
阿帕奇卡夫卡和机器学习/深度学习的结合是银行业和金融业的新黑人。此博客文章涵盖用例、体系结构和欺诈检测示例。
金融行业事件流
出现各种不同的(通常是任务关键型)用例,用于在金融行业部署事件流。以下是一些利用 Apache Kafka 进行银行项目的公司:
查看过去的卡夫卡峰会录像和幻灯片,了解来自金融业的这些公司的用例和架构的详细信息。
下面是一些具体的例子:
- 资本一:成为真正的事件驱动 – 提供银行其他部门可以使用的服务。
- ING: 显著改善客户体验 – 作为差异化 – 欺诈检测和成本节约。
- Nordea: 能够满足实时报告方面的严格监管要求 – 节省成本。
- Paypal: 每天处理 4000+ 十亿个事件,用于用户生物跟踪、商家监控、风险和合规性、欺诈检测和其他用例。
- 加拿大皇家银行 (RBC): 大型机卸载,更好的 CX 和欺诈检测 – 将银行的许多部分整合在一起
这只是一个很短的名单,在金融部门的公司使用Apache Kafka作为活动流平台,他们的业务的心脏。数以十计的全球银行利用Apache Kafka处理许多用例,提供了许多其他例子。
阿帕奇卡夫卡作为中间件在银行
我在银行中看到的一个关键用例是实际不是这篇文章的原因:Apache Kafka作为现代,可扩展,可靠的中间件:
- 构建可扩展的 24/7 中间件基础架构,具有实时处理、零停机时间、零数据丢失以及集成传统和现代技术、数据库和应用程序
- 与现有旧式中间件(ESB、ETL、MQ)集成
- 替换专有集成平台
- 从大型机等昂贵系统卸载
对于这些方案,请查看我的博客、幻灯片和视频
现在让我们专注于另一个非常有趣的话题,我看到越来越多的在金融行业:Apache Kafka + 事件流 + 机器学习。让我们从用例和技术角度来讨论如何配合… 机器学习 (ML)允许计算机在没有隐藏见解的情况下查找隐藏的见解 如果您需要有关机器学习/深度学习的更多详细信息,请查看 Web 上的其他资源。 我们希望了解如何与 Kafka 一起利用机器学习来改进传统,并在金融行业构建新的创新用例: 通常,您需要创建用于模型训练、模型评分(也称为预测)和监视的管道,如下所示: 你觉得这听起来很熟悉吗?我猜你可以想象阿帕奇·卡夫卡为什么在这里玩… 在过去的两年里,我谈到了阿帕奇卡夫卡和机器学习/深度学习之间的关系cheeli.com.cn/wp-content/uploads/2020/04/Screenshot-2019-11-22-at-09.16.57-1024×508-1.png” 宽度=”1024″/* 我建议以下博客文章,以了解更多关于建立一个可扩展和可靠的实时基础设施的ML: 现在让我们看一个具体的例子… 欺诈是一个十亿美元的业务,它正在增加每一个是r。普华永道(PwC)2018年全球经济犯罪调查发现,在接受调查的7200家公司中,有半数(49%)经历过某种欺诈。 传统的数据分析方法长期以来一直被用来检测欺诈。它们需要复杂而耗时的调查,涉及金融、经济、商业惯例和法律等不同知识领域。欺诈通常包括许多使用同一方法重复违规的事件或事件。欺诈实例在内容和外观上可能相似,但通常不相同。 这就是机器学习和人工智能 (AI) 发挥作用的地方:这些 ML算法会寻找客户、客户、供应商等的行为”异常”,以便根据方法输出怀疑分数、规则或视觉异常。 让我们来看看一个可能的体系结构,用于大规模实施实时流分析以进行欺诈检测: 对于部署到事件流平台的每个用例,您始终可以选择传统和尖端方法和算法。 有时,现有的业务规则或统计模型工作正常并不是所有的东西都需要实时。尖端技术令人敬畏,但不需要一切。但是所有这些技术和概念必须无缝、可靠地相互配合。 下面显示了映射到技术的上述用例: 我们利用以下技术: 任何其他技术都可以添加/更换/删除,具体取决于您的用例。例如,与上述体系结构相得益彰是完全精细和常见的 听起来很酷吗?你想自己试试吗? 请查看我的Github 页面。存储库为 Apache Kafka 和机器学习提供了各种演示和代码示例,使用不同的 ML 技术,如 TensorFlow、DL4J 和 H2O。 这些例子并不集中在金融业。但是,您可以轻松地将此映射到您的用例;我看到金融界的各种部署,与下面的例子完全一样。 以下是 Github 存储库的一些亮点: 请查看这些幻灯片和视频录制,详细了解如何使用 Kafka 生态系统和您最喜爱的 ML 工具、云服务和其他基础结构组件构建 ML 基础结构。 我更详细地解释了阿帕奇卡夫卡如何和为什么成为金融行业可靠和可扩展的流媒体基础设施的实际标准。 AI / 机器学习和 Apache Kafka 生态系统是实时大规模训练、部署和监控分析模型的重要组合。它们出现在项目中越来越多,但仍感觉像是科学项目的流行语和炒作。因此,我详细讨论: 我们使用阿帕奇卡夫卡、卡夫卡连接、卡夫卡流、ksqlDB、TensorFlow、TF 服务、TF IO、混合分层存储、谷歌云平台 (GCP)、谷歌云存储 (GCS) 等技术构建混合 ML 架构。 这里是幻灯片平台的”卡夫卡 + 机器学习在银行和金融服务”。 以下视频录制将引导您浏览上述幻灯片:
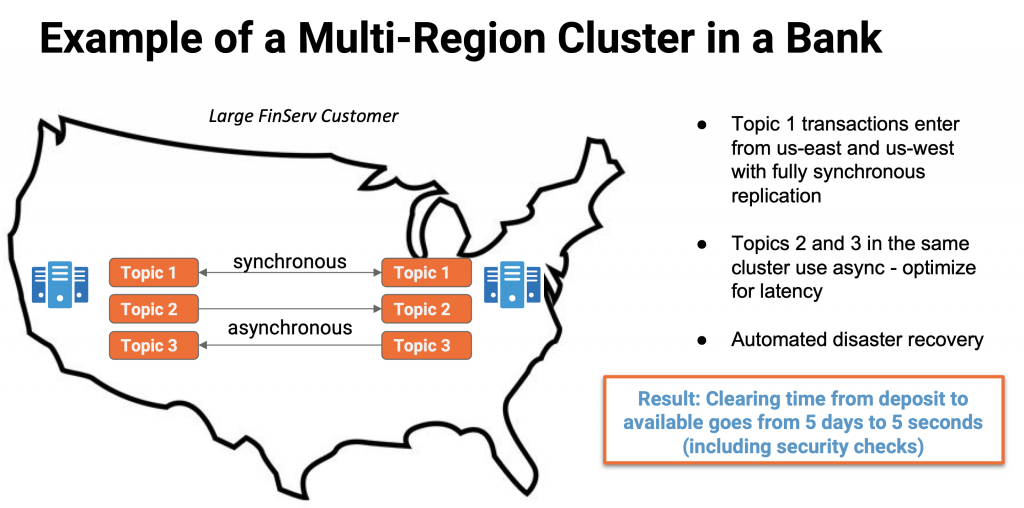
最关键的基础架构需要24/7 的可用性和零数据丢失,即使在发生灾难(即完整的数据中心或云区域中断)时也是如此但是,模型评分和监控(例如,在即时付款应用程序中的欺诈检测)应连续运行,停机时间为零,数据丢失为零(也称为 RPO = 0,RTO = 0)。 银行及金融业是所有行业中关键使用案例数量最多的行业。卡夫卡在大自然中非常可用。但是,没有停机和未丢失数据丢失的灾难恢复仍然不容易解决。镜像制造商 2 或”集成复制器”等工具对于某些方案来说已经足够了。我需要保证零停机时间和零数据丢失,需要额外的工具。 汇能提供多区域集群(MRC)来解决这个问题。让我们来看看大型 FinServ 客户的体系结构: 此体系结构提供与 RPO = 0 和 RTO = 0 的业务连续性,因为数据在美国东部和美国西部地区之间使用 Kafka 原生技术同步复制。此体系结构具有各种优点,包括: 这个银行用例是关于实时从”存款”到”可用”的清算时间。可以为您的任务关键型 ML 用例(如欺诈检测)部署完全相同的体系结构。 很酷,不是吗?关于”分布式、混合、边缘和全球 Apache Kafka 部署的体系结构模式“,还有更多需要了解的信息。 无论金融服务或任何其他行业,以下是实现可扩展、实时 ML 基础架构的关键经验教训: 有哪些用例,您拥有哪些挑战架构?请分享您的见解,让我们讨论.让我们连接LinkedIn保持联系!
银行与金融服务中的机器学习
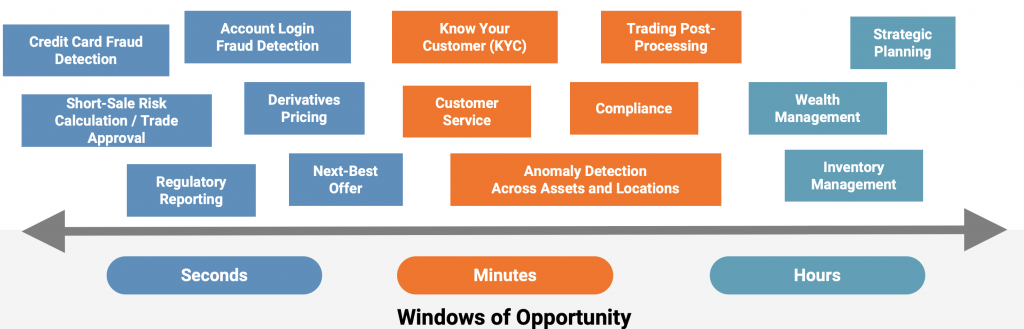
被明确编程在哪里看。不同的算法应用于历史数据,以查找见解和模式。然后,这些见解存储在分析模型中,以便对新事件进行预测。ML 算法的一些示例:
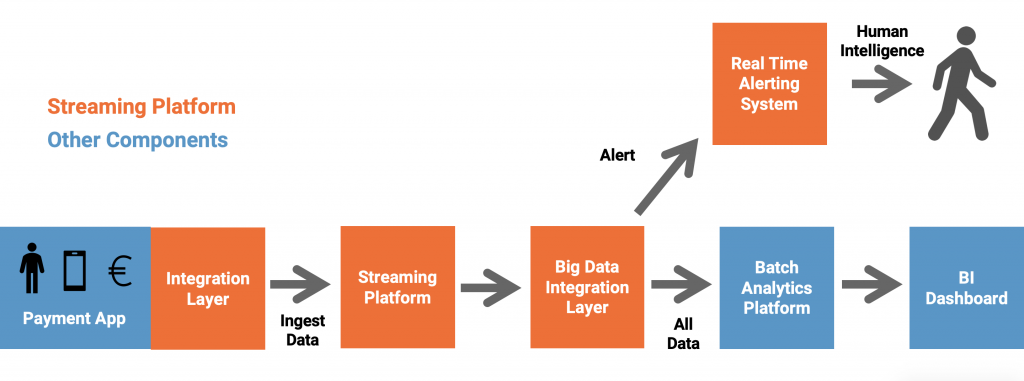
用于模型培训、评分和监控的机器学习管道
 大多数 ML 管道的一些关键要求:
大多数 ML 管道的一些关键要求:
阿帕奇卡夫卡和机器学习 /深度学习
欺诈检测 – 帮助金融行业进行事件流和 AI / 机器学习
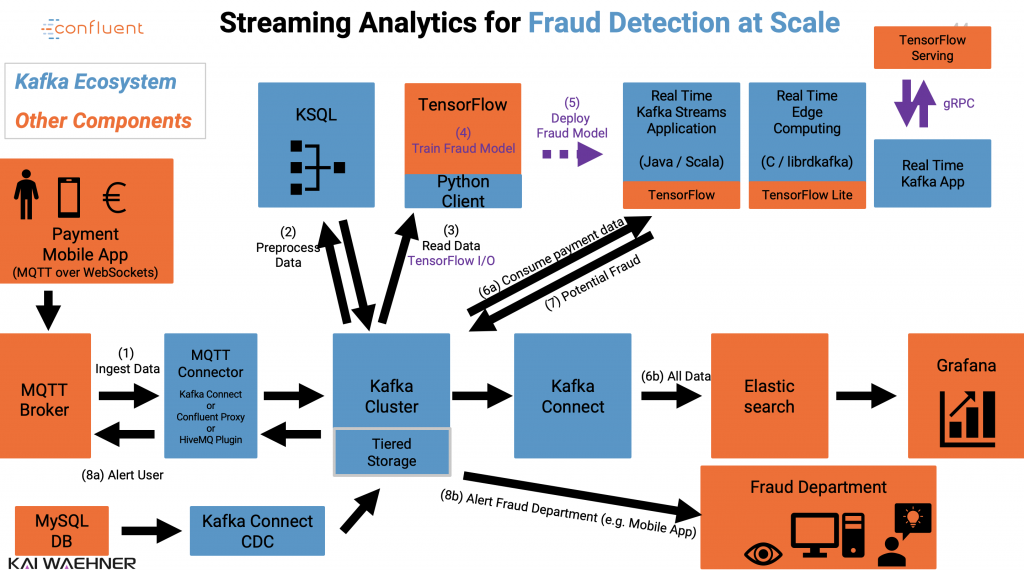
用于实时欺诈检测的流分析
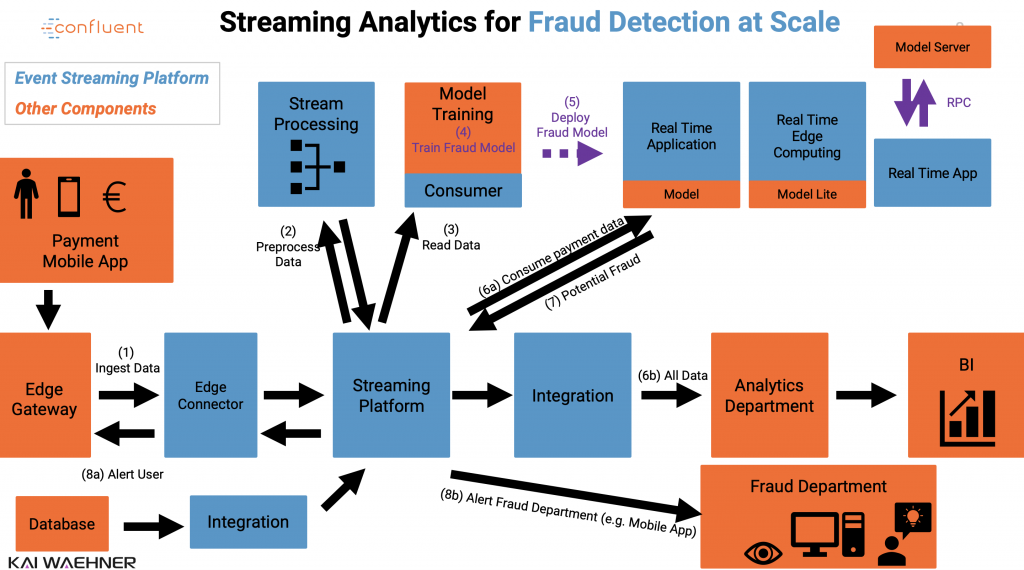
与阿帕奇卡夫卡,卡夫卡流卡夫卡连接,ksqlDB和TensorFlow的欺诈检测
阿帕奇卡夫卡和机器学习的演示和代码示例
幻灯片/视频录制:卡夫卡 + ML 在金融行业
多区域灾难恢复
具有零停机时间和零数据丢失的机器学习体系结构
卡夫卡 • 机器学习 • 24/7 = 实时