
下面是 Spark 中最重要的主题列表,每个没有时间完成整本书但想要发现此分布式计算框架的惊人功能的人,在开始之前,都应该经历这些主题。
建筑
地图减少与火花
尽管 Apache Spark 和 MapReduce 之间存在许多低级差异,但以下是最突出的差异:
- Spark 在内存中运行速度为 100 倍,磁盘运行速度为 10 倍。
- 用于对 100 TB 数据进行排序的排序应用程序比使用十分之一的计算机在 Hadoop MapReduce 上运行的应用程序快三倍。
- 在机器学习应用(如 Naive Bayes 和 K-Means)上,特别发现 Spark 速度更快。
- 但是,如果 Spark 与其他共享服务一起在 YARN 上运行,则性能可能会降低并导致 RAM 开销内存泄漏。因此,如果用户具有批处理的用例,则 Hadoop 已发现是效率更高的系统。
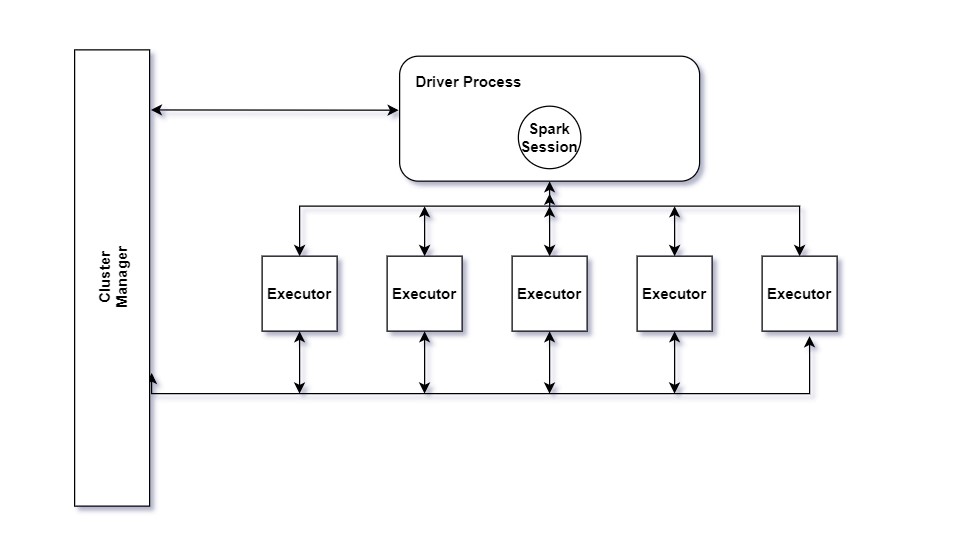
驱动程序和执行器
运行函数的驱动程序进程 main() 位于群集中的节点上,负责三件事:
- 维护有关 Spark 应用程序的信息。
- 响应用户的程序或输入。
- 分析、分发和安排跨执行器的工作
执行者负责实际执行驱动程序分配给他们的工作。这意味着每个执行者只负责两件事:
- 执行驱动程序分配给它的代码。
- 将该执行器的计算状态报告回驱动程序节点。
分区
为了允许每个执行器并行执行工作,Spark 将数据分解为称为分区的区块。分区是位于群集中一个物理计算机上的行的集合。数据帧的分区表示数据在执行期间如何物理分布到计算机群集中。
如果您有一个分区,Spark 的并行性将只有一个,即使您有数千个执行器。如果有多个分区,但只有一个执行器,Spark 仍将只有一个并行性,因为只有一个计算资源。
执行模式:客户端或群集或本地
执行模式使您能够确定运行应用程序时上述资源(如驱动程序和执行器)的物理位置。
您有三种模式可供选择:
- 群集模式。
- 客户端模式。
- 本地模式。
群集模式可能是运行 Spark 应用程序的最常见方式。在群集模式下,用户向群集管理器提交预编译的代码。然后,群集管理器在群集内的工作节点上启动驱动程序进程,以及执行器进程。这意味着群集管理器负责管理与 Spark 应用程序相关的所有进程。
客户端模式与群集模式几乎相同,只不过 Spark 驱动程序保留在提交应用程序的客户端计算机上。这意味着客户端计算机负责维护 Spark 驱动程序进程,并且群集管理器维护执行器进程。从群集运行 Spark 应用程序且未在群集上配置的计算机通常称为网关计算机或边缘节点。
本地模式可以被视为在计算机上运行程序,在其中,您可以告诉 Spark 以运行驱动程序以及同一 JVM 中执行器RDD 是通过从 Hadoop 文件系统(或任何其他 Hadoop 支持的文件系统)中的文件或驱动程序程序中的现有 Scala 集合开始创建的,并转换它。
在应该多次使用单个 RDD 的情况下,用户可以请求 Spark 保留 RDD,则存在多个持久性级别,这将指示 Spark 应用程序保存 RDD 并允许高效使用。最后,RDD 会自动从节点故障中恢复。
数据框是最常见的结构化 API,它仅表示包含行和列的数据表。组合组合的列及其数据类型将形成数据框的架构。您可以将数据框视为具有命名列的电子表格。
尽管存在根本区别:电子表格驻留在一个特定位置的一台计算机上,而 Spark数据帧可以跨数千台计算机。将文件放在多个节点上的原因有多种:要么数据太大,无法容纳在一台计算机上,要么只需很长时间才能在一台计算机上执行该计算。
从 Spark 2.0 开始,数据集具有两个不同的 API 特征:强类型 API 和未键入的 API。从概念上讲,将Dataframe视为泛型对象 Dataset_Row] 集合的别名,其中行是泛型未键入的 JVM 对象。相比之下,数据集是强类型 JVM 对象的集合,由您在 Scala 中定义的案例类或 Java 中的类指定。
共享变量
Spark 中的第二个抽象是共享变量,可在并行操作期间跨所有参与节点使用。尽管通常 Spark 会提供任务执行其功能所需的变量的副本。但是,有时,变量需要在任务之间、任务和驱动程序程序之间共享。Spark 支持两种类型的共享变量:
- 广播变量,可用于在所有节点上缓存内存中的值。
- 蓄能器,这是仅”添加”到的变量,如计数器和总和。
火花会话
任何 Spark 应用程序的第一步是创建 一个 SparkSession 。某些旧代码可能使用新 SparkContext 模式。应避免使用 生成器方法, SparkSession 该方法更有力地实例化 Spark 和 SQL 上下文并确保不存在上下文冲突,因为可能有多个库尝试在同一 Spark 应用程序中创建会话:
之后, SparkSession 您应该能够运行 Spark 代码
注意: SparkSession 类只添加到 Spark 2.X 中,您可能会发现的旧代码将直接创建 和 SparkContext SQLContext a,用于结构化 API。
SparkContext中的对象 SparkSession 表示与 Spark 群集的连接。此类是您与 Spark 的一些较低级别 API(如 RDD)通信的方式。通过 , SparkContext 您可以创建 RDD、蓄能器和广播变量,也可以在群集上运行代码。如果要初始化 SparkContext ,则应通过 以下方法以最通用的方式创建它 getOrCreate :
懒惰评估
延迟评估意味着 Spark 将一直等到最后一刻才能执行计算指令的图形。在 Spark 中,而不是在表示某些操作时立即修改数据,而是构建要应用于源数据的转换计划。
通过等待执行代码的最后一分钟,Spark 将此计划从原始 Dataframe 转换编译为简化的物理计划,从而尽可能高效地在整个群集中运行。这带来了巨大的好处,因为 Spark 可以优化整个数据流。”例如,在数据帧上称为谓词推送。
如果我们构建一个大型 Spark 作业,但在末尾指定一个筛选器,该筛选器只需要我们从源数据中获取一行,则执行此任务的最有效方法是访问所需的单个记录。Spark 实际上会通过自动按下过滤器来为我们优化这一点。
行动和转型
转换使我们能够构建逻辑转型计划。为了触发计算,我们运行一个操作。操作指示 Spark 计算一系列转换的结果。最简单的操作是计数,它为我们提供了 DataFrame 中记录总数:divisBy2.count() 前面的代码的输出应为 500。
当然,计数并不是唯一的行动。有三种操作:在控制台中查看数据的操作 操作 操作 用于以相应语言将数据收集到本机对象 操作 以写入输出数据源 在指定此操作时,我们启动了运行筛选器转换(窄转换)的 Spark 作业,然后是聚合(宽转换),该聚合(宽转换)按每个分区执行计数,然后收集,这将把我们的结果带到一个本机对象在各自的语言
在 Spark 中,核心数据结构是不可变的,这意味着在创建核心数据结构后无法更改它们。乍一看,这似乎是一个奇怪的概念:如果你不能改变它,你应该如何使用它?要”更改”DataFrame,您需要指示 Spark 如何修改它以执行所需的操作。这些指令称为转换。
转换是如何使用 Spark 表达业务逻辑的核心。有两种类型的转换:指定窄依赖项的转换和指定广泛依赖项的转换。由窄依赖项(我们称之为窄转换)组成的转换是每个输入分区只能贡献一个输出分区的转换。在前面的代码段中,其中语句指定一个狭窄的依赖项,其中最多只有一个分区有助于一个输出分区。
宽依赖项(或宽转换)样式转换将具有导致许多输出分区的输入分区。您经常会听到这称为随机播放,Spark 将在群集中交换分区。使用窄转换时,Spark 将自动执行称为管道的操作,这意味着如果我们在数据帧上指定多个筛选器,它们都将在内存中执行。洗牌的情况不能同样。当我们执行随机播放时,Spark 将结果写入磁盘。
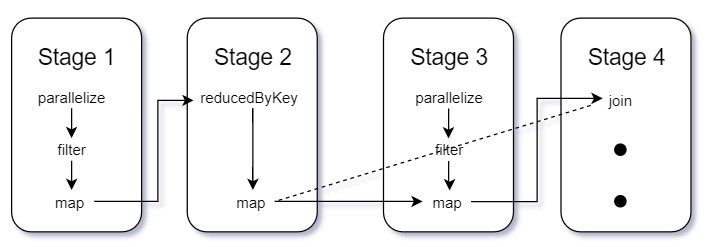
阶段和任务
Stages Spark 中的阶段表示可以一起执行以在多台计算机上计算相同操作的任务组。通常,Spark 会尝试将尽可能多的工作(即作业内尽可能多的转换)打包到同一阶段,但引擎在操作称为随机操作后开始新的阶段。
随机播放表示数据的物理重新分区,例如,对 DataFrame 进行排序或按键从文件加载的数据分组(这需要将具有相同密钥的记录发送到同一节点)。这种类型的重新分区需要跨执行器进行协调以移动数据。Spark 在每次随机播放后开始一个新阶段,并跟踪阶段必须运行的顺序才能计算最终结果。
Spark 中的阶段由任务组成。每个任务对应于数据块和一组将在单个执行器上运行的转换的组合。如果我们的数据集中有一个大分区,我们将有一个任务任务只是应用于数据单元(分区)的计算单元。将数据分区到更多分区意味着可以并行执行更多分区。
DAG:定向青环图
Apache Spark 中的 DAG 是一组顶点和边,其中顶点表示 RDD,边缘表示要应用于 RDD 的操作。在 Spark DAG 中,每个边在序列中从较早到晚点定向。
资源管理器:独立或 YARN 或 MESOS
Spark 将用于执行任务的计算机群集由群集管理器管理,例如 Spark 的独立群集管理器 YARN 或 Mesos。然后,我们将 Spark 应用程序提交给这些群集管理器,这些经理会为我们的应用程序授予资源,以便我们可以完成工作。
有趣的事实: 玛蒂扎哈里亚, 火花的创造者, 开始火花作为中子的飞行员工作量.
@IamShivamMohan推特跟我来