
生成式人工智能 (GenAI) 支持先进的人工智能用例和创新,但也改变了企业架构的外观。大型语言模型 (LLM)、向量数据库和检索增强生成 (RAG) 需要新的数据集成模式和数据工程最佳实践。使用 Apache Kafka 和 Apache Flink 进行数据流处理是大规模实时摄取和整理传入数据集、连接各种数据库和分析平台以及解耦独立业务部门和数据产品的关键。这篇博文探讨了事件流与传统请求响应 API 和数据库之间的可能架构、示例以及权衡。

Apache Kafka 和 GenAI 的用例
生成式人工智能 (GenAI) 是用于自然语言处理 (NLP)、图像生成、代码优化和其他任务的下一代人工智能引擎。它可以帮助现实世界中的许多项目实现服务台自动化、客户与聊天机器人的对话、社交网络中的内容审核以及许多其他用例。
Apache Kafka 成为这些机器学习平台中的主要编排层,用于集成各种数据源、大规模处理和实时模型推理。
使用 Kafka 进行数据流传输已经为许多 GenAI 基础设施和软件产品提供支持。可能出现非常不同的情况:
- 数据流作为整个机器学习基础设施的数据结构
- 模型评分,通过流处理进行实时预测和内容生成
- 生成带有输入文本、语音或图像的流数据管道
- 大型语言模型的实时在线训练
我在博客文章“Apache Kafka 作为 GenAI 的关键任务数据结构。”
下面介绍了大型语言模型 (LLM)、检索增强生成 (RAG) 与向量数据库和语义搜索以及 Apache Kafka 和 Flink 的数据流相结合的具体架构。
为什么生成式人工智能与传统机器学习架构不同
机器学习 (ML) 允许计算机找到隐藏的见解,而无需对要查找的位置进行编程。这称为模型训练,是分析大数据集的批处理过程。输出是一个二进制文件,即分析模型。
应用程序将这些模型应用于新的传入事件以进行预测。这称为模型评分,可以通过将模型嵌入到应用程序中或通过对模型服务器(部署模型)进行请求响应 API 调用来实时或批量进行。
但是,与传统的机器学习流程相比,法学硕士和 GenAI 具有不同的要求和模式,正如我的前同事 Michael Drogalis 在两个简单、清晰的图表中所解释的那样。
具有复杂数据工程的传统预测机器学习
预测人工智能可以做出预测。专门构建的模型。线下培训。这就是我们在过去十年左右的时间里进行机器学习的方式。
在传统的机器学习中,大部分数据工程工作发生在模型创建时。特征工程和模型训练需要大量的专业知识和努力:
新用例需要数据工程师和数据科学家构建新模型。
使用大型语言模型 (LLM) 的生成式 AI 实现 AI 民主化
生成人工智能 (GenAI) 创建内容。可重复使用的模型。情境学习。
但是对于大型语言模型,每次查询都会发生数据工程。不同的应用程序重复使用相同的模型:
GenAI 用例的大型语言模型面临的挑战
大型语言模型 (LLM) 是可重用的。这使得人工智能的民主化成为可能,因为并非每个团队都需要人工智能专业知识。相反,人工智能专业知识水平较低就足以使用现有的法学硕士。
但是,LLM 存在一些巨大的权衡:
- 昂贵的培训:像 ChatGPT 这样的法学硕士需要花费数百万美元的计算资源(这不包括构建模型所需的专业知识)
- 静态数据:法学硕士“被及时冻结”,这意味着模型没有最新信息。
- 缺乏领域知识:法学硕士通常从公共数据集学习。因此,数据工程师抓取万维网并将其输入到模型训练中。然而,企业需要在自己的环境中使用 LMM 来提供商业价值。
- 愚蠢:法学硕士不像人类那么聪明。例如,ChatGPT 甚至无法计算您提示的句子中的单词数。
这些挑战会产生所谓的幻觉……
避免幻觉以生成可靠的答案
幻觉,即最佳猜测答案,是结果,法学硕士不会告诉你这是编造的。幻觉是一种现象,其中人工智能模型生成的内容不基于真实的数据或信息,但创建完全虚构或不切实际的输出。当生成模型(例如文本或图像生成器)生成不连贯、不真实或与输入数据或上下文不相关的内容时,可能会出现幻觉。这些幻觉可以表现为文本、图像或其他类型的内容,这些内容看似合理,但完全是模型捏造的。
幻觉在生成人工智能中可能会出现问题,因为它们可能导致生成误导性或虚假信息。
出于这些原因,生成式人工智能出现了一种新的设计模式:检索增强生成(RAG)。让我们首先看看这个新的最佳实践,然后探讨为什么使用 Apache Kafka 和 Flink 等技术进行数据流是 GenAI 企业架构的基本要求。
语义搜索和检索增强生成 (RAG)
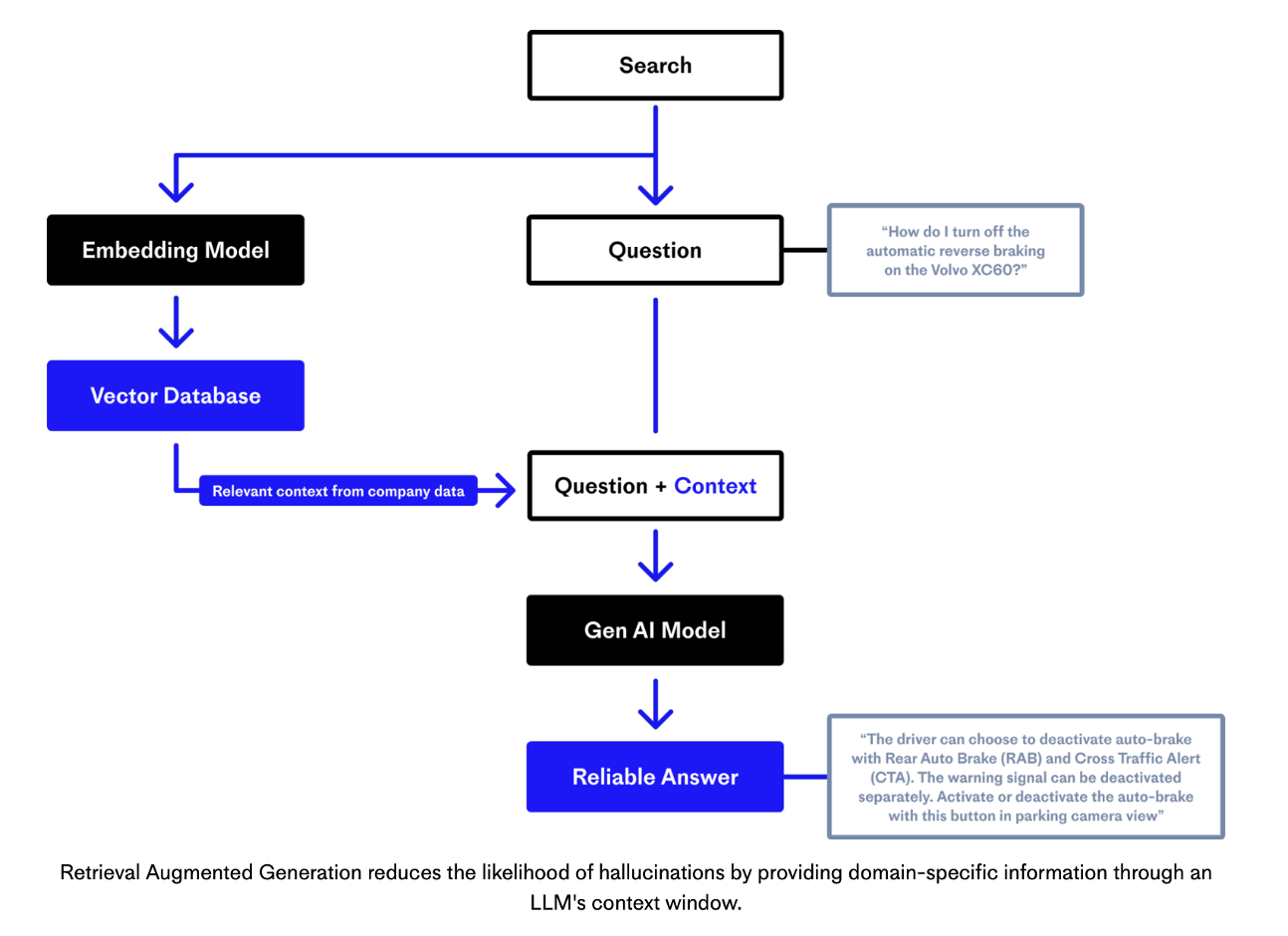
许多支持 GenAI 的应用程序都遵循检索增强生成 (RAG) 的设计模式,将法学硕士与准确且最新的上下文相结合。 Pinecone(一个完全托管的矢量数据库)背后的团队有一个很好的解释 使用此图:
 来源:松果
来源:松果
从较高层面来看,RAG 通常是两个独立的步骤。第一个是数据增强步骤,其中对不同的(通常是非结构化的)操作数据进行分块,然后使用嵌入模型创建嵌入。嵌入被索引到向量数据库中。矢量数据库是一种工具,可让语义搜索为不需要精确关键字匹配的提示找到相关上下文。
其次是推理步骤,GenAI 模型接收问题和上下文以生成可靠的答案(没有幻觉)。 RAG 不会更新嵌入,而是检索相关信息并与提示一起发送给 LLM。
用于嵌入语义搜索的矢量数据库
矢量数据库,也称为矢量存储或矢量索引,是一种专门设计用于高效存储和检索矢量数据的数据库。在这种情况下,矢量数据是指数值矢量的集合,它可以表示多种数据类型,例如文本、图像、音频或任何其他结构化或非结构化数据的嵌入。矢量数据库在机器学习、数据检索、推荐系统、相似性搜索等相关应用中非常有用。
矢量数据库擅长执行相似性搜索,通常称为语义搜索。他们可以根据各种相似性度量(例如余弦相似度或欧几里德距离)快速找到与给定查询向量相似或接近的向量。
矢量数据库(不一定)不是一个单独的数据库类别。 Gradient Flow 解释了其检索增强生成的最佳实践:
<块引用>
“矢量搜索不再局限于矢量数据库。许多数据管理系统(包括 PostgreSQL)现在都支持矢量搜索。根据您的具体应用,您可能会找到满足您特定需求的系统。接近实时或流优先吗?检查 Rockset 的产品。您已经在使用知识图了吗?Neo4j 对矢量搜索的支持意味着您的 RAG 结果将更容易解释和可视化。”
对于另一个具体示例,请查看 MongoDB 的教程“使用 MongoDB 构建生成式 AI 应用程序:利用 Atlas 矢量搜索和开源模型的力量。”将 GenAI 用例的向量数据库与 Apache Kafka 相结合有多种选择。以下是事件驱动世界中可能的架构。
事件驱动架构:数据流 + Vector DB + LLM
事件驱动的应用程序可以更有效地实现检索增强生成(RAG)、数据增强和模型推理这两个步骤。使用 Apache Kafka 和 Apache Flink 的数据流可以实现任何规模的数据一致同步(如果应用程序或数据库可以处理,则可以实时同步)和数据管理(= 流式 ETL)。
下图显示了利用事件驱动的数据流在整个 GenAI 管道中进行数据摄取和处理的企业架构:
此示例使用数据流将航班预订和更改实时提取到 Kafka 的事件存储中,以便稍后使用 GenAI 技术进行处理。 Flink 在调用嵌入模型为向量数据库生成嵌入之前对数据进行预处理。与此同时,使用 Python 构建的实时客户服务应用程序会消耗所有相关的上下文数据(例如,航班数据、客户数据、嵌入等)来提示大型语言模型。法学硕士可以做出可靠的预测,例如为乘客重新预订另一航班的建议。
在大多数企业场景中,出于安全和数据隐私原因,所有处理都在企业防火墙后面进行。法学硕士甚至可以与预订引擎等交易系统集成,以执行重新预订并将结果输入相关应用程序和数据库。
使用 API 进行请求-响应与事件驱动的数据流
在理想的世界中,一切都是基于事件的流数据。现实世界是不同的。因此,使用 HTTP/REST 或 SQL 进行请求-响应的 API 调用在企业架构的某些部分完全没问题。由于 Kafka 真正解耦了系统,每个应用程序都可以选择自己的通信范式和处理速度。因此,了解 HTTP/REST API 和 Apache Kafka 之间的权衡。
何时将请求-响应与 Apache Kafka 结合使用? — 此决定通常是根据延迟、解耦或安全性等权衡做出的。然而,对于大型法学硕士,情况发生了变化。由于法学硕士的培训成本非常昂贵,因此现有法学硕士的可重用性至关重要。与使用决策树、集群甚至小型神经网络等算法构建的其他模型相反,将 LLM 嵌入到 Kafka Streams 或 Flink 应用程序中没有什么意义。
同样,增强模型通常通过 RPC/API 调用进行集成。通过将其嵌入到 Kafka Streams 微服务或 Flink 作业中,增强模型变得紧密耦合。如今专家主持了其中的许多活动,因为操作和优化它们并非易事。
托管 LLM 和增强模型的解决方案通常仅提供 HTTP 等 RPC 接口。这在未来可能会改变,因为请求-响应是流数据的反模式。 Seldon 是模型服务器演变的一个很好的例子。同时提供 Kafka 原生接口。在文章 使用 Kafka 原生模型部署进行流式机器学习。
法学硕士与企业其他部分之间的直接集成
在撰写本文时,OpenAI 宣布了 GPT 来创建自定义版本ChatGPT 结合了说明、额外知识和任意技能组合。对于企业用途,最有趣的功能是开发人员可以将 OpenAI 的 GPT 连接到现实世界,即其他软件应用程序、数据库和云服务:
“除了使用我们的内置功能之外,您还可以通过为 GPT 提供一个或多个 API 来定义自定义操作。与插件一样,操作允许 GPT 集成外部数据或与现实世界交互。连接 GPT数据库、将它们插入电子邮件或让它们成为您的购物助手。例如,您可以集成旅行列表数据库、连接用户的电子邮件收件箱或促进电子商务订单。”
使用直接集成的权衡是紧密耦合和点对点通信。如果您已经使用 Kafka,您就会了解 具有真正解耦的领域驱动设计。
最后但并非最不重要的一点是,公共 GenAI API 和 LLM 的安全和治理策略薄弱。随着人工智能数据的出现和点对点集成数量的增加,数据访问、沿袭和安全挑战不断升级。
使用 Kafka、Flink 和 GenAI 进行数据流的实践
在了解了很多理论之后,让我们看一下将数据流与 GenAI 相结合的具体示例、演示和真实案例研究:
- 示例:Flink SQL + OpenAI API
- 演示:用于 RAG 和矢量搜索的 ChatGPT 4 + Confluence Cloud + MongoDB Atlas
- 成功案例:Elemental Cognition – 由 Confluence Cloud 提供支持的实时人工智能平台
示例:Flink SQL + OpenAI API
使用 Kafka 和 Flink 进行流处理,实现实时数据和历史数据的数据关联。一个很好的例子,特别是对于生成式人工智能来说,是特定情境的客户服务。我们在这里以航空公司和航班取消为例。
有状态流处理器从 CRM、忠诚度平台和其他应用程序获取现有客户信息,将其与客户对聊天机器人的查询相关联,并对 LLM 进行 RPC 调用。
下图使用 Apache Flink 和 Flink SQL 用户定义函数 (UDF)。 SQL 查询将预处理后的数据输入 OpenAI API 以获得可靠的答案。答案被发送到下游应用程序使用它的另一个 Kafka 主题,例如,用于重新预订机票、更新忠诚度平台,以及将数据存储在数据湖中以供以后的批处理和分析。

演示:ChatGPT 4 + Confluence Cloud + 用于 RAG 和矢量搜索的 MongoDB Atlas
我的同事 Britton LaRoche 构建了一个出色的零售演示,展示了用于数据集成和处理的 Kafka 与用于存储和语义向量搜索的 MongoDB 的结合。 AI视频创作平台D-ID通过视觉AI头像代替命令行界面,让演示更加美观。

Confluence Cloud 和 MongoDB Atlas 的完全托管和深度集成服务使我们能够专注于构建业务逻辑。
该架构与我上面的基于事件的流式传输示例不同。核心仍然是Kafka来真正解耦应用。大多数服务都是通过请求-响应 API 集成的。这很简单、易于理解,而且通常足够好。您可以稍后使用 Python Kafka API 轻松迁移到基于事件的模式、更改 Kafka 的数据捕获 (CDC)、将 LangChain Python UDF 嵌入 Apache Flink 或使用 AsyncAPI 等异步接口。
下面是一个简短的五分钟演示,将带您了解 RAG 和语义搜索的演示,使用 MongoDB Atlas、Confluence 作为集成中心、D-ID 作为与最终用户的通信接口:
成功案例:Elemental Cognition — 由 Kafka 和 Confluence Cloud 提供支持的实时 GenAI 平台
博士。 David Ferrucci 是著名的人工智能研究员和 IBM 突破性 Watson 技术的发明者,于 2015 年创立了 Elemental Cognition。该公司利用 GenAI 来加速和改进关键决策,而信任、精确度和透明度都很重要。
元素认知技术可跨行业和用例使用。主要目标是医疗保健/生命科学、投资管理、情报、物流和调度以及联络中心。
人工智能平台开发负责任且透明的人工智能,帮助解决问题并提供可以理解和信任的专业知识。
Elemental Cognition 的方法将不同的人工智能策略结合在一个新颖的架构中,该架构获取并推理人类可读的知识,以协作和动态地解决问题。其结果是将专家解决问题的情报更加透明且更具成本效益地交付到对话和发现应用程序中。
Confluence Cloud 为 AI 平台提供支持,以实现可扩展的实时数据和数据集成用例。我建议您查看他们的网站,从各种令人印象深刻的用例中学习。

Apache Kafka 作为 GenAI 企业架构的中枢神经系统
生成式 AI (GenAI) 需要更改 AI/ML 企业架构。增强模型、法学硕士、带有向量数据库的 RAG 和语义搜索需要数据集成、关联和解耦。使用 Kafka 和 Flink 进行数据流可以为您提供帮助。
许多应用程序和数据库使用 REST/HTTP、SQL 或其他接口进行请求-响应通信。那完全没问题。为您的数据产品和应用程序选择正确的技术和集成层。但要保证数据的一致性。
使用 Apache Kafka 和 Apache Flink 进行数据流处理使开发人员和数据工程师能够专注于其数据产品或集成项目中的业务问题,因为它真正解耦了不同的领域。可以通过 HTTP、Kafka API、AsyncAPI、来自数据库的 CDC、SaaS 接口和许多其他选项与 Kafka 集成。
Kafka 支持系统与任何通信范式的连接。其事件存储以毫秒为单位共享数据(即使在极端规模下),但也为较慢的下游应用程序保留数据并重播历史数据。 数据网格的核心必须实时跳动。对于任何优秀的企业架构来说都是如此。 GenAI 也不例外。
如何利用 Apache Kafka 构建对话式 AI、聊天机器人和其他 GenAI 应用程序?您是否使用 Flink 和矢量数据库实时构建 RAG 来为 LLM 提供正确的上下文?让我们在 LinkedIn 上联系并进行讨论!通过订阅我的时事通讯随时了解新的博客文章。

