
老实说, “数据湖” 是大家都在谈论的最新话题之一。与许多流行词一样, 很少人真正知道如何解释它是什么, 它应该做什么, 和/或如何设计和构建一个。正如他们看上去的普遍情况一样, 你可能会惊讶地发现Gartner 预测只有15% 的数据湖项目能够投入生产。Forrester 预测, 33% 的企业将会把他们尝试的数据湖项目从生命支持中带走。太吓人了!数据湖是关于从企业数据中获取价值的, 而且, 鉴于这些统计数据, 其涅槃似乎是相当难以捉摸的。我想改变这一点, 分享我的想法, 并希望提供一些指导, 让你考虑如何设计, 构建和使用一个成功的数据湖: 一个敏捷的数据湖。为什么选择敏捷?因为要成功, 它必须是。
好的, 首先, 让我们看一下维基百科定义的数据湖是什么:
“数据湖是存储存储库, 它以本机格式保存大量原始数据, 并将其作为结构化、半结构化和非结构化数据进行整合。
不错。然而, 考虑到我们需要从数据湖中获取价值, 这个维基百科的定义还不够。为什么?原因很简单;您可以将任何数据放入湖中, 但需要获取数据, 这意味着某些结构必须存在。数据湖的真正想法是有一个单一的位置来存储所有企业数据, 从原始数据 (这意味着源系统数据的精确副本) 通过转换后的数据, 然后用于各种业务需求, 包括报告、可视化、分析、机器学习、数据科学等等。
我喜欢 “修订” 的定义从塔玛拉沉闷, 主要传教士, 亚马逊 Web 服务, 谁说:
“数据湖是存储存储库, 它以本机格式保存大量原始数据, 包括结构化、半结构化和非结构化数据, 在需要数据之前不定义数据结构和要求。
好多了!甚至像敏捷一样。这是一个更好的定义的原因是, 它既包含数据结构的先决条件, 又将存储的数据以某种方式在将来的某个时刻使用。从这一点, 我们可以安全地期待价值和开发敏捷的方法是绝对必要的。因此, 数据湖包括关系数据库 (基本行和列) 的结构化数据、半结构化数据 (如 CSV、日志、XML、JSON)、非结构化数据 (电子邮件、文档、pdf) 甚至二进制数据 (通常为图像、图片、音频和视频) 从而创建一个集中式数据存储, 以适应所有形式的数据。然后, 数据湖提供了一个信息平台, 在需要时可以为许多业务用例服务。数据进入湖里还不够, 数据也必须出来。
而且, 我们希望避免 “数据沼泽” 这实质上是一个恶化和/或非托管的数据湖, 它的预期用户无法访问和/或无法使用, 为企业提供几乎没有业务价值。到目前为止我们还在同一页吗?好。
数据湖: 在开始
在我们深入了解之前, 我想分享我们是如何到达这里的。数据湖代表了数据激增 (体积-变化速度)、遗留业务应用程序的增长以及大量新数据源 (IoT、WSL、RSS、社交媒体等) 以及从内部部署到云 (以及混合) 的动态变化。.
此外, 业务流程变得更加复杂, 新的技术最近引入了增强业务洞察力和数据挖掘, 再加上以机器学习和数据科学等新方式探索数据wikipedia.org/wiki/Bill_Inmon “rel =” nofollow “目标 =” _blank “>> 比尔 Inmon 和拉尔夫-的, 现在到敏捷数据湖的业务报告 (由丹 Linstedt, 你真正的, 和其他一些勇敢的灵魂)支持各种业务用例, 如下所示。
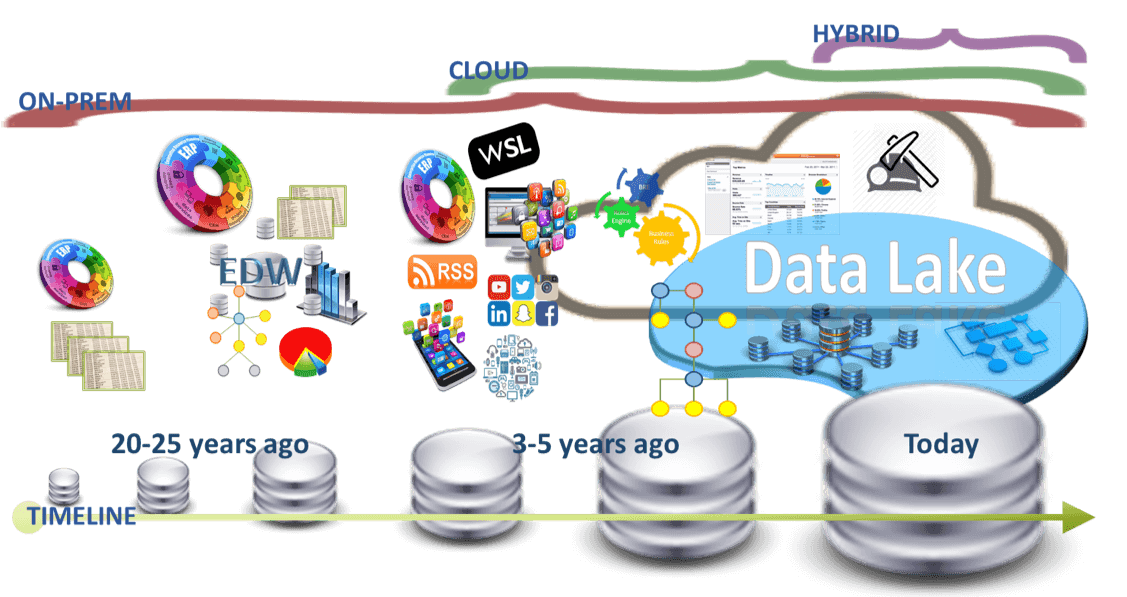
对我来说, 数据湖代表了这一戏剧性数据演变的结果, 并最终应提供一个共同的基础信息仓库架构, 可以在内部部署, 在云中, 或混合生态系统。
成功的数据湖是基于模式的、元数据驱动的 (用于自动化) 业务数据存储库、会计数据治理和数据安全 (ala GDPR 和 PII) 要求。湖中的数据应提供合并数据和 “真相记录” 的聚合, 确保信息准确性 (除非你知道如何) 和及时性, 否则很难完成。遵循敏捷/Scrum 方法, 使用元数据管理、应用数据分析、主数据管理等, 我认为数据湖必须代表 “全面质量管理” 信息系统。还跟我在一起?伟大!
什么是数据湖?

实质上, 数据湖用于任何以数据为中心的业务用例, 即系统 (企业) 应用程序的下游, 这有助于推动企业洞察力和运营效率。下面是一些常见的示例:
- 业务信息、系统集成和实时数据处理。
- 报告、仪表板和分析。
- 业务洞察、数据挖掘、机器学习和数据科学。
- 客户、供应商、产品和服务360。
如何构建敏捷数据湖?正如您所看到的, 有许多方法可以从成功的数据湖中获益。我的问题是, 你在考虑这些吗?我打赌你是。我的下一个问题是: 你知道怎么去那里吗?你能建立一个数据湖正确的方式, 并避免沼泽?我假设你正在读这篇文章以了解更多。让我们继续。
有三个关键原则, 我相信你必须首先理解, 必须接受:
- 正确实施的生态系统、数据模型、体系结构和方法。
- 将卓越的数据处理、治理和安全纳入其中。
- 故意使用工作设计模式和最佳做法。
一个成功的数据湖也必须是敏捷的, 然后成为一个数据处理和信息传递机制, 旨在增加业务决策并增强领域知识。因此, 数据湖必须具有托管生命周期。这个生命周期包含三关键阶段: 误食、适应和消费。
摄入:
- 提取原始源数据, 在着陆区或临时区域中累积 (通常写入平面文件) 以进行下游处理和存档。
适应:
- 将此数据加载并转换为可用格式, 以供业务用户进一步处理和/或使用。
消费:
- 数据聚合 (KPI、数据点或指标)。
- 分析 (实际值、预测和趋势)。
- 机器学习、数据挖掘和数据科学。
- 操作系统反馈和出站数据馈送。
- 可视化和报告。
挑战是如何避免沼泽你真的必须远离你的 “遗产” 思想;适应并采用 “现代” 方法。这是必不可少的。不要落入认为你知道数据湖是什么以及它如何工作, 直到你考虑这些关键点的陷阱。

好吧, 让我们再研究一下这三个阶段。数据摄取是关于捕获数据, 管理它, 并让它准备后续处理。我认为这就像一个箱子的数据, 倾倒到湖的沙滩上;一个被称为 “持续的临时区域” 的着陆区。持久的, 因为一旦它到达, 它停留在那里;对于所有实际的目的, 一旦处理下游, 成为一个有效的档案 (你不必复制它在别处)。此 PSA 将包含数据、文本、语音、视频或无论它是什么, 累积。
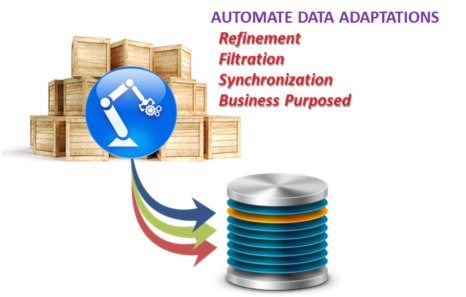 你可能会注意到, 我还没有谈论技术。我会但是, 至少让我指出, 根据 PSA 使用的技术, 您可能需要在某一时刻卸载这些数据。我的想法是, 一个高效的文件存储解决方案最适合这个第一阶段。
你可能会注意到, 我还没有谈论技术。我会但是, 至少让我指出, 根据 PSA 使用的技术, 您可能需要在某一时刻卸载这些数据。我的想法是, 一个高效的文件存储解决方案最适合这个第一阶段。
数据适应是一种全面、智能的数据聚结, 它们必须有机地适应, 才能生存和提供价值。这些改编采用多种形式 (我们将在下面介绍), 但基本上驻留在原始的, 最低水平的造粒, 数据模型, 然后可以进一步处理, 或正如我所说的, 业务的用途, 为各种领域使用情况。这里的数据处理要求可以很好地涉及, 所以我希望尽可能多的自动化。自动化需要元数据。元数据管理假定治理。别忘了安全我们稍后再谈这些。
 数据消耗不仅仅是商业用户, 它是关于商业信息, 它支持的知识, 希望, 从它得到的智慧。你可能熟悉DIKW 金字塔;数据 > 信息 > 知识 > 智慧。我喜欢在 “知识” 之后插入 “理解”, 因为它会导致智慧。
数据消耗不仅仅是商业用户, 它是关于商业信息, 它支持的知识, 希望, 从它得到的智慧。你可能熟悉DIKW 金字塔;数据 > 信息 > 知识 > 智慧。我喜欢在 “知识” 之后插入 “理解”, 因为它会导致智慧。
数据应视为公司资产, 并投资于此。然后, 数据成为一种商品, 使我们能够专注于从它获得的信息、知识、理解和智慧。因此, 它是关于数据和从它获取价值。
1部分。在下次我们将介绍数据存储、数据安全等方面进行调整!