
Neon 对 Postges 逻辑复制功能的支持为基于变更数据捕获的实时流架构开辟了各种有趣的用例。我们之前演示了如何使用 Debezium 通过使用 Redis 作为消息代理来扇出来自 Postgres 的更改。
今天,我们将探讨如何利用 Apache Kafka 和 Kafka Connect 生态系统用于捕获和处理 Neon Postgres 数据库中的更改。具体来说,您将学习如何将更改从 Postgres 流式传输到 Apache Kafka,并使用 ksqlDB 处理这些更改以创建 物化视图,根据数据库更改进行更新。
可以在您的基础设施上运行 Apache Kafka、Kafka Connect 和 ksqlDB;但是,本指南将使用 Confluence Cloud 来托管这些组件,以便我们可以专注于启用数据流和构建物化视图,而不是管理基础设施。
为什么 Apache Kafka 与 Postgres 一起用于物化视图?
Postgres 是一个成熟且经过考验的数据库解决方案,支持物化视图,那么为什么我们需要像 Apache Kafka 这样的消息传递基础设施来处理事件并创建物化视图呢?我们之前解释了在将应用程序与消息代理集成时避免双写问题的重要性,因此让我们重点关注数据流和性能问题。
提醒一下,物化视图存储特定时间点的查询结果。让我们看一个例子。假设您有一个写入量大的应用程序,其中涉及由以下 SQL 表示的两个表:
创建表玩家 (
id 串行主键,
名称文本不为空
);
创建表player_scores(
id 串行主键,
得分 DECIMAL(10, 2) NOT NULL,
player_id 整数引用 玩家(id),
约束 fk_player
外键(player_id)
参考 球员(id)
删除级联时
);此数据库包含一个用于存储玩家信息的 players 表和一个用于跟踪其分数的 player_scores 表。您可能需要创建一个排行榜表来跟踪每个玩家的总得分(使用 SUM 聚合函数< /a>),保留这些更改的历史记录,并实时通知订阅者排行榜的更改。
使用物化视图是跟踪总分的一种选择。以下 SQL 将创建一个物化视图以在 Postgres 中实现此功能:
创建物化视图player_total_scores AS
选择
p.id AS 玩家id,
p.姓名,
COALESCE(SUM(s.score), 0) AS 总分
从
玩家 p
左连接
player_scores s ON p.id = s.player_id
通过...分组
p.id;要使视图保持最新状态,需要在每次插入 player_scores 表后发出 REFRESH MATERIALIZED VIEW。这可能会对性能产生重大影响,不会保留排行榜历史记录,并且您仍然需要可靠地将更改流式传输给下游订阅者,除非您希望他们轮询数据库以获取更改。
一种更具可扩展性和灵活性的方法涉及微服务架构,该架构使用变更数据捕获和逻辑复制将玩家数据和评分事件流式传输到 Apache Kafka 集群进行处理,如以下架构图所示。
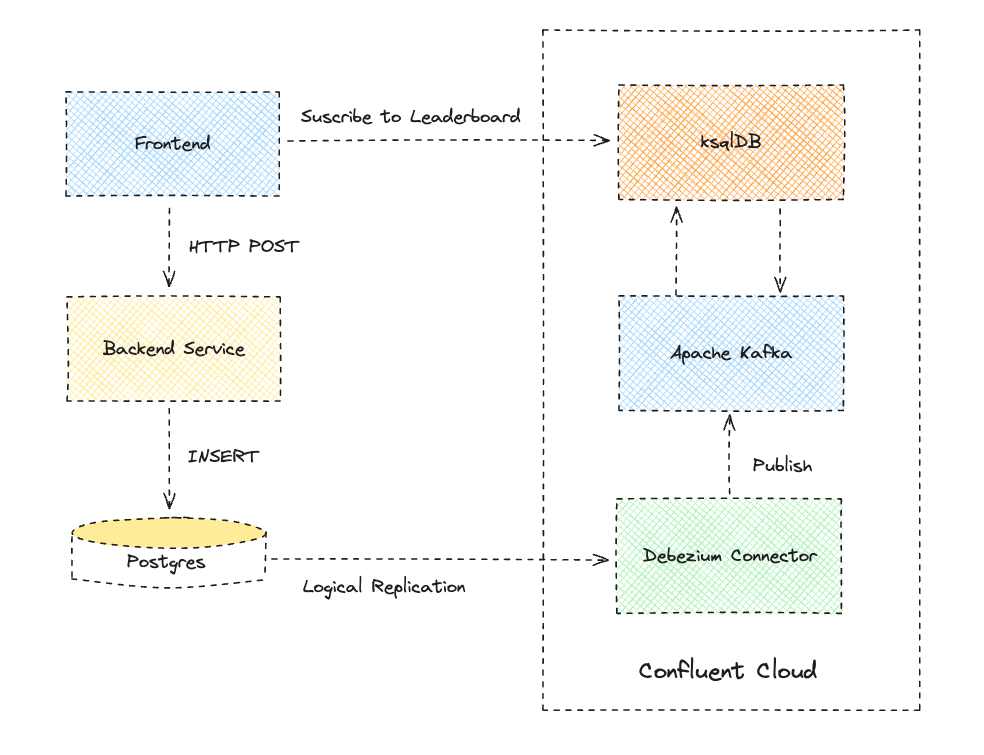
Apache Kafka 集群是代理(或节点)的集合,支持下游订阅者(例如 ksqlDB)并行处理记录。数据在 Apache Kafka 中被组织成主题,主题被分为跨代理复制的分区,以实现高可用性。使用 Apache Kafka 的美妙之处在于,连接器可以从一个系统获取事件并将其接收到其他系统,如果您愿意,还可以返回到 Postgres!您甚至可以将 Kafka 放在 Postgres 前面,以受控方式将评分事件插入数据库。
Neon 和逻辑复制入门
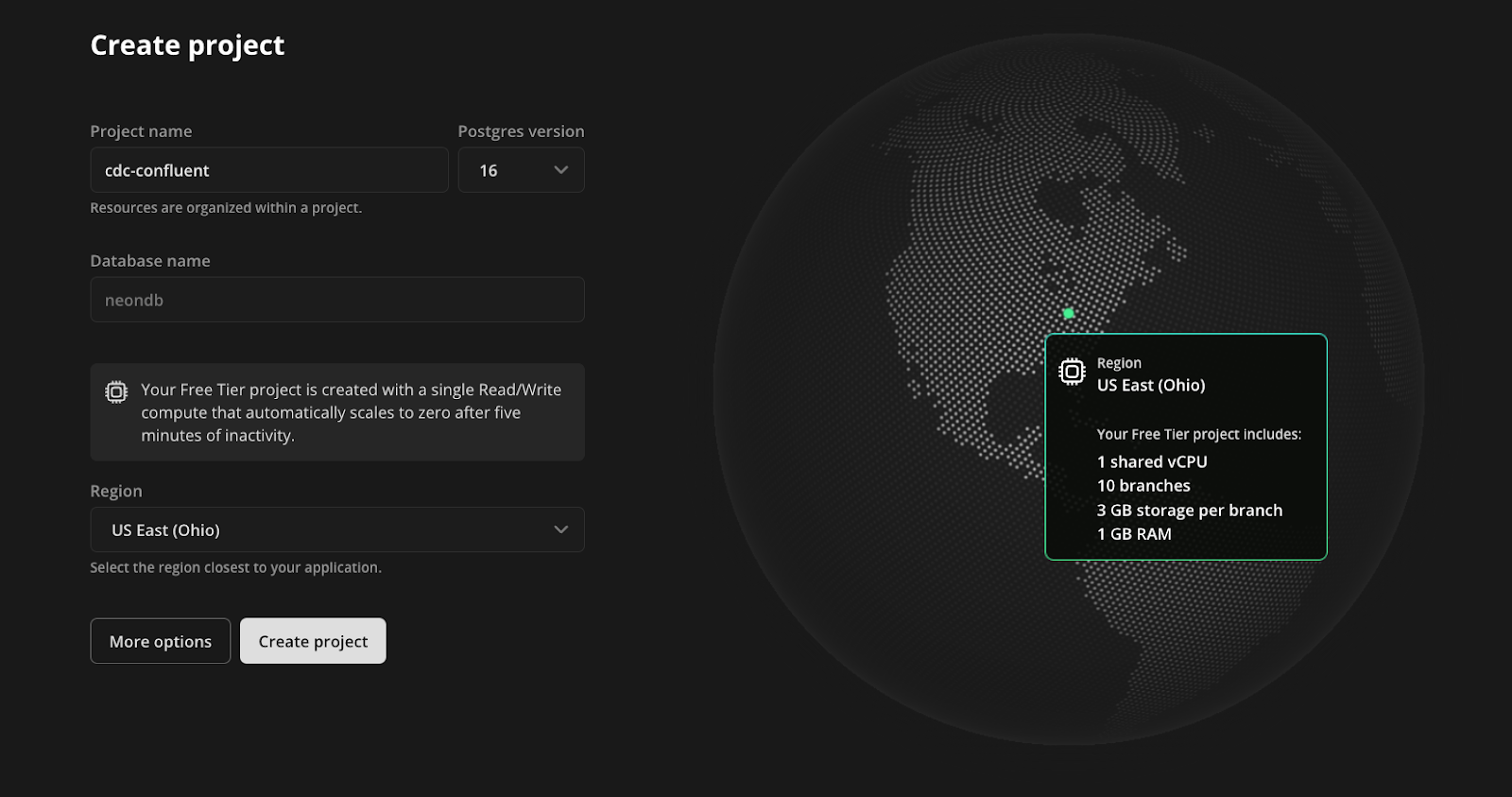
首先,注册 Neon 并创建一个项目。该项目将包含包含 players 和 player_scores 表的 Postgres 数据库:
- 输入项目名称。
- 使用默认数据库名称
neondb。 - 选择最接近您所在位置的区域。
- 点击创建项目。
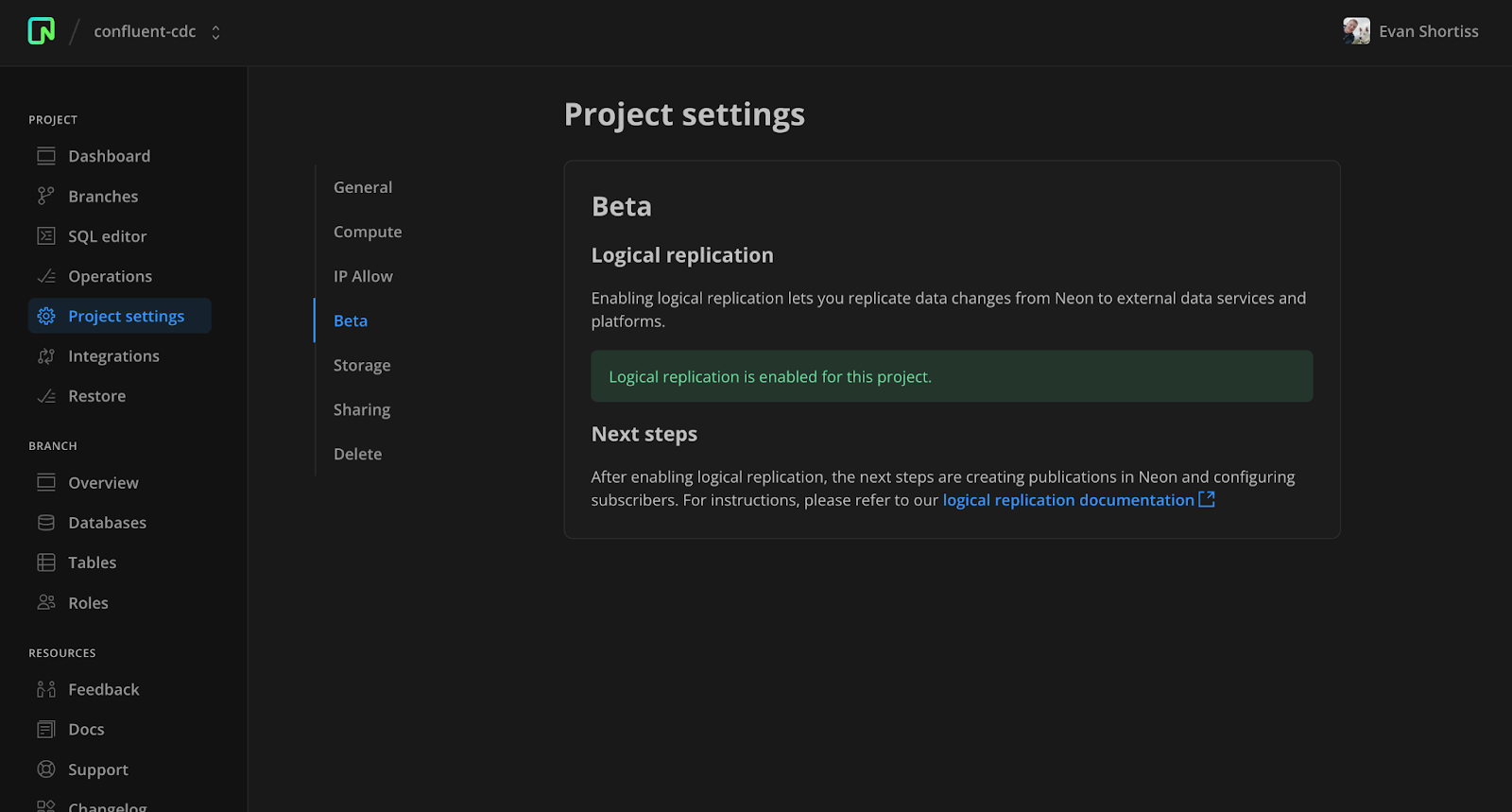
接下来,访问项目设置屏幕的 Beta 部分并启用逻辑复制。请访问我们的文档,查看一整套逻辑复制指南。
使用 Neon 控制台中的 SQL 编辑器在 neondb 数据库中创建两个表:一个用于保存玩家信息,另一个用于保存玩家的分数记录。 player_scores 中的每一行都包含一个通过 ID 引用玩家的外键。
创建表玩家 (
id 串行主键,
名称文本不为空
);
创建表player_scores(
id 串行主键,
得分 DECIMAL(10, 2) NOT NULL,
player_id 整数引用 玩家(id),
约束 fk_player
外键(player_id)
参考 球员(id)
删除级联时
);为这两个表创建一个发布。该出版物定义了将这些表上的哪些操作复制到其他 Postgres 实例或订阅者。您将在 Confluence 的云上部署 Debezium 连接器,该连接器使用此发布来观察指定表中的更改:
为表玩家创建发布 confluence_publication,player_scores;创建一个逻辑复制槽来保留和流式传输更改向订阅者发送预写日志 (WAL)。 Confluence 云上的 Debezium 连接器将使用此插槽来使用 WAL 中的相关更改:
SELECT pg_create_logic_replication_slot('debezium', 'pgoutput');使用 Neon 控制台的角色部分创建一个名为confluence_cdc的新角色。请务必将角色的密码保存在安全的地方,因为它只会显示一次。角色就位后,使用 SQL 编辑器授予其对公共架构的权限:
将 SCHEMA public 的使用权限授予 confluence_cdc;
将 SCHEMA public 中所有表的 SELECT 权限授予 confluence_cdc;
ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO confluence_cdc;现在,您已做好一切准备,可以开始使用 Neon Postgres 数据库中的 players 和 player_scores 表中的更改。
开始在 Confluence Cloud 上使用 Apache Kafka 和 Debezium
本指南假设您是 Confluence Cloud 的新手。如果您是现有用户,则可以修改步骤以与现有环境和 Apache Kafka 集群集成。
登录Confluence Cloud并按照入门流程创建基本的 Apache Kafka 集群。选择最接近您的 Neon Postgres 数据库区域的区域。
配置集群后,在环境屏幕中单击它,然后从下一页的侧面菜单中选择连接器视图。
Confluence 上的 Apache Kafka 支持大量连接器。其中许多都基于各种 OSS Kafka Connect 连接器。在列表中查找并选择 Postgres CDC Source 连接器。该连接器基于我们在使用 Debezium 和 Upstash Redis 的扇出文章中所写的 Debezium 项目。
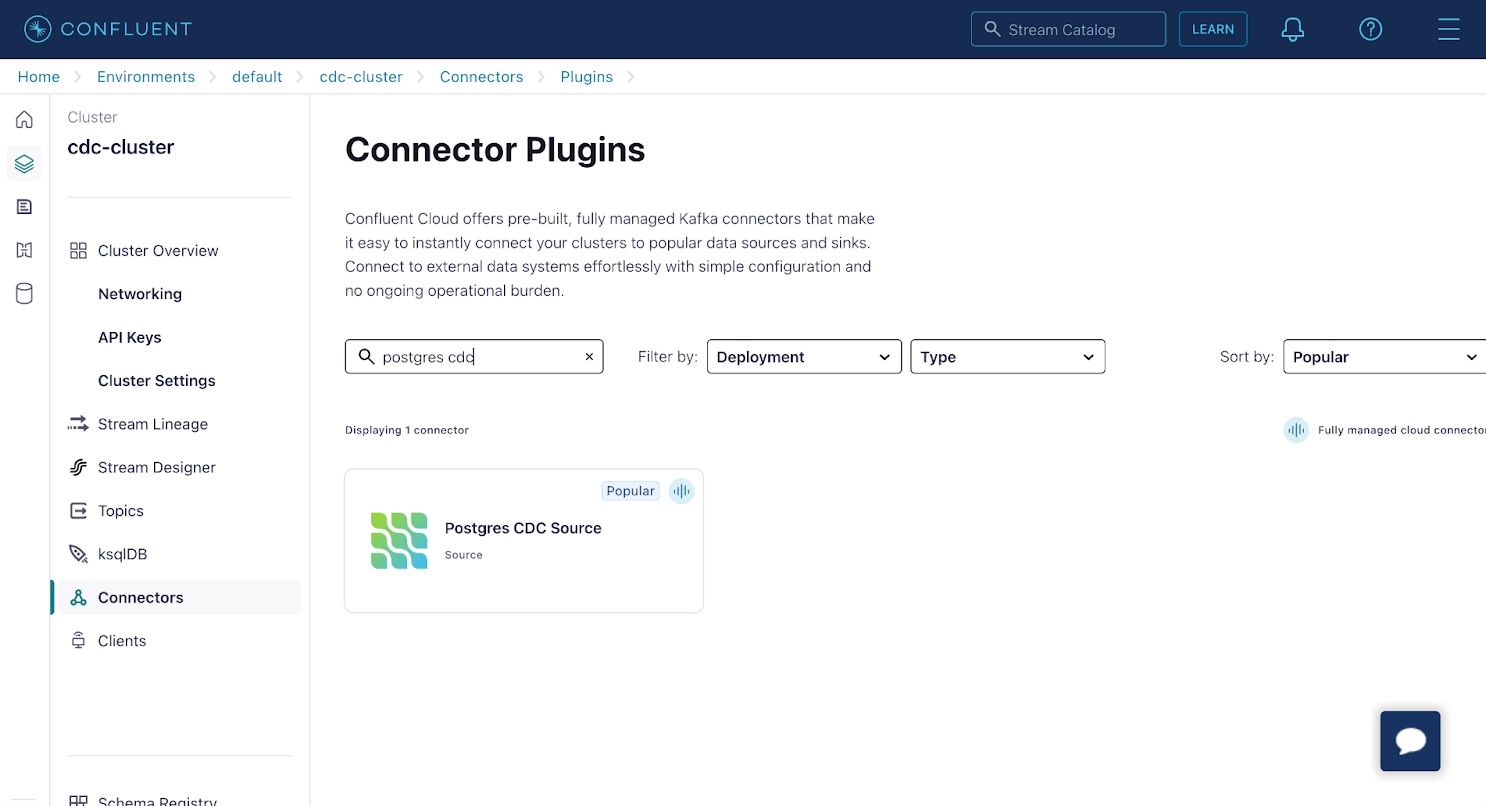 在“添加 Postgres CDC 源连接器”屏幕上:
在“添加 Postgres CDC 源连接器”屏幕上:
- 选择全球访问。
- 点击生成 API 密钥并下载按钮生成 API 密钥和密钥。
- 点击继续
接下来,配置连接器与 Neon 上的 Postgres 数据库之间的连接:
- 数据库名称:
neondb - 数据库服务器名称:
neon - SSL 模式:
需要 - 数据库主机名:在 Neon 控制台上找到它。请参阅我们的文档。
- 数据库端口:
5432 - 数据库用户名:
confluence_cdc - 数据库密码:这是您刚刚创建的
confluence_cdc角色的密码。 - 点击继续。
配置连接器属性。第一个是 Kafka 记录键和值格式。选择以下选项:
- 输出Kafka记录值格式:
JSON_SR - 输出Kafka记录密钥格式:
JSON_SR
JSON_SR 选项会导致更改事件记录架构在 Confluence Cloud 环境的 架构注册表。这对于处理更改数据事件记录至关重要,您很快就会看到。您可以将架构视为 Kafka 主题中记录的类型信息。
展开高级配置并设置以下选项:
- 插槽名称:
debezium - 发布自动创建模式:
已禁用 - 出版物名称:
confluence_publication - 包含的表格:
public.players,public.player_scores
点击继续,接受大小调整和任务的默认值,并为您的连接器命名。完成后,您的连接器将显示在连接器屏幕上。确认其标记为正在运行并且不处于错误状态。如果连接器报告错误,请检查配置属性是否正确。
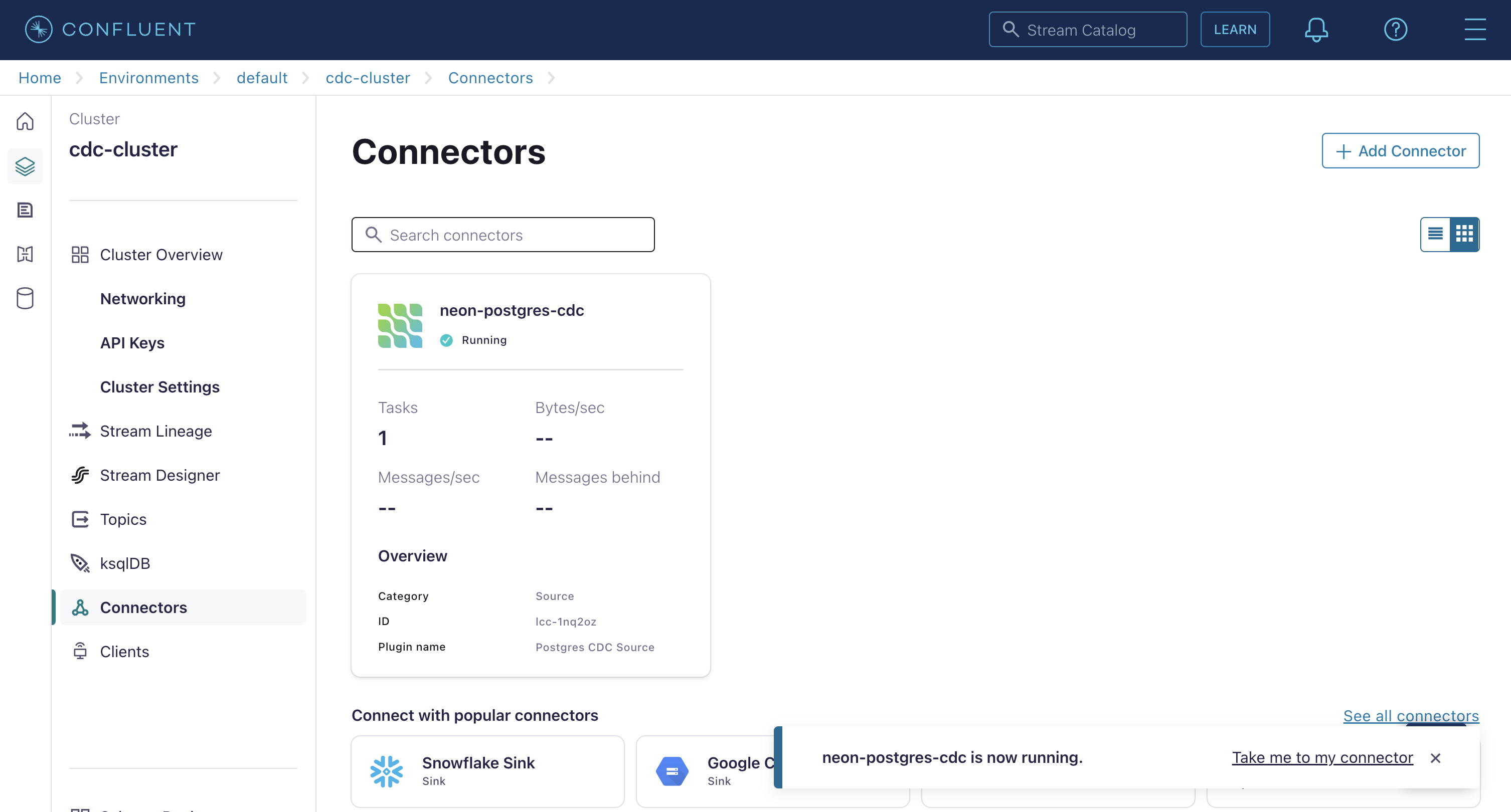
确认变更数据捕获正在工作
使用 Neon 控制台中的 SQL 编辑器,使用以下 SQL 语句将一些球员和得分插入到您的表中:
插入玩家(姓名)值 ('Mario'), ('Peach'), ('Bowser'), ('Luigi'), ('Yoshi' );
INSERT INTO player_scores (player_id, 分数) VALUES
(1, 0.31),
(3, 0.16),
(4, 0.24),
(5, 0.56),
(1, 0.19),
(2, 0.34),
(3, 0.49),
(5, 0.71);返回 Confluence Cloud 控制台并从侧面菜单中选择主题项。您将看到与您的数据库表相对应的两个主题。
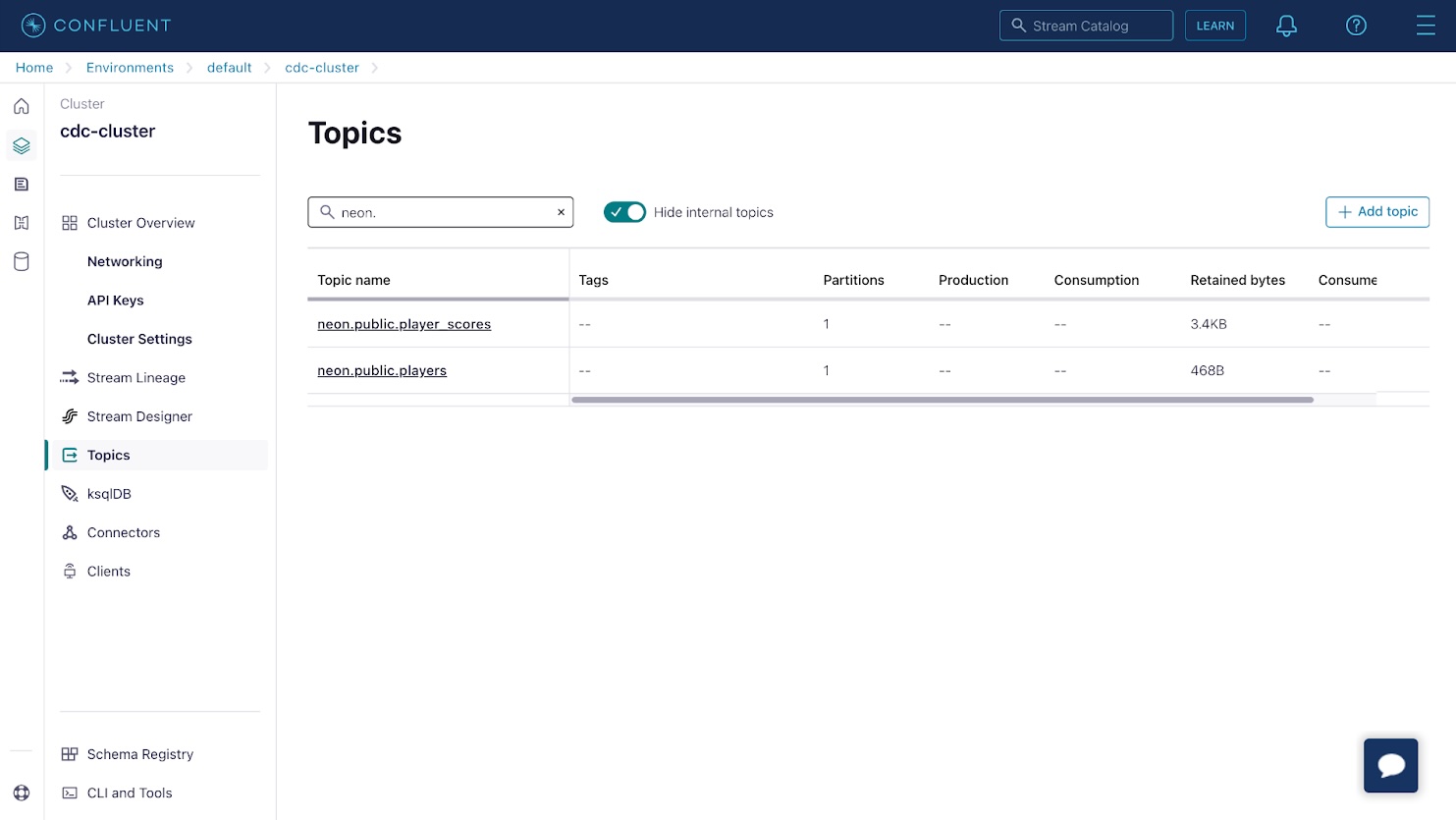
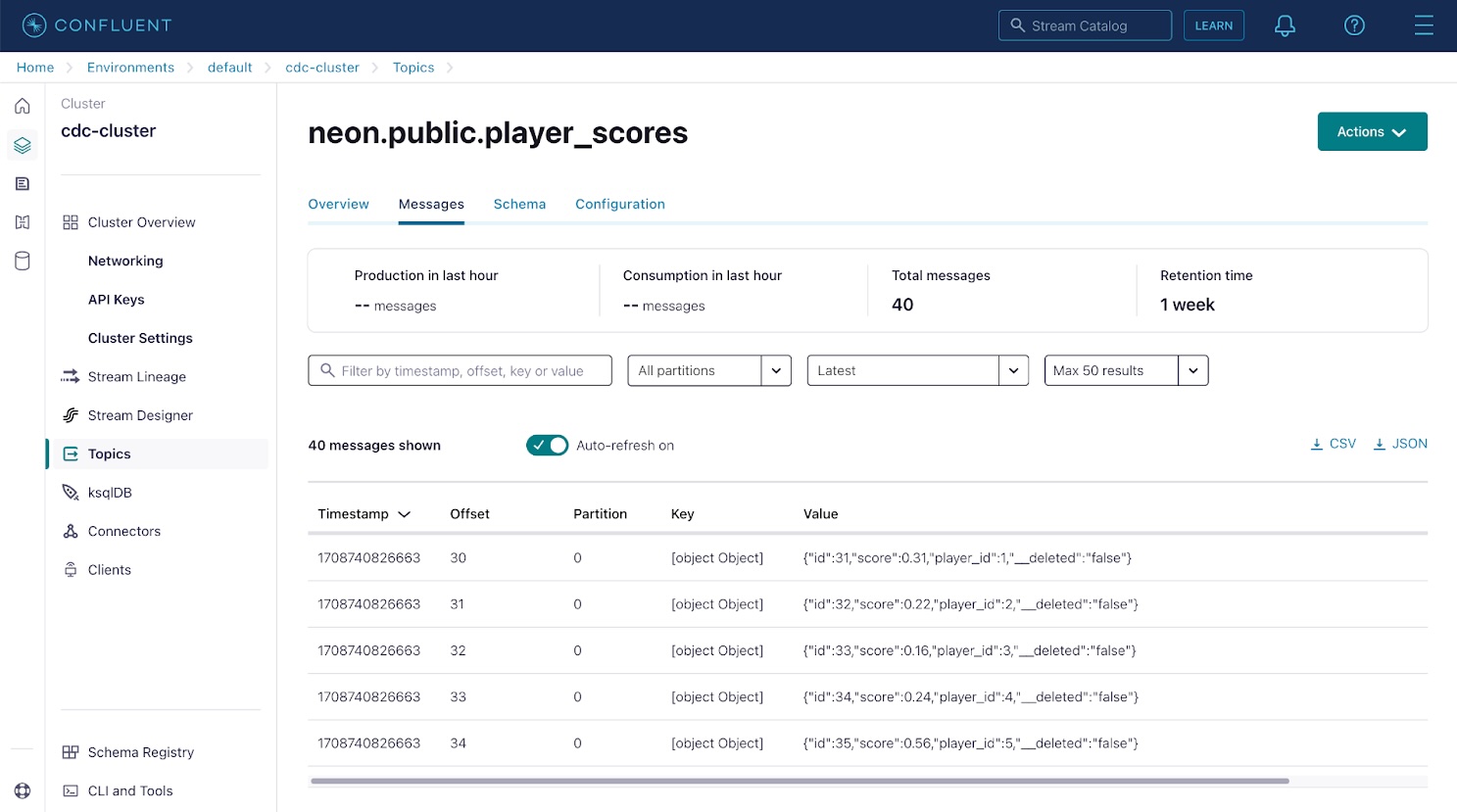
单击任一主题,然后使用消息选项卡查看 Debezium 连接器捕获并流式传输到该主题的数据库更改事件。 Kafka中的每条消息都包含一个key和value;在本例中,这些是数据库行 ID 和行内容。
Apache Kafka 使用分区来提高并行性,并跨多个节点复制分区以提高耐用性。由于 Kafka 分区是有序的不可变消息序列,因此偏移量表示消息在其分区中的位置。如有必要,生产 Kafka 环境中的主题可以分为 100 个或更多分区,以便能够由与分区一样多的消费者进行并行处理。
 接下来,确认已为您的更改记录注册架构。从 Confluence Cloud 控制台侧面菜单的左下角选择架构注册表,并确认已为主题中的记录注册架构。
接下来,确认已为您的更改记录注册架构。从 Confluence Cloud 控制台侧面菜单的左下角选择架构注册表,并确认已为主题中的记录注册架构。
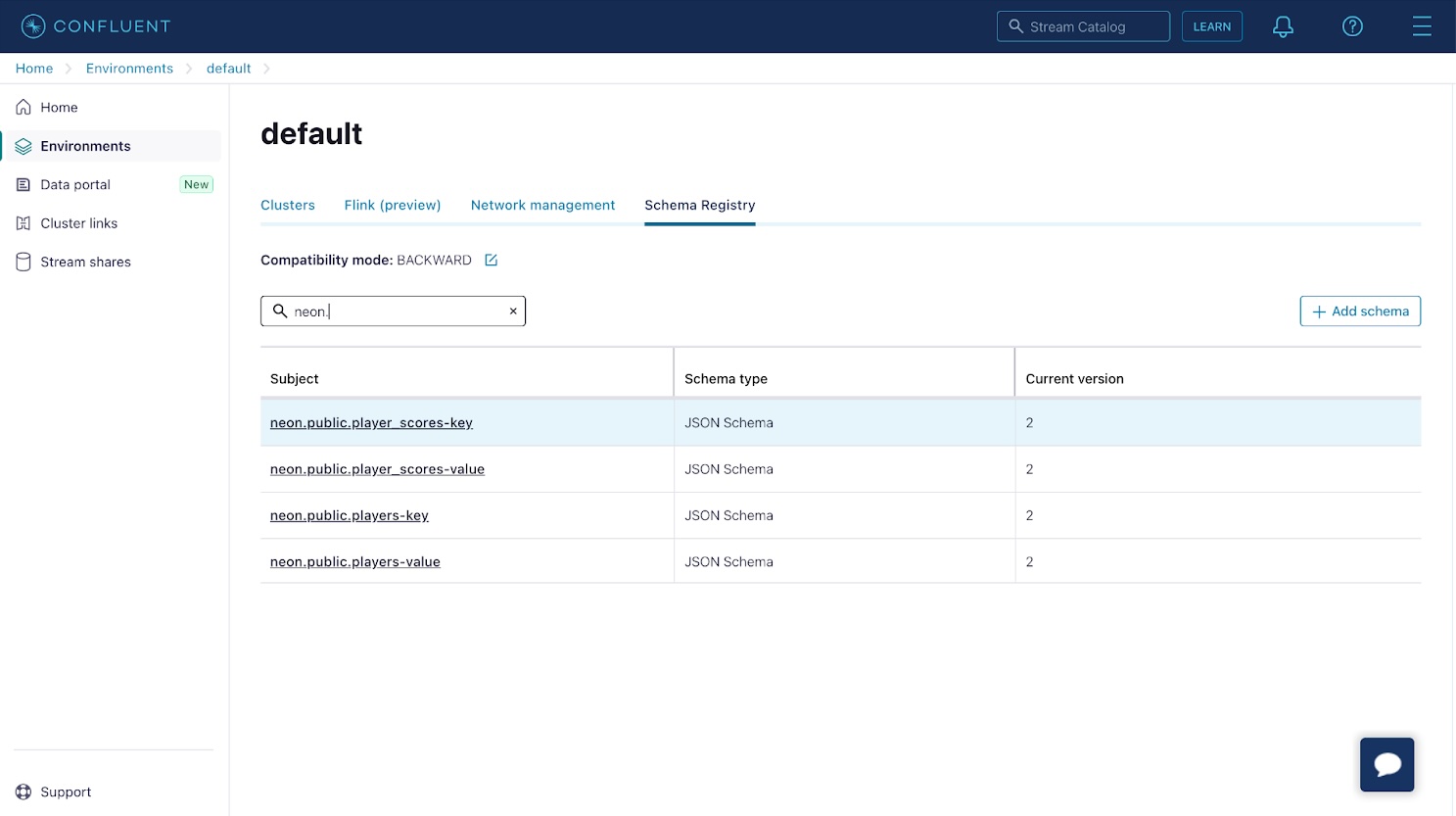
如果单击带有“key”后缀的架构条目,您会注意到该架构只包含一个 id 属性。此属性对应于数据库行的id 或主键。带有“value”后缀的架构条目对应于支持表的架构。
使用 ksqlDB 创建物化视图
有了包含消息的架构和主题,您可以使用 ksqlDB 创建一个物化视图,该视图会根据数据库更改进行更新。
在集群的侧面菜单中选择 ksqlDB,以配置启用全局访问的新 ksqlDB 实例,并使用默认值进行大小调整和配置。配置过程可能需要几分钟,因此请耐心等待。
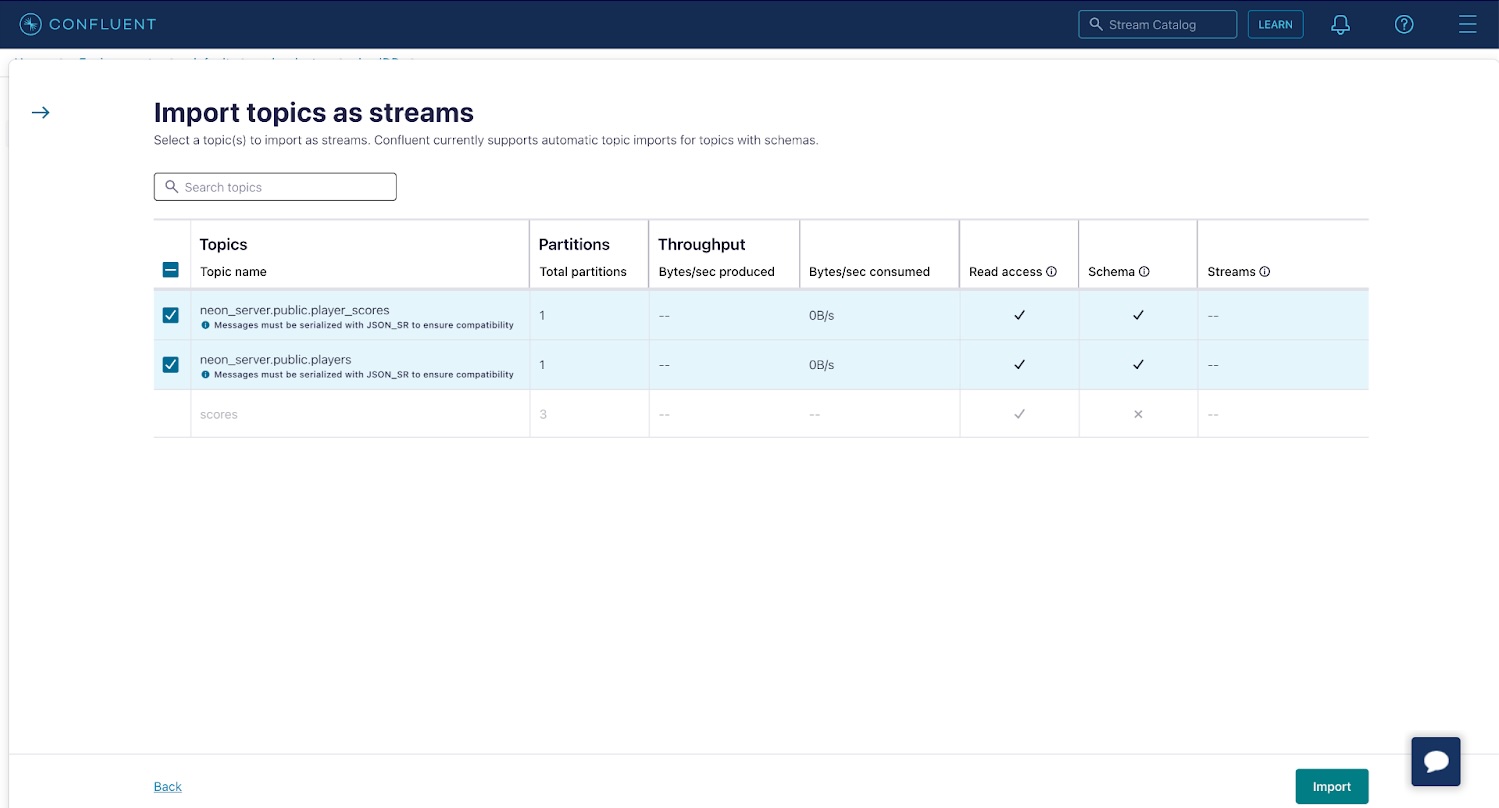
准备好后选择您的 ksqlDB 集群,然后导航到Streams选项卡并点击将主题导入为流以导入您的player_scores和< code>players 主题作为 ksqlDB 中的 streams 。从主题创建流允许您对基础主题中包含的数据执行联接或聚合等操作,稍后您将看到。单击导入以创建流。
现在,使用 ksqlDB 集群 UI 中的编辑器选项卡来创建 聚合,即物化视图。在你的例子中,它将代表每个玩家的得分事件的总和。将以下查询粘贴到编辑器中,然后单击运行查询。
这会在 ksqlDB 中创建一个表,该表会不断更新以响应 NEONPUBLICPLAYER_SCORES 流中的事件。该表将包含每个玩家的一行及其唯一 ID 和所有关联得分事件的总和。
通过选择表格标题下的PLAYER_SCORES并点击查询表格,确认表格按预期工作。将显示包含玩家分数总和的记录列表。
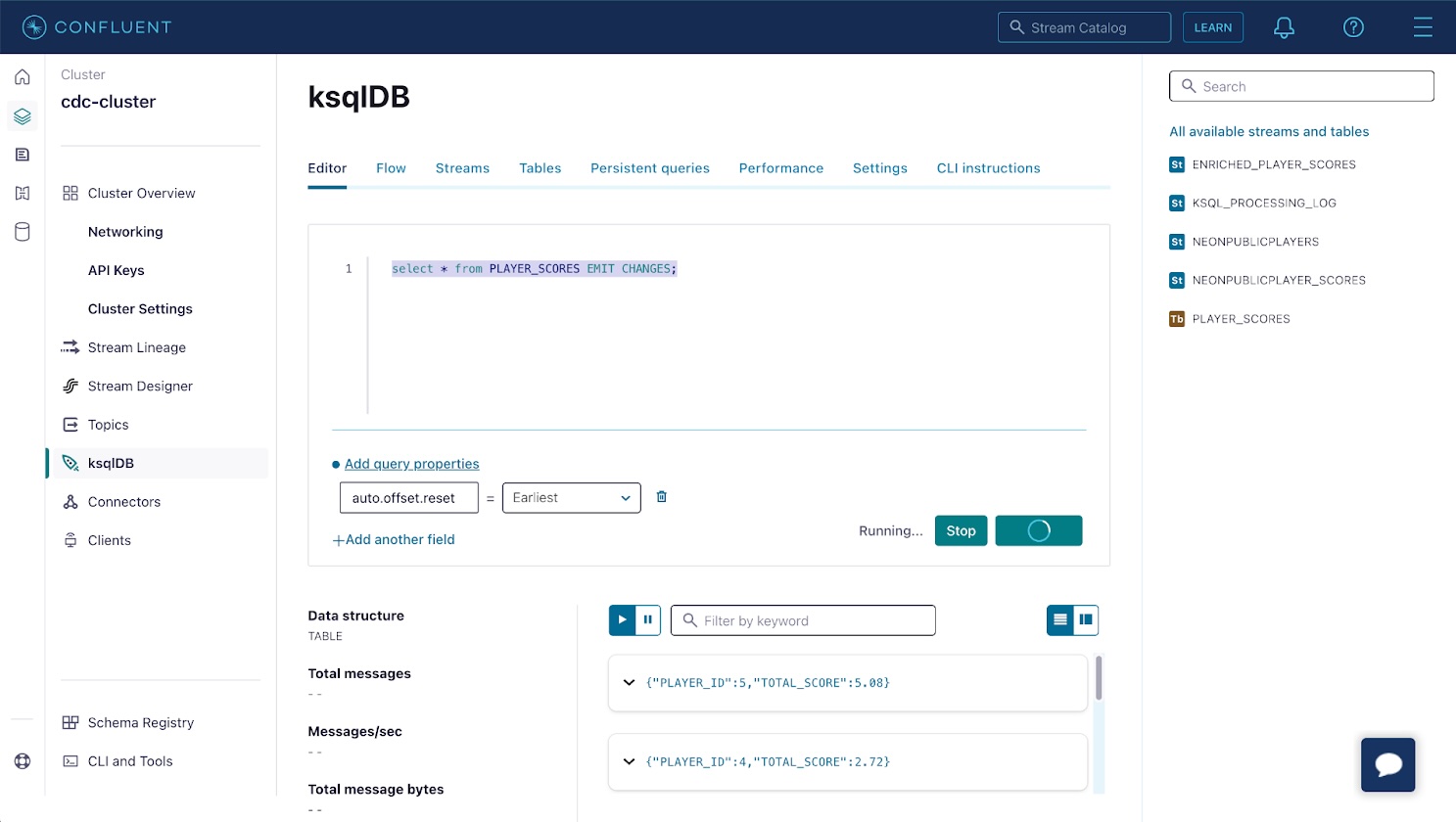
返回 Neon 控制台并将更多数据插入 player_scores 表中。物化视图将在几秒钟内自动更新,以反映每个玩家的新total_score。
可以通过与 ksqlDB REST API。访问集群 UI 中的 API 密钥,创建 API 密钥以针对 ksqlDB REST API 进行身份验证,并使用 ksqlDB 集群 UI 中的设置选项卡查找集群的主机名。
您可以使用以下 cURL 命令从终端中的表中获取更改流:
curl --http1.1 -X "POST" "https://$KSQLDB_HOSTNAME/query" \
-H“接受:application/vnd.ksql.v1+json”\
--basic --user "$API_KEY:$API_SECRET" \
-d $'{
"ksql": "SELECT * FROM PLAYER_SCORES EMIT CHANGES;",
“流属性”:{}
}'
此命令将建立一个持久连接,该连接会在表中实时发生更改时流式传输标头。您可以使用 Neon 控制台中的 SQL 编辑器来确认这一点,将更多数据插入到 player_scores 表中,并观察传输到终端的更新后的总得分:
[{"header":{"queryId":"transient_PLAYER_SCORES_7047340794163641810","schema":"`PLAYER_ID` INTEGER, `TOTAL_SCORE` DECIMAL(10, 2)" }},
{"行":{"列":[1,4.50]}},
{"行":{"列":[2,5.04]}},
{"行":{"列":[3,5.85]}},
{"行":{"列":[4,6.12]}},
{"行":{"列":[5,11.43]}},
{"行":{"列":[1,5.00]}},
{"行":{"列":[4,6.80]}},
{"行":{"列":[5,12.70]}},
{"行":{"列":[1,5.82]}},
{“行”:{“列”:[4,6.92]}}
同样的 HTTP 事件流可以集成到您的应用程序中,以实现 UI 中的实时更新或更新应用程序架构中的其他组件。
结论
Neon 对 Postgres 逻辑复制的支持可以捕获变更数据并将数据库变更流式传输到 Apache Kafka,以便使用 ksqlDB 进行实时处理,从而使用 SQL 语法创建丰富的数据流和物化视图。如果您正在寻找 Postgres 数据库,注册并免费试用 Neon。加入我们的 Discord 服务器,分享您的经验、建议和挑战。
