

大数据文摘出品
作者:曹培信、宁静
2017年年初,Brain vs AI的德州扑克人机大战在卡耐基梅隆大学(CMU)落幕,由4名人类职业玩家组成的人类大脑不敌人工智能程序Libratus。
获胜后人类还遭到了Libratus的无情嘲讽。

但是那时候Libratus还只是个只能在1V1局里称霸的超级玩家,要说人类最喜欢的6人局这样的“大场面”,当时的Libratus还没有拿到入场券。
而就在昨天,Facebook与CMU学Noam Brown、Tuomas Sandholm的最新研究成果——Pluribus,就在人类最常见的无限制德州扑克6人局里,战胜了人类顶尖选手。
论文被Sicence收录:
跟还是不跟?高手之间的对决
Darren Elias(1986年11月18日出生)是一名美国职业扑克玩家,曾获得四项世界扑克巡回赛冠军。
在他与Pluribus的对决过程中,Darren Elias从来没有遇到过如此不害怕的对手。
一个有经验的扑克玩家,当有两个J(一个面朝上,另一个藏起来,一手既不好也不坏)时,都会谨慎行事。但是Elias的对手看起来好像不知道该怎么做。即使当Elias决定虚张声势(bluff),下注时看起来很有信心,而他的对手似乎在鼓励他继续!好像一点都没有被吓到。
最后,Elias的虚张声势没有起作用,他输了。

Elias
正如埃利亚斯先生意识到的,Pluribus知道什么时候该虚张声势,也知道别人在虚张声势,还知道什么时候该改变自己的行为,这样其他玩家就无法确定自己的策略。32岁 Elias先生说: 它确实做了一些人类很难做到的事情。
赢的背后,只是8天的训练
之前AI和人玩游戏,要么是双人游戏,如国际象棋、跳棋等,要么就是双方之间的零和博弈(一方赢一方输),AI可以在游戏中找到Nash equilibrium strategy(纳什平衡)来保证自己不会输。
关于Nash equilibrium strategy(纳什平衡)属于博弈论范畴(注:纳什证明了,如果允许混合策略,那么任何一个博弈,只要参与者数量是有限的、参与者可以选择的纯策略也是有限的,那么这个博弈至少有一个纳什均衡)。
以经典的“石头剪刀布”游戏为例,AI可以在游戏中找到对方的弱点和常出的手势进行学习,以达到最终的胜利,而多人扑克意味着玩家数量的增多,在更复杂的游戏中,AI难以确定如何与纳什均衡相抗衡;采用固定策略不能很快观察到的对手的策略倾向,而且需要监控到多个玩家在游戏中策略的转变,这对于AI多人扑克博弈来说,是一项挑战。
鉴于多人游戏,如果学习多个玩家的出牌习惯等特征的训练数据集成本过大,这里Pluribus采用的策略是自己与自己博弈,不使用人类对手的数据作为模型训练的输入。在开始时,随机的选择玩法,通过不断的训练来提升自己的性能,这里采用的博弈策略是改良版本的迭代的蒙特卡洛CFR(MCCFR),通过自我博弈,左右手互博,自己制定了一个blueprint strategy(蓝图策略),最后对每个可能的状况进行概率分布统计,通过搜索决策树来决定下一步的行为,是叫牌还是出牌。
CFR是一种迭代的自我游戏算法,AI从完全随机游戏开始,然后通过学习击败早期版本的自己逐渐改进。
在算法的每次迭代中,MCCFR指定一个玩家作为其当前策略在迭代中更新的标记。在迭代开始时,MCCFR根据当前所有玩家的策略(最初是完全随机的)模拟一手扑克牌。一旦模拟完成,人工智能就会回顾每一个玩家做出的决定,然后通过选择其他可用的行动来预测这个决定的好坏程度。
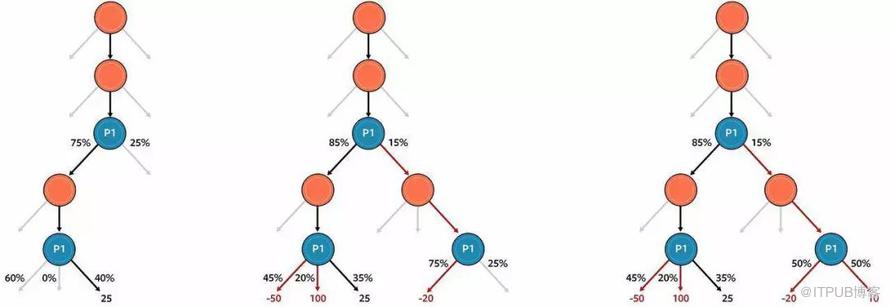
Pluribus玩家博弈树
在解决不完全信息博弈中搜索的问题,Pluribus跟踪每一手,根据其策略达到目前状况的可能性。不管Pluribus实际上握着的牌,它首先会计算如何使用可能的每一手,谨慎地平衡所有的策略,以保持对于对手的不可预测性。
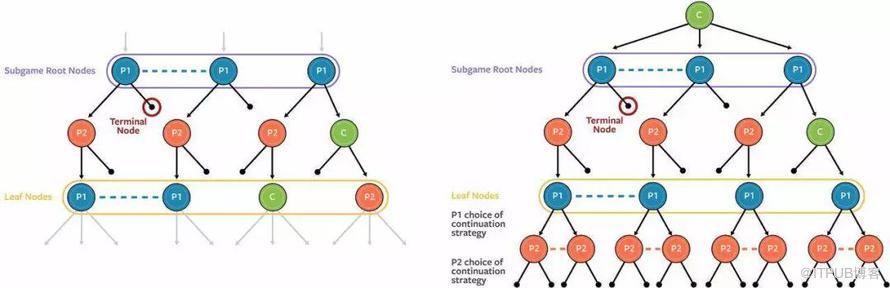
Pluribus 中的实时搜索
扑克以外的事
之前在1V1局中大胜人类的Libratus后来去五角大楼上班去了,国防部认为这种策略型人工智能或许可以帮助他们进行战略的制定。
负责 Pluribus 项目的 研究员Noam Brown说:“Pluribus的技术可以用于华尔街交易、拍卖、政治谈判和网络安全这些活动中,这些活动就像扑克一样,涉及隐藏信息,因为你并不总是知道真实世界的状态。”
尽管像谷歌这样的公司,有着“Don’t be evil”的信条,但是,不可避免的是这样能够理解人类策略的人工智能,还是会引发大众对于人工智能的某种恐惧,或者说,如果这样的人工智能被运用到军事决策中,将会带来多严重的后果?