
前言
关于AB test的重要性无需多言,数据、产品等从业人员几乎必知,好的数据科学家我想一定是知道理解业务比模型更为重要,而AB test就是伴随着业务增长的利器。
如果你心中的AB test几乎都没有用到中心极限定理、假设检验、z分布、t分布等知识,建议详细阅读本文。
本文内容目录:
A/B test是什么
A/B test工作原理
进行A/B test的目的是什么
A/B test流程(面试喜欢问)
A/B test简例(结合Python实现)
A/B test需要注意的点
A/B test中要知道的统计学知识
1、A/B test是什么
A / B测试(也称为分割测试或桶测试)是一种将网页或应用程序的两个版本相互比较以确定哪个版本的性能更好的方法。AB测试本质上是一个实验,其中页面的两个或多个变体随机显示给用户,统计分析确定哪个变体对于给定的转换目标(指标如CTR)效果更好。
2、A/B test工作原理
在A / B test中,你可以设置访问网页或应用程序屏幕并对其进行修改以创建同一页面的第二个版本。这个更改可以像单个标题或按钮一样简单,也可以是完整的页面重新设计。然后,一半的流量显示页面的原始版本(称为控件),另一半显示页面的修改版本(称为变体)。
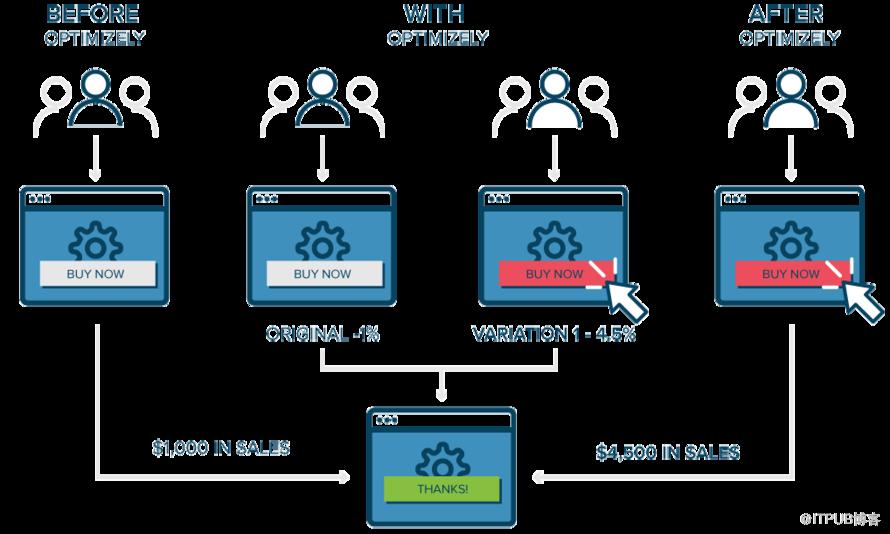
当用户访问页面时,如上图灰色按钮(控件)和箭头所指红色按钮(变体),利用埋点可以对用户点击行为数据采集,并通过统计引擎进行分析(进行A/B test)。然后,就可以确定这种更改(变体)对于给定的指标(这里是用户点击率CTR)产生正向影响,负向影响或无影响。
实验数据结果可能如下:
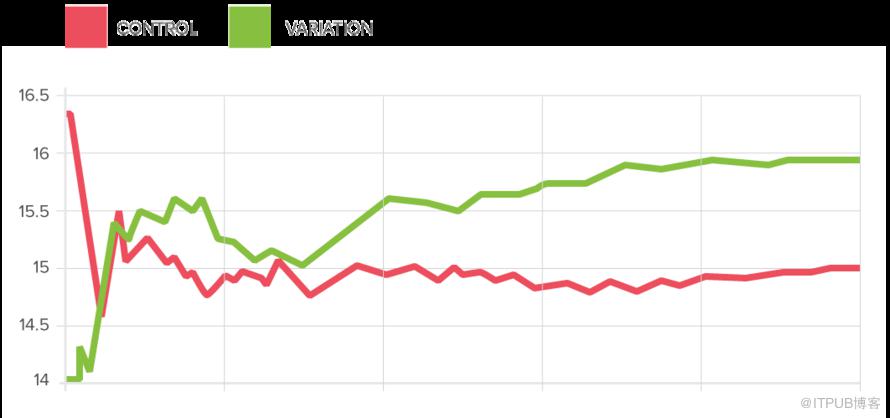
3、进行A/B test的目的是什么
A / B test可以让个人,团队和公司通过用户行为结果数据不断对其用户体验进行仔细更改。这允许他们构建假设,并更好地了解为什么修改的某些元素会影响用户行为。这些假设可能被证明是错误的,也就是说他们对特定目标的最佳体验的个人或团队想法利用A / B test证明对用户来说是行不通的,当然也可能证明是正确的。
所以说 A/B test不仅仅是解决一次分歧的对比,A/B test可以持续使用,以不断改善用户的体验,改善某一目标,如随着时间推移的转换率。
例如,B2B技术公司可能希望从活动登陆页面提高其销售线索质量和数量。为了实现这一目标,团队将尝试对标题,可视图像,表单字段,号召性用语和页面的整体布局进行A / B测试更改。
一次测试一个变化有助于他们确定哪些变化对访问者的行为产生何种影响,哪些变化没有影响访问者的行为。随着时间的推移,他们可以结合实验中多次正向变化的效果来展示变体相对于控件的可测量的改进。
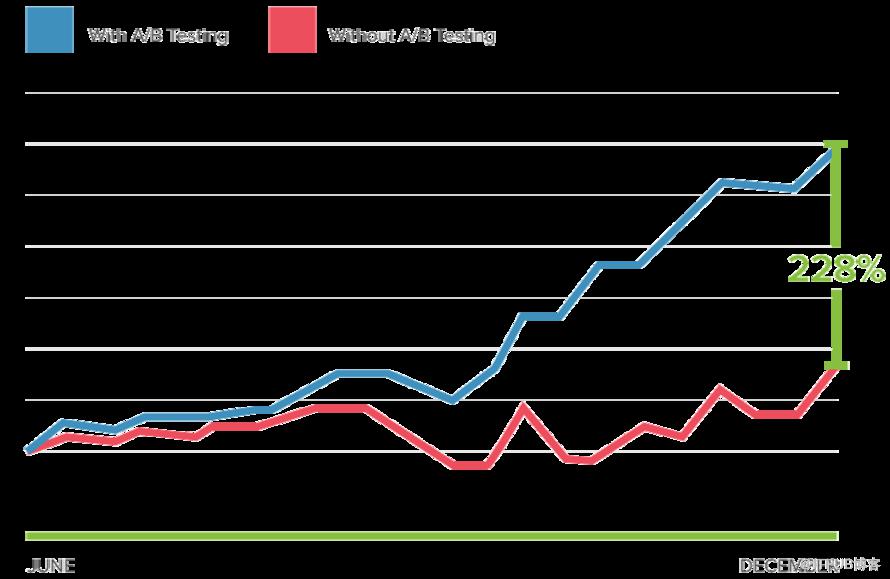
这样来说产品开发人员和设计人员可以使用A / B测试来演示新功能对用户体验变化的影响。只要目标明确定义并且有明确的假设,用户参与,产品体验等都可以通过A / B测试进行优化。
4、A/B test流程
①确定目标:目标是用于确定变体是否比原始版本更成功的指标。可以是点击按钮的点击率、链接到产品购买的打开率、电子邮件注册的注册率等等。
②创建变体:对网站原有版本的元素进行所需的更改。可能是更改按钮的颜色,交换页面上元素的顺序,隐藏导航元素或完全自定义的内容。
③生成假设:一旦确定了目标,就可以开始生成A / B测试想法和假设,以便统计分析它们是否会优于当前版本。
④收集数据:针对指定区域的假设收集相对应的数据用于A/B test分析。
⑤运行试验:此时,网站或应用的访问者将被随机分配控件或变体。测量,计算和比较他们与每种体验的相互作用,以确定每个用户体验的表现。
⑥分析结果:实验完成后,就可以分析结果了。A / B test分析将显示两个版本之间是否存在统计性显著差异。
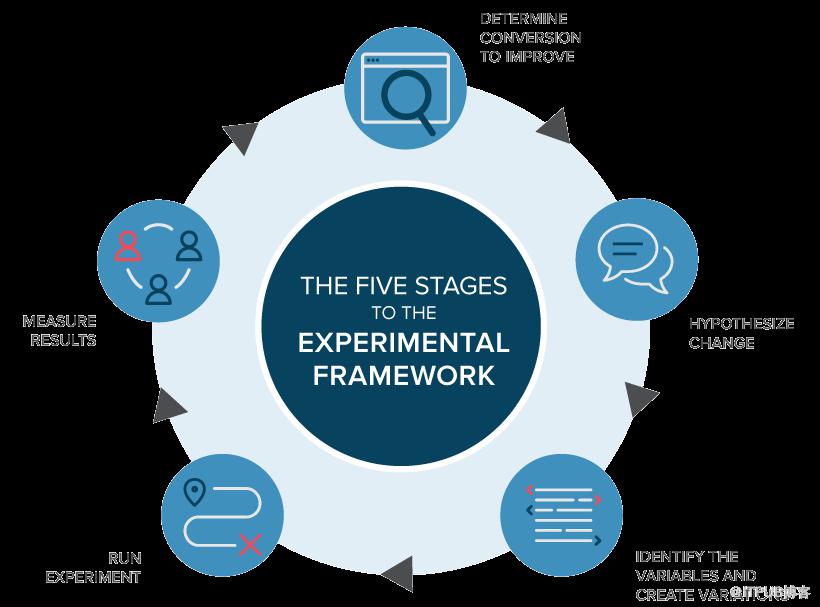
无论的实验结果如何,需要利用试验结果作为学习经验生成未来可以测试的新假设,并不断迭代优化应用元素或网站的用户体验。
5、A/B test简例(结合Python实现)
实例背景简述:
某司「猜你想看」业务接入了的新推荐算法,新推荐策略算法开发完成后,在全流量上线之前要评估新推荐策略的优劣,所用的评估方法是A/B test,具体做法是在全量中抽样出两份小流量,分别走新推荐策略分支和旧推荐策略分支,通过对比这两份流量下的指标(这里按用户点击衡量)的差异,可以评估出新策略的优劣,进而决定新策略是否全适合全流量。
实例A/B test步骤:
指标:CTR
变体:新的推荐策略
假设:新的推荐策略可以带来更多的用户点击。
收集数据:以下B组数据为我们想验证的新的策略结果数据,A组数据为旧的策略结果数据。均为伪造数据。
分析结果(Python):
利用 python 中的 scipy.stats.ttest_ind 做关于两组数据的双边 t 检验,结果比较简单。但是做大于或者小于的单边检测的时候需要做一些处理,才能得到正确的结果。
from scipy import stats
import numpy as np
import numpy as np
import seaborn as sns
A = np.array([ 1, 4, 2, 3, 5, 5, 5, 7, 8, 9,10,18])
B = np.array([ 1, 2, 5, 6, 8, 10, 13, 14, 17, 20,13,8])
print(‘策略A的均值是:’,np.mean(A))
print(‘策略B的均值是:’,np.mean(B))
Output:
策略A的均值是:6.416666666666667
策略B的均值是:9.75
stats.ttest_ind(B,A,equal_var= False)
output:
Ttest_indResult(statistic=1.556783470104261, pvalue=0.13462981561745652)
很明显,策略B的均值大于策略A的均值,但这就能说明策略B可以带来更多的业务转化吗?还是说仅仅是由于一些随机的因素造成的。
我们是想证明新开发的策略B效果更好,所以可以设置原假设和备择假设分别是:H0:A>=BH1:A < Bscipy.stats.ttest_ind(x,y)默认验证的是x.mean()-y.mean()这个假设。为了在结果中得到正数,计算如下:
stats.ttest_ind(B,A,equal_var= False)
output: Ttest_indResult(statistic=1.556783470104261, pvalue=0.13462981561745652)
根据 scipy.stats.ttest_ind(x, y) 文档的解释,这是双边检验的结果。为了得到单边检验的结果,需要将 计算出来的 pvalue 除于2 取单边的结果(这里取阈值为0.05)。
求得pvalue=0.13462981561745652,p/2 > alpha(0.05),所以不能够拒绝假设,暂时不能够认为策略B能带来多的用户点击。
6、A/B test需要注意的点
1、先验性:通过低代价,小流量的实验,在推广到全流量的用户。
2、并行性:不同版本、不同方案在验证时,要保重其他条件都一致。
3、分流科学性和数据科学性:分流科学是指对AB两组分配的数据要一致,数据科学性是指不能直接用均值转化率、均值点击率来进行AB test决策,而是要通过置信区间、假设检验、收敛程度来得出结论。
7、A/B test中要知道的统计学知识上述文章只是从应用的角度介绍来AB test的一些内容,当收集好数据之后做推断性统计分析你可能需要具备以下知识,这里限于篇幅不做介绍,自行查阅统计学书籍阅读,可参考《统计学》贾跃平,可汗学院统计学等书籍和视频。
1、点估计2、区间估计
3、中心极限定理(样本估计总体的核心,可以对比看一下大数定理)4、假设检验其中假设检验部分为核心,其他辅助更好的理解该部分内容,比如区间估计可以理解为正向的推断统计,假设检验可以理解为反证的推断统计,关于假设检验本身,你可能还需要知道小概率事件、t分布、z分布、卡方分布、p值、alpha错误、belta错误等内容。总结:本文内容目录前4部分参考翻译于:https://www.optimizely.com/optimization-glossary/ab-testing/
对其中部分内容做了修改,其中关于AB test流程步骤做了核心修改,目录后3部分为个人学习思考所得,希望对大家有所帮助。
本文转载自数据管道