

这篇文章是我上一篇文章的延续。在这里,我们将讨论另一个数据类型,数据帧。
数据帧将成为开发人员在使用熊猫时使用的主要工具。
您可能还喜欢:
了解 Numpy.
先决条件
Python 的熊猫模块应安装在系统中,如果尚未安装,则可以使用以下功能进行安装:
pip install pandas (如果您通过直接https://www.python.org/downloads/来安装 python)
或
conda install pandas (如果您有蛇的 Anaconda 分布)
数据帧和熊猫
DataFrame是熊猫的主力,直接受到R编程语言的启发。我们可以将 DataFrame 视为一组序列对象,这些对象组合在一起以共享相同的索引。让我们用熊猫来探讨这个话题。
import pandas as pd
import numpy as np
from numpy.random import randn
np.random.seed(101)为了生成一些随机数,我们在这里使用种子。
现在,让我们创建一个数据帧:
df = pd.Dataframe如果您使用的是 Jupyter 笔记本,请按 移位 +tab df = pd.Dataframe 后,您将看到:

签出此 DataFrame 的文档字符串和初始签名。我们有一个数据参数,索引参数(就像系列),但随后我们有这些额外的列参数。
让我们继续用一些随机数据创建它,我们将了解 DataFrame 的实际外观。对于数据,我们使用 randn(5,4) 的为索引,我们使用字符列表,对于列,我们使用另一个字符列表。
df = pd.DataFrame(randn(5,4),['A','B','C','D','E'],['W','X','Y','Z']) 
因此,基本上,我们这里有一个列 W、Y、Y 和 Z 的列表以及相应的行 A、B、C、D 和 E。这些列中的每一个实际上是一个熊猫系列,如 W 或 X 或 Y 或 Z,它们都共享一个公共索引
选择列:
df['W']

您可以使用以下功能检查类型:
type(df['W']) 这将给予熊猫.core.系列因此。
您还可以检查:
type(df) 这将给熊猫.core.frame.DataFrame。
如果要选择多个列,请使用:
df[['W','Z']] 
创建新列
df['new'] = df['W'] + df['Y'] 
删除列
要删除列,只需执行下列操作:
df.drop('new',axis=1) 
在这里,您可以使用移位 + 选项卡来检查轴实际引用的内容。轴 = 0,默认情况下用于行,而轴= 1是指列。因此,这里我们使用轴#1,因为我们想要删除一列。
注意:”新”列仍然存在;您必须使用 inplace 参数来保留此更改。熊猫这样做,所以用户不会意外地丢失信息。因此,请使用 inplace = True 。

我们还可以使用 df.drop('E',axis=0) 删除一行。自己试试吧。
快速问题:
为什么行为 0,为什么列为 1?
引用实际上又回到了numpy。DataFrame 本质上是 numpy 数组之上的索引标记shape() 产生元组 (5, 4)。对于二维矩阵,0 索引是行数(A、B、C、D、E),然后索引 1 是列(W、X、Y、Z)。这就是为什么行被称为 0 轴,列被称为 1 轴,因为它直接取自形状,就像在 numpy 数组中一样。
选择行
有两种方法可以在 DataFrame 中选择行,您必须为此调用方法。
根据标签选择:
df.loc['A']
或
根据位置选择:
df.iloc[2]

注意:不仅是所有列系列,而且行也是序列。
选择行和列的子集:
为此,您可以使用:
df.loc[['A','B'],['W','Y']] 要选择特定值,请使用:
df.loc['B','Y']

条件选择
熊猫的一个重要特征是能够使用括号符号执行条件选择。这将非常类似于 numpy。
让我们使用比较运算符:
df > 0
结果是具有布尔值的数据帧。如果该位置的 DataFrame 值大于零,则返回 true;如果该位置的值不大于零,则返回 true。请参阅以下内容:

df[df>0]
正如您所看到的,只要值为负值,不符合条件, NaN 则返回。
现在,重要的是, NaN 我们将只返回条件为 true 的 DataFrame 子集的行或列,而不是返回 。

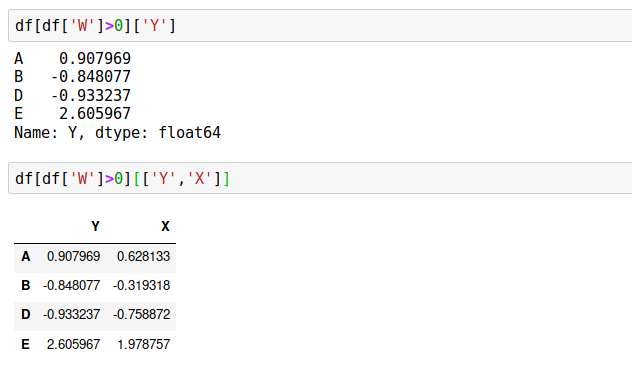
假设我们想要在数据帧中获取列值为
W>0
,我们要提取”Y”列请参阅以下内容:
使用多个条件:
对于多个条件,我们可以使用 |或&请记住,我们不能在这里使用 python 和/或。
df[(df['W']>0) & (df['Y'] > 1)] 
重置索引
为了将索引重置回默认值为 1234….n,我们使用方法reset_index()。我们将获取索引,重置为列,并将实际索引转换为数字。但是,如果不使用”原地”*True,它将不会保留更改。熊猫在许多区域使用此位置参数,只需移位+tab(如果使用 Jupyter 笔记本),您将看到它。
df.reset_index() 
设置新索引
对于设置新索引,首先,我们必须创建一个新索引。我们使用的是字符串的split()方法,这只是拆分空格的常用方法。这是创建列表的快速方法;)
newind = 'WB MP KA TN UP'.split() 现在,将此列表作为数据帧的列。
df['States'] = newind
df
如果我们想要使用此状态列作为索引,则应使用:

注意:除非我们保留索引的此信息,否则它将覆盖旧索引,并且我们实际上无法将此信息保留为新列 – 与允许我们拥有该新列的重置索引不同。
因此,这是设置索引与重置索引。:)
在这里,地方_True也起着重要的作用。
我希望,到目前为止,您喜欢阅读有关 DataFrame 的介绍。在即将发布的有关 DataFrame 的文章中,还有更多内容需要介绍。
快乐学习:)