] digitFolders = folder.listFiles();然后,我们创建两个对象,帮助我们将每个图像转换为 0.1 输入值序列。
NativeImageLoader nil = new NativeImageLoader(HEIGHT, WIDTH);
ImagePreProcessingScaler scaler = new ImagePreProcessingScaler(0,1);第一个(NativeImageLoader) 将负责读取图像像素的序列为 0.255 整数值(其中 0 为黑色,255 为白色 – 请注意,每个图像都有白色前景和黑色背景)。
第二个(Image 预处理Scaler) 将在 0.1(浮点)范围内缩放上述每个值,以便每 255 个整数值将变为 1。
然后,我们需要准备将保存输入和输出的数组(请记住,我们进入一个泛型方法,该方法将使用相同的方式处理训练和测试集)
INDArray input = Nd4j.create(new int[]{ nSamples, HEIGHT*WIDTH });
INDArray output = Nd4j.create(new int[]{ nSamples, N_OUTCOMES });这样,输入是具有 nSamples 行和 784 列(图像的序列化 28×28 像素)的矩阵,而输出具有相同的行数(此维度始终在输入和输出之间匹配),但 10 列(结果)。
现在是时候扫描每个 0.9 文件夹及其内部的每个图像,将图像和对应标签(它所代表的数字)转换为浮动的 0.1 值,并填充输入和输出矩阵。
int n = 0;
//scan all 0..9 digit subfolders
for (File digitFolder : digitFolders) {
//take note of the digit in processing, since it will be used as a label
int labelDigit = Integer.parseInt(digitFolder.getName());
//scan all the images of the digit in processing
File[] imageFiles = digitFolder.listFiles();
for (File imageFile : imageFiles) {
//read the image as a one dimensional array of 0..255 values
INDArray img = nil.asRowVector(imageFile);
//scale the 0..255 integer values into a 0..1 floating range
//Note that the transform() method returns void, since it updates its input array
scalerputRow(n,img );
在输出矩阵的同一行中,将列对应到标签的触发(设置为 1 值)
输出.put(n,标签数字,1.0 );
行计数器增量
n=;
}
}
现在,通过组合输入和输出矩阵,我们的方法可以构建和返回网络可以使用的 DataSetItatatater。
//Join input and output matrixes into a dataset
DataSet dataSet = new DataSet( input, output );
//Convert the dataset into a list
List<DataSet> listDataSet = dataSet.asList();
//Shuffle its content randomly
Collections.shuffle( listDataSet, new Random(System.currentTimeMillis()) );
//Set a batch size
int batchSize = 10;
//Build and return a dataset iterator that the network can use
DataSetIterator dsi = new ListDataSetIterator<DataSet>( listDataSet, batchSize );
return dsi;有了此方法,我们现在就可以开始使用它与主方法,以便生成训练数据集迭代器。
long t0 = System.currentTimeMillis();
DataSetIterator dsi = getDataSetIterator(MNIST_DATASET_ROOT_FOLDER + "training", N_SAMPLES_TRAINING);现在,我们可以构建网络,就像上面提到的GitHub 存储库中提到的深度学习4j示例一样。
int rngSeed = 123;
int nEpochs = 2; // Number of training epochs
log.info("Build model....");
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(rngSeed) //include a random seed for reproducibility
// use stochastic gradient descent as an optimization algorithm
.updater(new Nesterovs(0.006, 0.9))
.l2(1e-4)
.list()
.layer(new DenseLayer.Builder() //create the first, input layer with xavier initialization
.nIn(HEIGHT*WIDTH)
.nOut(1000)
.activation(Activation.RELU)
.weightInit(WeightInit.XAVIER)
.build())
.layer(new OutputLayer.Builder(LossFunction.NEGATIVELOGLIKELIHOOD) //create hidden layer
.nIn(1000)
.nOut(N_OUTCOMES)
.activation(Activation.SOFTMAX)
.weightInit(WeightInit.XAVIER)
.build())
.build();在这里,我们有一个简单、完全连接的网络,其中包含一个包含 1000 个节点的隐藏层。
然后可以使用我们全新的训练数据集迭代器 (dsi) 对网络进行培训。
MultiLayerNetwork model = new MultiLayerNetwork(conf);
model.init();
//print the score with every 500 iteration
model.setListeners(new ScoreIterationListener(500));
log.info("Train model....");
model.fit(dsi, nEpochs);在此阶段之后(可能需要相当长的时间),我们可以重用我们的方法来构建测试集迭代器并评估此集,同时打印一些有关网络现在如何在测试集上执行的统计信息。
DataSetIterator testDsi = getDataSetIterator( MNIST_DATASET_ROOT_FOLDER + "testing", N_SAMPLES_TESTING);
log.info("Evaluate model....");
Evaluation eval = model.evaluate(testDsi);
log.info(eval.stats());
long t1 = System.currentTimeMillis();
double t = (double)(t1 - t0) / 1000.0;
log.info("\n\nTotal time: "+t+" seconds");如下图所示,即使使用极其简单的网络,我们也能达到 97% 的精度。
完成训练和测试阶段(包括所有时间)少于一个半小时;不错!

