
矢量嵌入是人工智能中的强大工具。它们是向量空间中单词或短语的数学(数字)表示。这些向量表示通常由嵌入模型处理,捕获单词之间的语义关系,允许算法理解单词的上下文和含义文本。通过分析单词出现的上下文,嵌入可以捕获其含义以及与其他单词的语义关系。
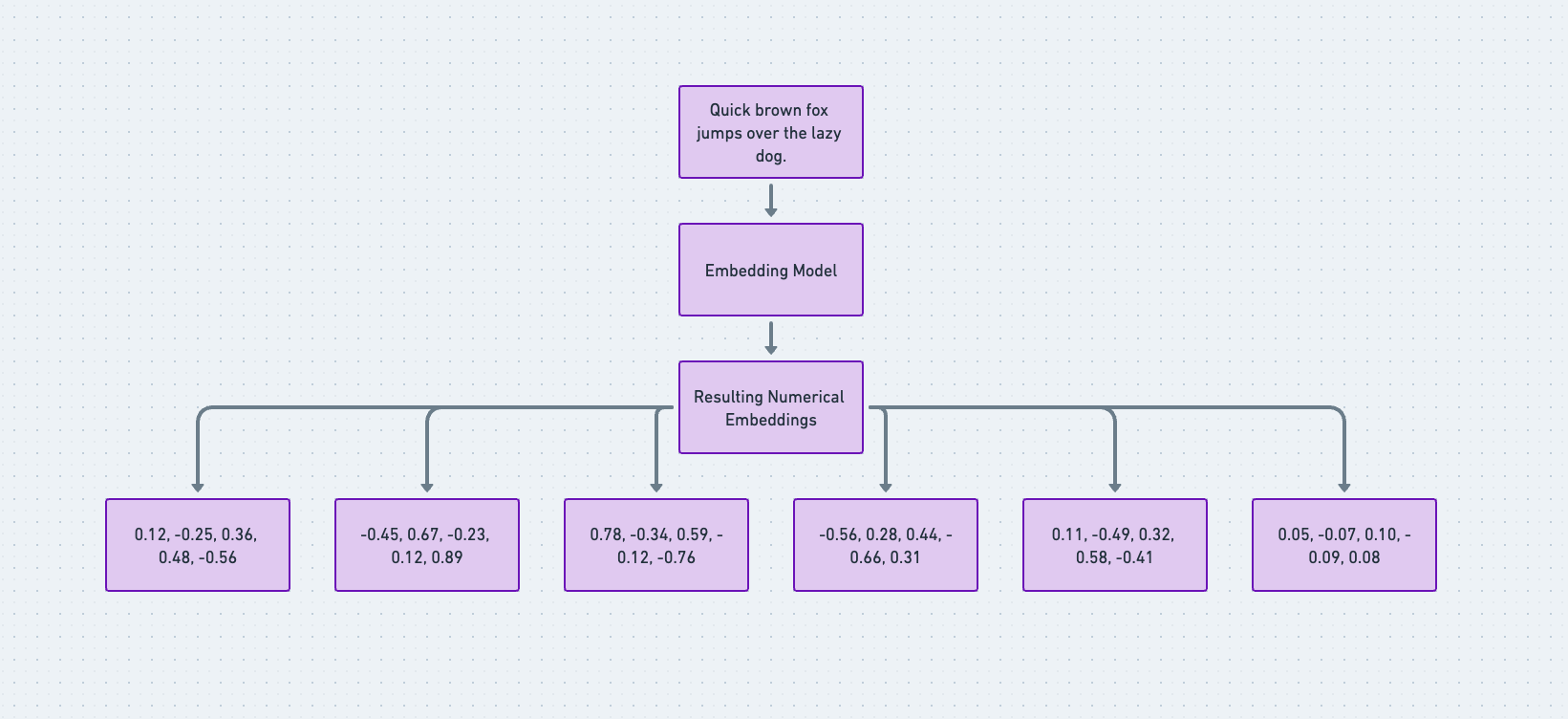
嵌入和向量存储/数据库在现代应用程序中的作用
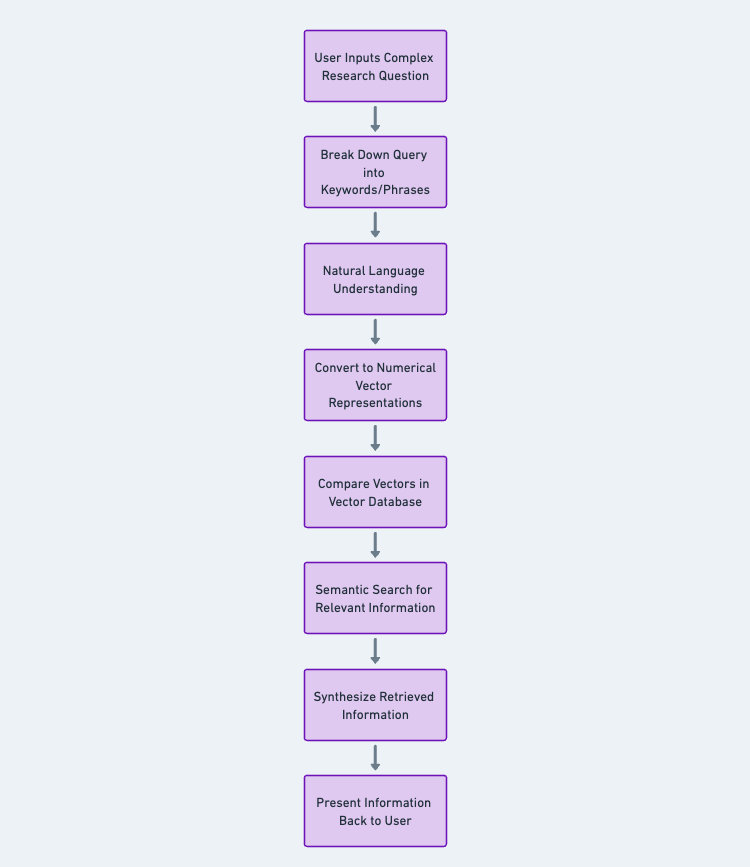
嵌入对于推荐系统、搜索引擎等现代应用程序至关重要自然语言处理除了嵌入之外,矢量数据库在释放其力量方面发挥着至关重要的作用。 Pinecone 和 ChromaDB 等矢量数据库提供可扩展且高效的矢量嵌入存储和检索。它们允许在广泛的嵌入集合中进行快速相似性搜索,从而能够快速准确地检索相关信息。您可以找到向量列表您可以在应用程序中使用存储和数据库。
让我们以人工智能驱动的聊天应用程序为例来了解这两件事是如何工作的。 开发人员可以通过将聊天消息存储为矢量数据库中的矢量嵌入并为其建立索引,根据用户查询快速检索相关聊天响应。这些向量嵌入捕获对话的上下文信息,从而在会话中实现连贯一致的响应。凭借其有状态交互和实时响应能力,Pinecone 可以在此场景中有效处理会话上下文并维护会话状态。
在您的项目中实现嵌入
作为产品或软件工程师,您可以通过多种方式将嵌入合并到您的项目中。您可以使用预先训练的嵌入模型,例如 ColBERT、Word2Vec 或 GloVe,这些模型已经过大型文本数据语料库的训练,并且可以随时使用。此外,还有一些可用的库和框架可以让您更轻松地在项目中实现和利用嵌入。以下是这些内容的列表open-源嵌入模型。如果您是 Python 开发者,则可以在拥抱脸。
让我们使用 最新 openAI 的 text-embedding-3-small 和 text-embedding-3-large 嵌入模型。
第 1 步:创建一个新文件夹并运行以下命令来设置节点项目。
npm init -y第 2 步:安装 openai 软件包
npm install --save openai第 3 步:创建一个 index.js 文件并将以下内容复制到其中。
const { OpenAI} = require("openai");
const openai = 新 OpenAI({
api 密钥:“”
});
异步函数 main() {
const 嵌入 = 等待 openai.embeddings.create({
模型:“文本嵌入-3-小”,
输入:“敏捷的棕色狐狸跳过了懒狗。”,
编码格式:“浮动”,
});
console.log(嵌入);
}
main();注意这仅用于测试。确保将“openai 密钥:process.env.OPENAI_API_KEY”保存在生产环境的 .env 中。
第 4 步:运行 `node index.js`,您将看到嵌入数组和使用的令牌数量。
第 5 步:要访问从提示文本生成的向量嵌入,我们将 `console.log(embedding);` 更改为 `console.log(embedding.data[0].embedding) ,`,您应该会看到一大堆嵌入,如下所示:

使用嵌入的最佳实践
使用嵌入时,产品和软件工程师可以遵循几种最佳实践来最大限度地提高其效率:
1.选择正确的嵌入模型:有各种预训练的嵌入模型可供使用,每种模型都有其优点和缺点。产品和软件工程师需要仔细选择最适合其特定应用、预算和数据的嵌入模型。
2.有效地预处理您的数据:彻底清理和预处理您的文本数据,以提高嵌入的质量。这涉及标记化、停用词删除和管理词汇表外的单词等。 如果您使用框架来开发基于 AI 的应用程序(例如 Langchain),它附带一套文档加载器,可帮助您干净地解析和预处理数据来源。
3.不断更新和评估您的嵌入。定期使用新数据重新训练它们,以保持它们的最新性和相关性。此外,持续评估下游任务中嵌入的性能,以确保它们有效地促进应用程序的目标。例如,您可以在大规模文本嵌入基准 (MTEB) 排行榜。
结论
将向量嵌入纳入工程解决方案可以为产品和软件工程师带来显着的好处。通过利用矢量嵌入及其相关的人工智能。设置、产品和软件工程师可以构建更复杂、更先进的人工智能应用程序,以提供增强的用户体验。