
随着 AI 在各行业落地的进一步深化和应用数据量的飞速增长,越来越多的 AI 科学家痛苦地发现数据 ETL、数据仓库和海量特征向量检索等数据处理流程花费了他们大量宝贵的时间和精力。AI 数据中台 Mega 打破了人工智能和数据处理之间的分界和壁垒,提供 GPU 加速的一站式 AI 数据科学解决方案,将数据 ETL、数据仓库、模型训练、推理和部署等多个流程进行融合。在实践中,Mega 成功地帮助 AI 科学家将工作效率和产出提升5~8倍。
作者:星爵
编辑:王诗珊

星爵是ZILLIZ 的创始人兼 CEO,是数据库、人工智能和高性能计算领域的专家。他曾长期就职于甲骨文(Oracle) 公司美国总部,负责其数据库系统的核心研发工作。他作为奠基人之一研发的 Oracle 12c 多租户数据库(Oracle Multitenant)被誉为 Oracle 数据库在过去10年中最具革命性的创新,迄今已经为公司创造了超过10亿美金的营收。星爵毕业于华中科技大学,在美国威斯康星大学麦迪逊分校获得计算机硕士学位。
本文根据星爵老师在DTCC 2019数据库大会分享内容整理而成,介绍了AI 数据中台 Mega及其应用,主要包括当下AI工程师的痛点分析、Mega系统的应用及解决方案等。
AI工程师的一天
在过去的几年AI越来越火,AI的应用也越来越多。然而AI工程却特别缺乏,一个公司里面很多事情都要用上AI,各种业务系统、推荐系统、业务的分析系统各方面都是用AI来做。导致现在AI工程师一天到晚都特别的忙。
下面是国外的一家AI工程师Robot的一天:
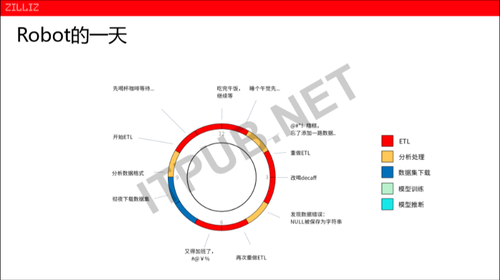
早上9点钟开始上班,在前一天下班前他就将数据挂在后台通宵下载的前提下,上班第一件事开始分析数据格式,做一些数据清理、排掉、去除等,光数据清理就要花费了他一上午的时间。
到了下午,ETL终于做完了!检查一下数据,发现在数据清理的时,忘记拖进来一列数据,这时模型训练里面可能会少一个维度,少一个维度模型就做不了了,没办法只能重新开始。下午4点钟,重新做完一期,检查过程中发现一个正则表达式写错了,AI的模型又无法训练了。到下午5点钟又要重新再做一次ETL,做到7点多的时候其实还没有做完。
我们考虑一下如果日复一日的这样工作,我们发现他的时间分配问题很大,大部分的时间都花在了数据的清洗的过程中、数据初步的分析等等,一天的工作里基本没有碰到真正的模型跟训练。
AI工程师工作中耗时占比最长的是什么?
这是美国的福布斯在2016年给出的一个调查。
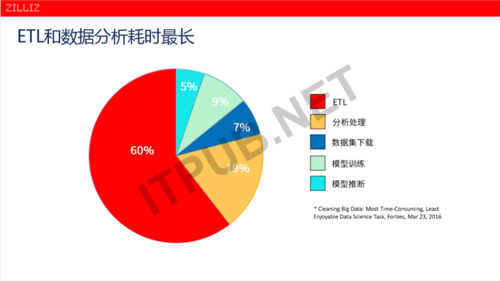
ETL跟数据分析是在整个AI工程师的工作中耗时占比最长的一个部分。我们看到红色的部分跟黄色的部分占比最大,红色的部分是做数据ETL,黄色的部分是做初步的数据分析,这两部分加起来,在AI工程师里面的工作时间占比高达79%。而实际,严格意义上的AI模型训练跟模型推断,加起来的时间一个是9%,一个是5%,加起来的话占比时间就区区14%。现在的AI工程、AI科学里面,大部分的时间都耗在了前面的数据清洗、数据的提取、数据的处理。
AI工程师最不喜欢的工作是什么?
这也是福布斯当时给出的一个调查问卷,他调查了700多名美国的AI工程师,他们最不喜欢的工作是什么?
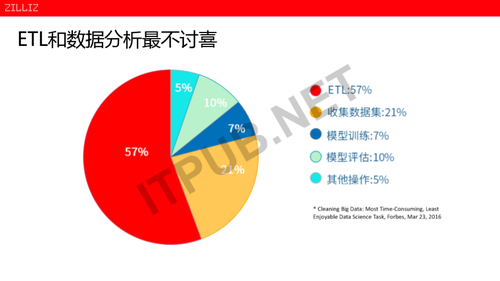
他们最不喜欢的工作流程是ETL和数据分析,回答这两个部分的分别占57%、21%。总体来说的话,大概有79%的AI科学家认为这两部分工作是最烦,最不愿意做的,那怎么办呢?在想怎么办之前,我们看看这是什么原因呢?
问题的根源是什么?
AI是一个新兴的产业,虽然AI的算法在上个世纪80年代已经比较完整了,但是AI作为一个新兴的产业是过去3-5年才蓬勃发展的。AI的发展在3-5年有一个爆发性的增长,而我们看到数据处理的体系结构,不管是以前的关系型数据库、大数据、文档数据库等等。其实在过去的40多年里,它实际上发展得不温不火。一个新兴的AI 产业爆发性的需求跟我们日益落后的数据处理基础架构之间产生了一些根本矛盾。

这些矛盾体现在几个方面:
第一个方面,因为AI产业的兴起带来了异构计算的资源,计算的资源越来越多的异构化。

在以前,所有的处理基本上都是由CPU来进行处理的,而现在AI的产品里面,基本上都是用GPU和类似于GPU的一些综合的处理架构进行处理的。我们发现以前的数据处理架构和流程框架都以CPU为核心,而现在AI的整个处理流程是以GPU为核心。如果领导说要上一个AI的项目,要做深度学习、人工智能。第一步大家肯定说:“先去买一台GPU的服务器”。
计算的资源越来越差异化、异构化的同时,数据处理的框架其实是有一个很明显断层的。
第二个方面,在AI的时代,产生了越来越多的新兴的数据类型。不管是说数据库,还是数据处理系统也好,处理的类型、种类、范畴、外延是在不断扩展的。以前文件的数据、关系的数据、劣势的数据、文档的数据等等,而最近的几年AI最常见的几种数据类型,比如图片、视频、语音、还有文本等,这些文本本身就是一些结构化的对象服务数据类型。它跟以前的各种结构化的类型已经有很大的不同了,但是这些类型通过AI的训练、神经网络、各种网络的训练以后,一般会得出一个特征向量。
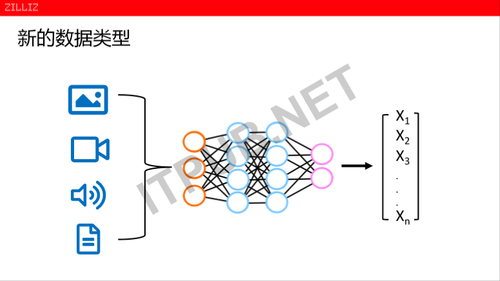
特征向量有一个特点,在文本和图片方面都会变成一个特征向量表达。另外一方面特征向量的维度,从几百维到几万维是很大的一个跨度。人脸识别现在是200多的维度,如果说一个文本跟识别的模型,可能会达到几万甚至几十万的一个维度,是一个很宽向量。在很宽的向量处理的同时,传统的数据模型里面都有一个困扰,256个维度的一个向量,我把它放到数据库里面,应该怎么去存呢?
把它存成256列,访问的时候性能都特别低。因为传统数据库在处理高危数据的时候就有问题,包括劣势数据。如果说要处理到几千维几万维的东西,也有一个难的性能问题。
另外一方面,其实在向量上深度学习、定义一系列预算,比如现在的转换变化,还有最后面的人脸识别、视频识别。相似性对相似度模型算相似度。假设我们在一个大的人脸库里面,像中国的人脸库大概有16到18亿的静态的人脸库。来一个新的图片,过去要匹配每一个人脸,现在其实是一个向量在18亿条的256维的向量里面计算最近的相似度,我们还希望能够一个秒级甚至毫秒的一个项目。所以AI在数据类型,还有数据操作方面,已经达到我们心理的需求。
作为一个AI科学家,我需要不断的切换我的工具集。同时我还要在每个工具集之间写很多的连接器,要写很多数据处理的流程。如果我们有一天,有一个完美的工具集。只要指定数据来源,指定几个模型,指定几个数据清洗的规则,按一个键,从头到尾全部帮我们做完,这样的话我们就轻松了,那就不用做完ETL后要等一下它有没有出错,因为整个自动化就可以像数据下载一样,在下班之前把东西提交了,第二天早上过来看结果。
Mega是什么?
在这里面还有一个更优胜者,在过去的几年里面AI的火热,大量的研发的精力、大量的科研、模型训练,使我们知道现在不管是哪个模型,在过去的五年有一个飞速的提高。AI的发展模型跟算法有一个飞跃的成长,但是包括ETL数据仓库,包括大客户的部署框架、基础架构落后于AI的需求。在过去的三年里面,ZILLIZ一直专注做GPU加速、AI数据中台的研发,我们耗时三年,大概花了接近200个人员,我们研发出来的一套系统叫做Mega。Mega理念是什么呢?Mega理念是将所有的资源,包括计算资源,还有存储资源进行一个统一的管理和调度。

在中间我们看到,在所有的计算资源里面包括了CPU、GPU,还包括在云端可以用到谷歌的CPU,包括FPGA一些计算资源进行训练。如果把这些存储异构的计算,用一种统一的接口进行管理,把原数据、逻辑、资源等占用的时间进行一个统一的调度。在整个的A I生命周期里面进行ETL、模型训练和推理部署时,其实不是一个单线条,而是一个不断循环迭代的过程,通过数据提取以后,拿到一些数据集合训练,训练完以后一个模型作为验证的记录不怎么好,就需要拿另外一些数据,或者把数据清洗规则进行修改,这是一个市场的迭代的过程。迭代过程中,我们希望根据下面的资源,不论是计算资源还是数据资源,他们的异构性、存在性、可获得性进行高效的调度。
在之上的话,ZILLIZ希望给各行各业的应用,不管是人脸识别、语音识别、视频的分析,还是自然语言处理等等,提供统一接口。
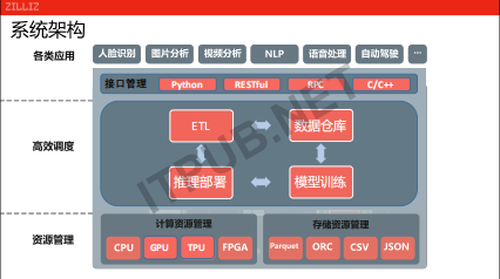
Mega优势是什么?
这是一个系统的动态示意图,我们看到在ETL框架里面,MegaETL跟传统ETL工具,生态做了一个很好的总和。我们看看它的优势在什么地方,在整个环节里面,不管从ETL、数据仓库、训练、以及部署跟决策整个流程,是跟现有的工具集 、生态做了更完整的一个整合。我们希望从第一天开始,大家不管是使用的界面,还是编程的方法,都跟以前使用的东西比较熟悉,减少学习的曲线。
Mega特点是什么?
整个流程都在统一的框架下面,用GPU新一代的、更快的、更好的、更高性价比的资源来进行处理。
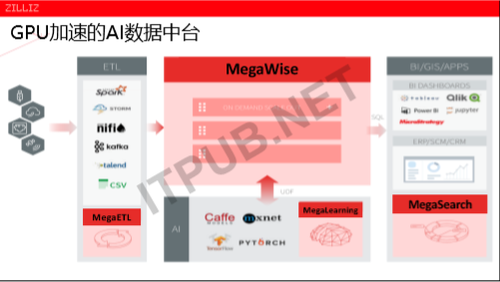
那ZILLIZ怎么做的呢?我们知道ETL是大家都公认的脏活和累活,本质上来说就是把一类的数据进行提取,根据使用的规则进行转换,转换后加载到下游的一个目标系统。整个ETL的过程耗时特别长,大家可能都有过同样的经历,像有一些客户,他们如果处理几个TB的数据,可能就以天为单位计算它的ETL周期的;如有几十个TB的话,大概是几个小时为单位;有几百个TB的话,那一般都是以月为单位,衡量ETL保障完成。
有没有办法去加速呢?这个时候GPU的优势就体现出来了,数据的ETL前面是数据提取,提取到转换的过程,本质上来说是一个计算的过程。在过程上它有一个特别明显的优势,在数据的提取的过程中,其实可以高并发的。
举个例子来说,我们在系统里面有110条的记录,对每一条记录用一个规则,要把一个字符串的最后五位把它扔掉,只留前面的十位。这个规则对于每一套记录都是一样的。这个时候对11条规则的每一条规则,我可以进行一个很好的处理。我们知道GPU它的强项就是算力特别强,任务如果是能够并行的,就能够特别好的锁定更高的性能。
在实际中,我们有几个案例,比如多个数据源规划的案例。在金融方面从多个交易所或者多个第三方机构会拿到不同的数据源。在用之前会做一个统一的数据视图或者是统一数据源的过程,这个时候就是要把多个数据源,进行去重、规划。这个过程我们用的MegaETL、GPU来加速,性能提升50到60倍之间的提速。50到60倍,可能大家还没有特别好的概念。50个小时,基本可以把两天两夜的工作,在一个小时内干完,三个小时之内的工作量在10分钟之内干完。
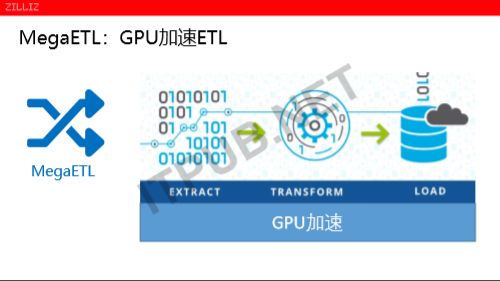
第二,我们来说说MegaWise,MegaWise是用GPU来加速数据分析的,数据分析过程,也是各个的数据源。将有些数据,做一些复杂的查询,不管是多张表关联,还是比较简单的数据过滤,又或者做数据的聚合。这些数据量比较大的时候,它的性能就会成为一个瓶颈。在10年前有一种叫大数据方案,用集群来做的,集群的本质上来说,一台服务器如果处理不了,那么就用多台服务器来做并行。前提是数据分析过程做工作可以很好运行情况下。
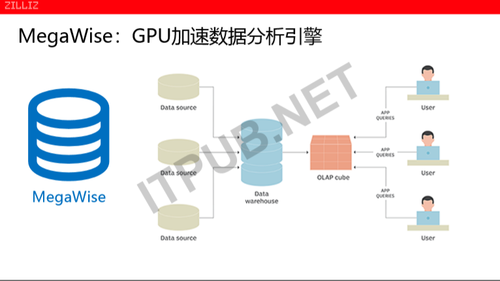
如果有100个T的数据,把数据切成很小的一片,每一片10个G或者是100个G,每一台服务器上面就处理10个G或者100个G的数据。因为100台服务器并行处理,所以就提高了性能处理的响应时间。那么既然是并行的,在数据处理分析里有个并行的理论技术,这个时候就变成GPU处理的数据了。GPU它对所有关系,包括对并行计算是特别有优势的。当我们通过GPU来进行高并发的数据处理,我们在一个节点里面,总共大概有17万个处理核心。也就意味着在任何一个时刻,任何一个施工周期,其实是有17万个核心已经在并发的处理。如果说传统的CPU上运行的各种数据,虽然也可以开动多线程、超线程,但它的线程的数量,一般来说是几十到小一百为单位。而我们在这个GPU的处理框架有一个节点处理的并行度能够达到十几万,这就大大的提高了数据处理的效率。
第三个,MegaLearning是做什么事情的呢?我们看到,在过去的十年里每一个企业每一个行业,陈列了很多的大数据的资产。而这些数据如果要训练的话,是没有一个特别直接的一个接口,分为两方面分析。
一方面来说,这些数据系统是跑在CPU之上;另一方面来说,AI的新需求包括它们调度的一些机制数据,获取的只有机制,跟这些传统的做大数据资产端、大数据系统端,是相互独立的并且是不知道需求的。那么让所有的用户能够更好地利用好自己的大数据资产,同时让大数据资产以直接的方式,把AI系统、AI的训练、AI的推理,能够构建在现有的大数据系统之上。
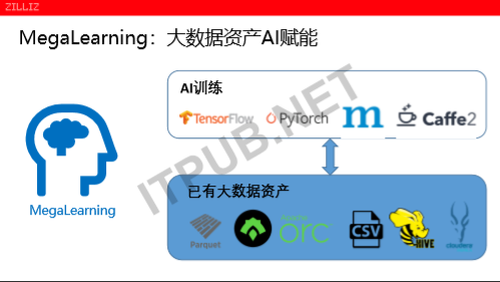
举一个简单的例子来说,我想大家都喝过咖啡。有一家企业,它用的是一个大数据系统,数据文件的沉淀,上百个T它可以整。现在在这里面做一些训练,比如说过去的20年里面的一个用户交易有一个关键信息。我说在这里面我要去提取用户的特征,或者说看哪些用户的有哪些异常的特征把它提出来,并且希望用一种深度学习的模型训练。显卡的显存一般在十个G,如果是分布式的计算大概几百个G,那么数据加载会更多,那么就会在python程序里面先写一个缓冲词做一个调度,先把数据分片,这一百个数据分片的数据里面,根据目标系统的总量,十个G十个G的去拿。
因为Tensorflow之前的表,其实不是为了这个集群是定制的,只是以前的用户的行为交易表,这个交易表里面有上千个,而训练时,你会发现在这个3000个维度里面,只用拿里面的几十个纬度训练就好了,其它根本都跟这次训练目标没有关系,此时就需要写很多的逻辑。在你的python代码里面要去拿哪一类的数据,做这种ORM定制,然后关联数据,当有些数据缺失的时候,我还要把它去删掉。而这些工作对于AI工程师来说,在整个的Tensorflow模型里面,其实模型的代码是很经典的,就算是一些复杂的模型,它的模型的代码其实不会超过300行代码,用python写是很高效的,大概就两三百行代码。为什么说我们的一个机器学习的完整系统,大概会有几千万以上的一个代码,其实里面80%的代码是做数据访问的,所以我们在这个MegaLearning的一个设计的目标,我们希望能够打通底层数据的资产与上一层的AI和训练的系统之间的隔阂。以后再做一个AI的训练的时候,再也不用写几千万行代码了。其实只要写300行代码,数据预处理,可以获取图片、数据缓存、数据调度的脏活累活,应该是由这些系统去自动的完成。
MegaSearch是什么?
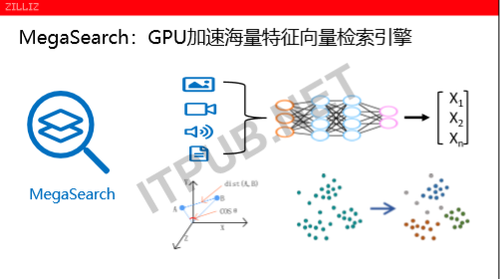
MegaSearch是用GPU来加速海量特征向量。特征向量,它其实是在AI里面对数据仓库,对数据处理提出了一个全新的数据类型,它的宽度从几百个到几千甚至几万,并且整个的深度学习里面,特征向量是一个至关重要一个枢纽般的存在。不管是我们下面讲的相似度,还是要找到跟它最相近的一个人脸、语音又或是文本等等,MegaSearch是就是完完全全为这种新兴的AI对特征向量新的需求量身定做的。

MegaSearch是能达到一个什么性能?
第一,MegaSearch能做到百亿条特征向量的秒级检索。第二,MegaSearch是用GPU加速,所以成本低。相对于说之前用CPU的方案来说,MegaSearch大概一台服务器可以替换掉以前10到20台服务器,所以在特征向量检索方面,MegaSearch能提供一个超高的性价比,同时还能将投入产出比提高十倍以上。第三,MegaSearch支持自动分区分表,具备高可用、多副本。第四,MegaSearch对各种的模型,不管是为了声音训练的,还是图片视频来训练都有一个良好的趋势,并且是多个学习的框架。在应用的场景里面,无论是不同的一些文件类型,还是人脸识别、机器翻译、文本查重等等。MegaSearch所有的系统,都支持私有部署、公有部署,在公有部署上面的一个Paas服务。

Mega业务领域
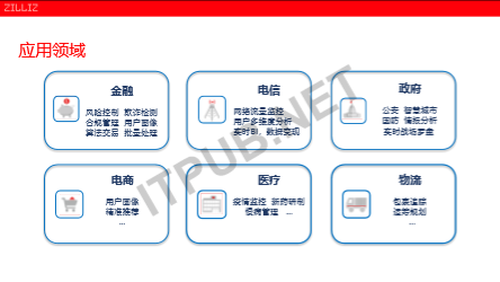
之前提到数据中台,它其实是一个跨越了各行各业数据的技术中台,Mega是为了AI对数据处理的一些要求去量身定做的一套端到端的数据处理流水线。那么它不管是在金融、电信、安防等各个领域都有一些广泛的应用场景。

最后举几个例子,比如说我们说实时风控,当实时风控时,有很多的数据源越多越好,但之后就会发现这个数据清洗ETL又变成一个很重要的工作。这个时候的话用我们的这个GPU的加速这个MegaETL解决方案,能够实现前面的速度清洗有几十倍的一个提升。同时在风控模型的训练这一块,很多现有的机构沉淀的数据都在现有的大数据仓库之上,那么我们直接用MegaLearning,可以加速训练,减少开发的难度。

比如说在智慧城市这个领域,智慧城市它的数据量是很大的,各种摄像头、各种传感器产生的各种数据,要进行一个同步的数据清洗,因为这个数据特别大,一个城市可能都是几亿条的规模。那么在这么大的一个数据里面,如果说有效的组织这些数据,可以加速这个数据的分析和处理。最后面在训练好的一些模型里面,不管是说车辆监控、人脸识别、自动的安防等等,我们用的那个MegaSearch,能够支持海量数据检索。
以上就是我的分享,谢谢大家的观看!