
当我试图解决一个典型的物联网问题时, 集中式流式传输集线器或下一代实时数据处理工具的想法出现在了画面中。进入云的流式物联网数据源太多, 需要对其进行清理、处理、筛选和监控。在流数据上创建动态规则引擎是一个有趣的要求。该要求还要求典型的 elt 方案并将数据放入流中, 不同的业务应用程序可以在其中使用这些数据。如今, 大多数客户都在寻找通过卡夫卡流媒体的问题。通常情况下, 卡夫卡具有出色的吞吐量和非常低的延迟。客户端正在寻找流数据可用的流式集线器。
让我们先来看看建议的体系结构:
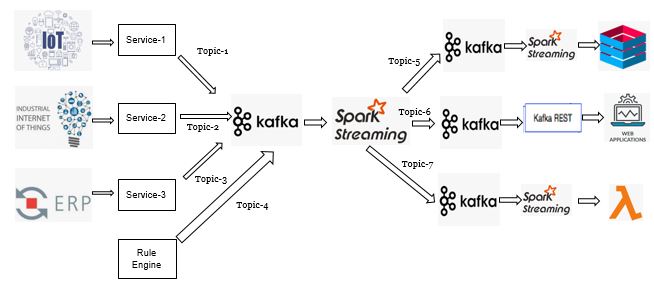
我正在尝试创建一个平台, 将暴露我的流数据统计、实时监控系统、接收到数据湖和高度使用的监控系统。在本文中, 我将解释如何使用 java 创建自定义卡夫卡制作者。我们将深入了解 spark 2.3 的连续流媒体属性, 以及自定义数据质量模块如何帮助识别格式错误的记录。
为了获得流媒体源, 我已经在本地计算机上安装了卡夫卡0.10.2.1。我还创建了一个简单的 java 生成器来推送不同主题中的消息。下面是一个示例:
public class DemoKafkaProducer {
public static void main(String[] args) {
//String directory=args[0];
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("request.required.acks", "1");
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer < String, String > producer = new KafkaProducer < String, String > (props);
try {
for (int i = 0; i <= 1000000; i++) {
String msg = < json string > ;
producer.send(new ProducerRecord < String, String > ("<topic name>", msg));
System.out.println("successfull");
Thread.sleep(2000);
}
producer.close();
} catch (Exception e) {
producer.close();
e.printStackTrace();
}
}
}在下一步中, 我使用结构化流读取这些卡夫卡队列。单个 spark 流作业可以使用来自多个主题的数据, 但 spark 流的创建者之一Tathagata das 建议最多四个。
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.10.2.1</version>
<scope>compile</scope>
<exclusions>
<exclusion>
<artifactId>jmxri</artifactId>
<groupId>com.sun.jmx</groupId>
</exclusion>
<exclusion>
<artifactId>jms</artifactId>
<groupId>javax.jms</groupId>
</exclusion>
<exclusion>
<artifactId>jmxtools</artifactId>
<groupId>com.sun.jdmk</groupId>
</exclusion>
</exclusions>
</dependency>我们在这里使用 spark 2.3, 直接从多个流阅读:
var df = spark格式 (“kafka”). option (“kafka.bootstrap.servers”、”localhost:9092”).option(“subscribe”、”& lt; 主题名称 & gt;”). load ()
读卡器数据集的结构
key (可选) 和 < cn> 是可以从用户端传递的字段。和 < c1. > 确定数据的独特来源。< c/> id 是唯一标识消息的字段。结构化流的关键是它需要有一个编写器流。从 spark 2.3 中, 我们得到了一个连续流的触发器, 使延迟约为10毫秒。对于我们的案例, 我们对收到的消息进行了一些基本的质量检查, 并检查了我们的动态规则引擎是否发送了一些要求。我们拆分数据服务和动态规则服务, 并将其加载到不同的主题。
root
|-- key: binary (nullable = true)
|-- value: binary (nullable = true)
|-- topic: string (nullable = true)
|-- partition: integer (nullable = true)
|-- offset: long (nullable = true)
|-- timestamp: timestamp (nullable = true)
|-- timestampType: integer (nullable = true)import org.apache.spark.sql.functions.udf
import org.apache.spark.sql.functions.{lit, max, row_number}
import spark.implicits._
import org.apache.spark.sql.Row
val recdValidator = udf(dataValidator _)
df=df.withColumn("value", recdValidator(df("value"),df("topic"),lit(rule_file_df)))
var data_df=df.filter(<topic name>)
var rule_df=df.filter(<topic name>)
This Rule can be configured from a metadata table.
like : Null check, Improper Junk characters, valid json records, missing tags in json etc.
val query =data_df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)").writeStream.format("kafka").trigger(Trigger.Continuous("10 seconds")).option("kafka.bootstrap.servers", "localhost:9092").option("topic", "<data part>").start()
val query_rule =rule_df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)").writeStream.format("kafka").trigger(Trigger.Continuous("10 seconds")).option("kafka.bootstrap.servers", "localhost:9092").option("topic", "<Rule part>").start()
query.start()
query_rule.start()Trigger.Continuous("10 seconds")表示我们每10秒检查一次。
这将我们接收的数据推送到基于主题检查的集中式流。下一部分是将数据输入到数据湖中。我们将使用 nosql 实时 (近实时) 分析数据。
下一个基于动态规则的检查可以通过结构化流实现, 也可以通过异步流和微批处理模型来实现。结构化流的限制 (直到 spark 2.4) 是它不能执行完全外部连接。它只适用于基于水印条件的内部、左侧和右侧外部联接。我们需要主题数据内部联合主题规则来执行这些操作。简而言之, 动态规则应附带与接收数据的名称相同的主题名称。这将仅限于某些操作。但是, 对于异步流, 我们可以执行所有可能的批处理操作, 并将其写入 nosql 或时间序列数据库, 如 fex。
如果我们可以创建30-60 的微批处理, 并从具有模板格式的 ui 动态传递规则, 我们就可以从 nosql 实时报告。动态规则引擎演示将发布在本文的下一个版本中。
希望这有助于人们以更互动的方式使用 spark 流。
谢谢, 保持火花!