
在当今数据驱动的世界中,组织正在努力管理他们收集的不断增加的数据量。为了获得见解并做出明智的决策,企业必须打破数据孤岛并创建统一的数据视图。这就是数据网格的用武之地——一种革命性的数据架构新方法,正在改变企业的游戏规则。
什么是数据网格?
数据网格是一种分散的数据架构方法,可促进组织内数据域的自治性和可扩展性。它是对传统中心化数据架构的回应,传统中心化数据架构依靠单一数据平台和中心化团队来管理所有与数据相关的活动。
在数据网格架构中,数据被视为一种产品,并由生成它的域拥有。每个领域都有自己的团队负责收集、处理和分析数据。这些领域团队自主运作,可以自由选择最适合其需求的工具和技术。团队还对其数据的质量和准确性负责。
为什么选择数据网格以及为什么现在?
传统的集中式数据管理方法通常由一个团队或部门负责管理整个组织的所有数据。这个集中团队通常负责设计和管理共享数据架构、定义数据模型并确保数据质量。
但是,这种方法可能会导致数据孤立,因为每个团队或部门都有自己独特的数据需求和要求。因此,团队可能会创建自己的数据集和系统,但这些数据集和系统未与集中式数据架构集成。这可能会导致不同数据集之间出现数据重复、不一致和错误。
此外,传统的集中式方法可能会导致决策过程缓慢,因为数据请求和分析通常需要通过集中式团队进行传递。对于需要快速访问数据以做出明智决策的团队来说,这可能会造成瓶颈、延迟和挫败感。
数据网格的主要优点之一是它使组织能够以更高效和有效的方式扩展其数据基础设施。对于传统的集中式数据架构,由于需要集中式团队来管理一切,因此扩展可能成为瓶颈。这可能会减慢数据处理速度并限制组织及时提取见解的能力。另一方面,数据网格允许独立扩展数据域,从而随着组织的发展更容易扩展数据基础设施。
数据网格还促进组织内的协作和跨职能团队。通过打破数据孤岛,不同的团队可以更轻松地共享数据并在数据相关项目上进行协作。这可以带来更快的创新和改进的决策。
数据网格发生了什么变化?
数据网格彻底改变了分析数据管理的格局,在技术和组织方面引入了多维转换。这种范式要求对组织内的假设、架构、技术解决方案和社会结构进行根本性的重新评估,从而重塑分析数据的管理、利用和拥有方式。
从组织角度来看,数据网格推动了集中式数据所有权的转变,这种所有权以前由管理数据平台技术的专业人士持有。相反,它提倡分散的数据所有权模型,使业务领域能够承担其生成或使用的数据的所有权和责任。
从架构上来说,数据网格摆脱了在整体仓库和湖泊中收集数据的传统方法。相反,它采用分布式网格框架,通过标准化协议互连数据,从而培育更加敏捷和适应性更强的数据生态系统。
从技术上讲,数据网格不再将数据视为管道代码执行的副产品。相反,它提倡的解决方案将数据和负责维护数据的代码视为一个有凝聚力的动态单元,认识到两者之间的内在关系。
在操作上,数据治理经历了深刻的转变。传统的自上而下、手动干预的集中式操作模型被联合模型所取代,该模型结合了嵌入数据网格节点中的计算策略。这种方法可确保更高效、更自主的数据治理。
数据网格的核心重新定义了与数据相关的价值系统。它不仅仅将数据视为要收集的资产,而是将数据视为一种产品,旨在服务和取悦组织内部和外部的数据用户。
此外,数据网格将其影响扩展到基础设施级别。它超越了基础设施服务的分散和点对点集成,这些服务以前被分为数据和分析、应用程序和操作系统的单独领域。相反,数据网格主张建立全面且集成良好的基础设施,以满足运营和数据系统的需求,从而提高协同效率。
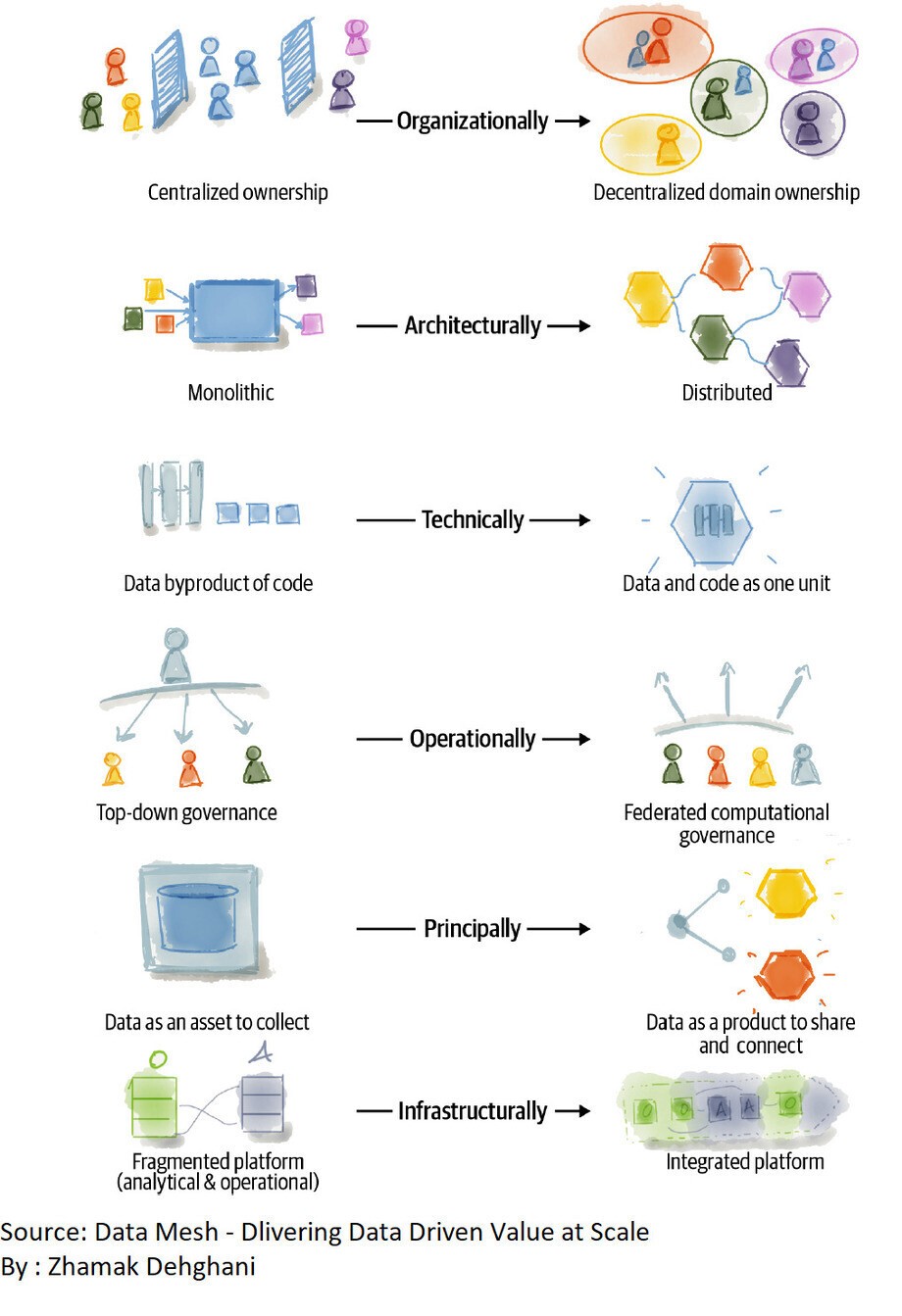
数据网格:它的变化
数据网格构建块
- 面向领域的数据所有权:在数据网格中,数据所有权是分散的,分布在不同的领域或业务部门中。每个域都有自己独特的数据需求和要求,并负责管理自己的数据。这可以确保数据更符合业务需求并且可以更有效地进行管理。
- 数据产品和服务:Data Mesh 将数据视为可供其他团队和领域使用的产品。每个域负责创建和管理自己的数据产品和服务,可供其他域使用。这创建了一种更加模块化和可扩展的数据管理方法。
- 联合数据治理:Data Mesh 实现数据治理的去中心化,每个域负责定义自己的数据策略和标准。但仍保留联合数据治理模型,确保数据跨域一致管理并符合相关法规和政策。
- 自助式数据基础设施:Data Mesh 提倡采用自助式数据基础设施方法,每个域负责管理自己的数据基础设施需求。这包括选择和管理相关的数据存储、计算和处理工具。这使团队能够选择最适合其特定需求和要求的工具。
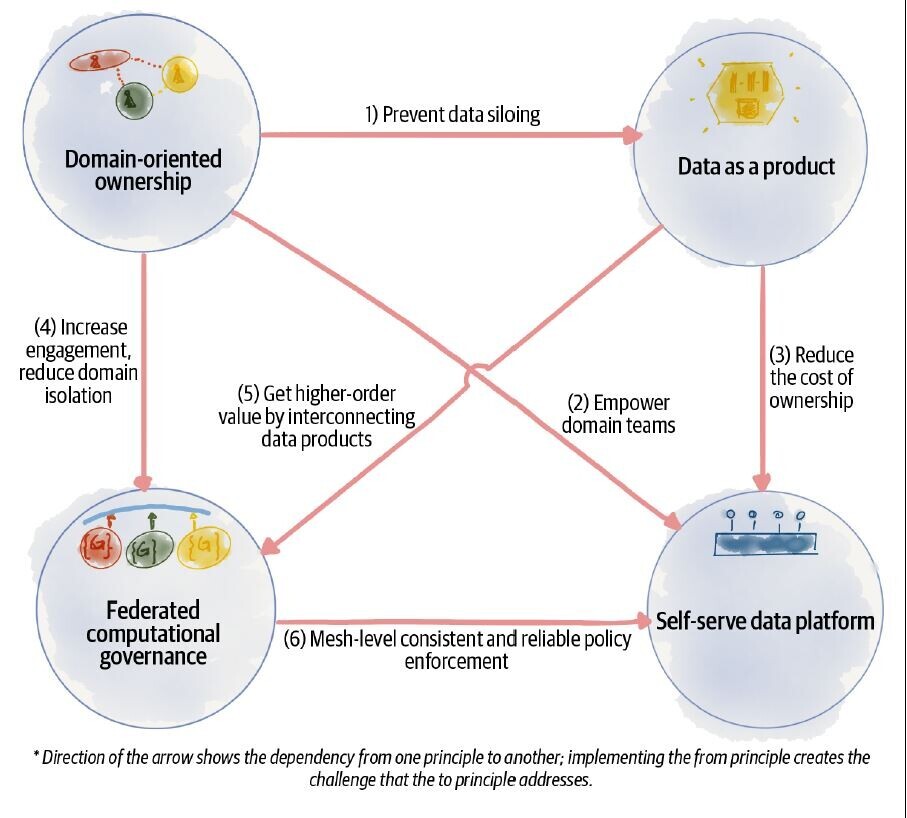
数据网格:构建块
在AWS上实现数据
- 识别数据域:第一步是识别组织内的不同数据域。每个域代表一个不同的业务重点领域,具有自己独特的数据需求和要求。您可以使用 AWS Glue 等工具来发现和编目整个组织中的数据资产。
- 分散数据所有权:在数据网格中,每个域负责管理自己的数据。要在 AWS 上实现此功能,您可以使用 AWS Organizations 为每个域创建单独的账户,每个账户都有自己独特的一组权限和访问控制。
- 定义数据产品和服务:每个域负责创建和管理自己的数据产品和服务。要在 AWS 上执行此操作,您可以使用 AWS Lambda 和 AWS API Gateway 等工具创建无服务器 API,向其他域公开数据产品和服务。
- 联合数据治理:尽管 Data Mesh 中的数据所有权和管理是去中心化的,但仍保留联合数据治理模型。要在 AWS 上实现此功能,您可以使用 AWS Lake Formation 定义跨域一致的数据策略和标准。
- 自助数据基础设施:每个域负责管理自己的数据基础设施需求。要在 AWS 上实现这一点,您可以使用 Amazon S3、Amazon Redshift 和 Amazon EMR 等工具来创建可扩展且灵活的数据存储、计算和处理基础设施。
- 网状架构:在数据网格中,数据通过连接不同域和团队的网状架构进行管理。要在 AWS 上实现此功能,您可以使用 AWS App Mesh 创建一个服务网格,跨域连接不同的数据产品和服务。
数据网格的挑战
虽然数据网格有很多好处,但它也并非没有挑战。主要挑战之一是它需要组织内部进行重大的文化转变。领域团队必须具有高度的自主权和责任感,这对于某些组织来说可能很难接受。
另一个挑战是,与传统的集中式数据架构相比,数据网格的设置和管理可能更加复杂。每个领域团队可能有不同的数据要求、工具和技术,这可能会带来额外的复杂性。
结论
总而言之,数据网格是一种新的数据架构方法,正在改变企业的游戏规则。通过促进数据域的自主性和可扩展性,数据网格使组织能够更高效地扩展其数据基础设施。然而,实施数据网格架构需要重大的文化转变,并且与传统的集中式数据架构相比,管理起来可能更加复杂。尽管面临挑战,数据网格的好处还是引人注目的,从长远来看,采用它的组织可能会取得更大的成功。
