
介绍
云计算之所以在增长,有几个原因:与支持内部基础设施相比,云计算灵活、相对便宜,并且可实现出色的资源分配自动化,从而更降低成本。
云计算还允许横向可扩展性,这在当今数字时代的许多企业中至关重要。当要处理的数据量逐年增加时,人们不能依赖老式的垂直可伸缩性模型。在这个分布式计算时代,数据应分布在多个更便宜的系统中,在那里数据可以可靠地存储、处理,并在需要时返回给用户。
构建此类系统并非易事,但幸运的是,有一些解决方案非常适合云架构。我说的是阿帕奇·伊格。
准备环境
我将使用 AWS 云部署 Ignite 群集。因此,让我们来谈谈环境设置。
在这里,为了学习的目的,最小的免费层机就足够了。我选择了Ubuntu 18.04图像,但它没有造成很大的影响。
在部署第一台计算机之前,我们需要配置所谓的安全组。在这里,应定义 Ignite 实例所需的端口的网络规则。
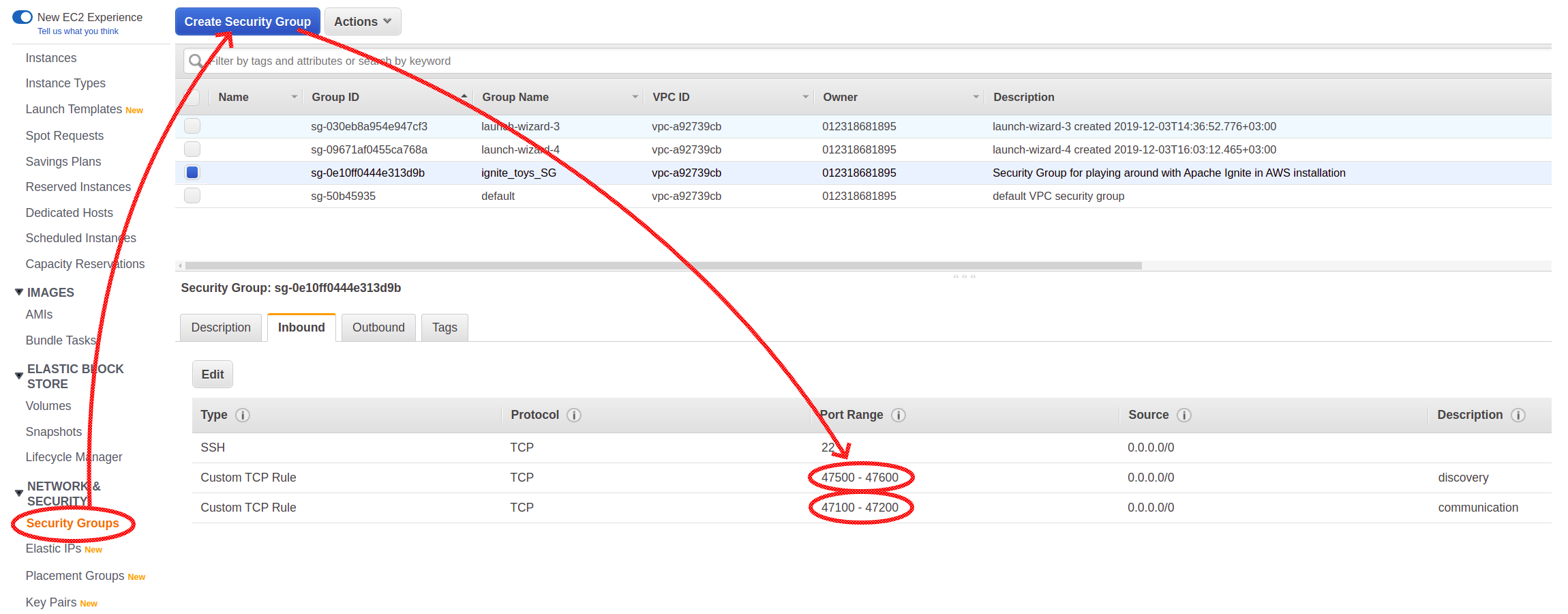
显式配置了两个端口范围。端口范围 47500-47600 由发现机制(允许节点相互查找并形成群集)使用,47100-47200 由通信子系统使用,使节点能够相互发送直接消息。
现在,在配置安全组后,是时候启动和设置我们的计算机了。
机器已经启动,但它们缺乏一个基本的软件:Java。没问题;只需使用以下命令安装 Java:
对于 RedHat/Centos 分布,命令看起来略有不同:
伟大!我们距离在云中启动和运行第一个 Ignite 实例仅一步之遥!
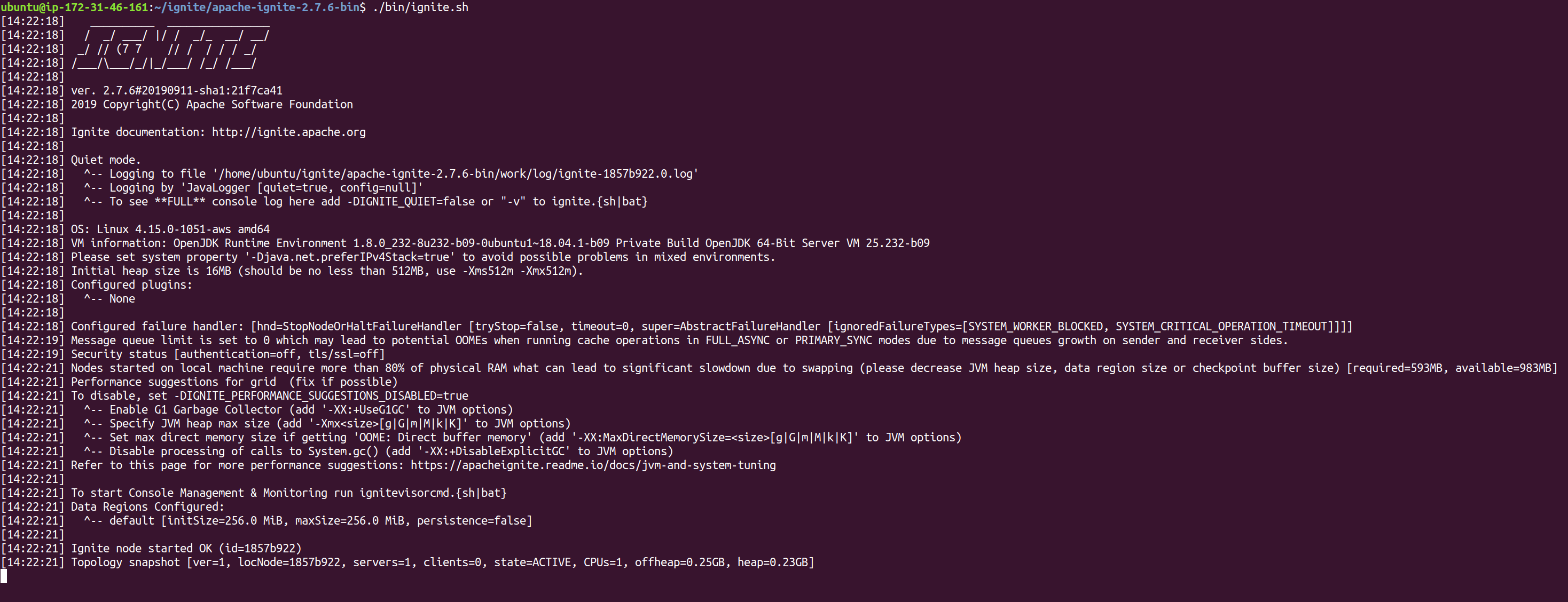
现在让我们开始:
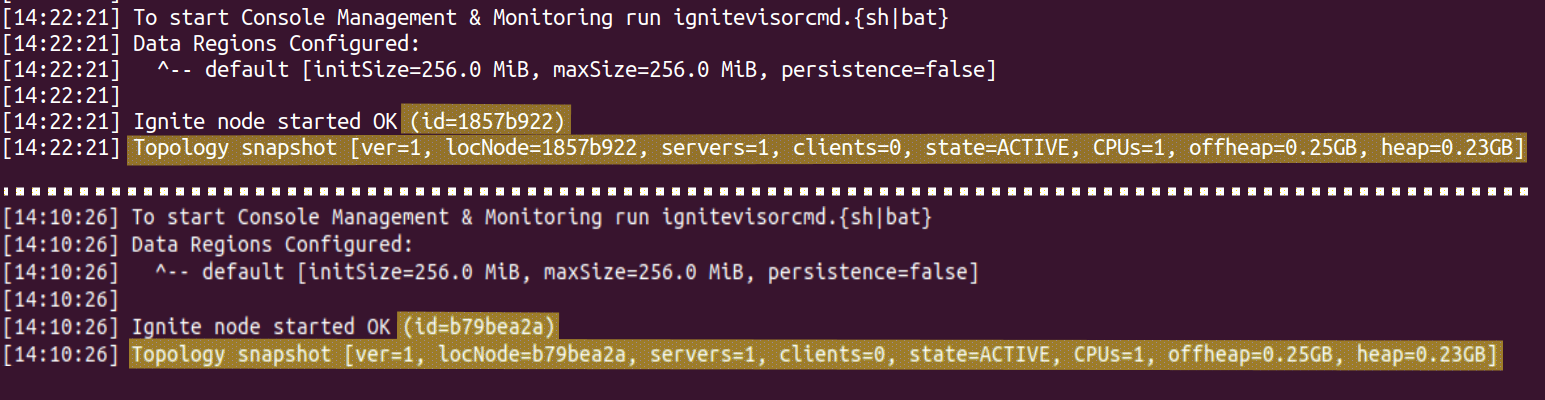
Sh 我们已经取得了很大的进步。 我们准备了环境,找出了获取二进制文件的位置以及如何使用这些二进制文件启动 Ignite 节点。 但是,要有一个真正分布式的系统,我们需要另一个节点。只需重复所有这些步骤(创建和配置 AWS 实例、下载和解压缩二进制文件),然后再启动一个 Ignite 实例。 现在是时候从我们拥有的节点组装一个群集了。是的,启动一堆节点不足以构建群集,并且从日志中变得明显:每个节点在日志中都有以下行。 此消息意味着两个节点已组成两个独立的群集,而不是相互发现并形成单个群集。 为了建立一个真正集群的环境,我们需要加深对群集如何组装的理解。 名为”发现”的特殊服务在这一过程中起着至关重要的作用。它允许节点相互查找并形成群集。当节点启动时,它会请求其发现实例查找现有群集,并尝试加入该群集,而不是创建新群集。 配置 DiscoverySPI 以能够定位群集是最终用户的责任,并且非常简单 在你最喜欢的文本编辑器中打开配置文件…
…添加以下块:
我们在这里看到已经为服务器节点配置的相同属性:发现SPI、IpFinder 等。除了突出显示的布尔标志将常规 Ignite 节点转换为客户端之外,这里有很多相似之处。 使用此配置,我启动客户端节点并请求它创建缓存,将一个简单的字符串放入其中,然后读取该值:
嗯,我明白有些事情不对。我的简单程序开始,但它不打印任何结果。同时,我在服务器日志中看到服务器将客户端节点添加到拓扑中: 那可能出什么问题呢?答案是,在云环境中,还必须在服务器端配置一件事 由于我们的服务器在 AWS 中运行,它们与外部世界之间存在某种 NAT。服务器知道他们的内部(NAT)IP 地址,但不知道他们分配了哪些公共 IP 地址。为了向服务器提供此映射的信息,从而允许它们与远程客户端通信,我们需要在服务器端配置地址解析器。 首先,停止两个服务器节点。接下来,将以下块添加到每个服务器配置中,同样在配置 XML 的根元素下。此处,私有 IP 和公共 IP 是修改配置的同一服务器的地址:
重新启动服务器以应用更改并重新运行程序。请注意,在虚拟机重新启动后,公共 IP 地址可能会更改,因此我们的第一个群集的配置不是很可靠。 现在,我们看到预期的结果:程序完成并从缓存中检索刚刚放在那里的值。 将点火群集部署到 AWS 云需要一些简单的技巧。当执行第一步时,我们可以执行更多有趣的事情,例如将数据流式传输到群集中,使用数据流式处理器、执行查询或使用 JDBC/ODBC 连接等其他接口连接到群集。 但是,最好记住,开发更多有用的应用程序需要更多的资源,并且免费 AWS 实例很快就耗尽了容量。无论 Ignite 是用作主数据库还是内存中缓存层,更多的内存意味着更好的性能,对于类似 prod 的环境,x1 层的强大实例是最好的。
准备 AWS 实例时选择安全组
xxxxxxx
*/苏多贴切安装开伊德克-8-jdk
xxxxxxx
*/sudo yum 安装 java-1.8.0-openjdk.x86_64
我从官方网站下载了最新的二进制分发,并解压缩了它:xxxxxxx
*/点燃$ 解压缩阿帕奇-点燃-2.7.6-bin.zip
xxxxxxx
*/点燃/阿帕-点燃-2.7.6-bin$
xxxxxxx
*/点燃/阿帕-点燃-2.7.6-bin$ vim配置/默认配置.xml
xxxxxxx
cfg.设置客户端模式(true);
Tcp发现VmIpFinderipFinder=新的Tcp发现VmIpFinder();
ipFinder.设置地址(数组)。asList("54.154.28.251") );
Tcp发现Spispi=新的Tcp 发现斯皮();
窥探。setIpFinder(ipFinder);
设置发现斯皮(窥探);
xxxxxxx
开始(cfg) |
点火缓存缓存=客户端
.获取Or创建缓存(
新的缓存配置("客户端缓存")
.设置备份(1)
.设置亲和(新的会合函数(假4)
)
缓存。放(1"myString");
系统。出。println("->>->->键"1"的值:"=+缓存)。获取(1));
}

AddressResolver :。xxxxxxx
[ <豆类]"org.apache.ignite.配置.基本地址解析器">
<构造师-arg>
<地图>
<输入键="<私有 IP>"值="<公共 IP>"/>
</地图>
</构造器-arg>
[</属性>
结论
