
2023 年 9 月,人工智能性能权威基准 MLPerf 推出了存储基准。该基准测试可在AI模型训练场景中对存储系统进行大规模性能测试,无需GPU即可模拟机器学习I/O工作负载。
MLPerf支持两种类型的模型训练:BERT(自然语言模型)和UNet3D(3D医学图像分割)。虽然它不支持像 GPT 和 LLaMA 这样的大型语言模型(LLM),但 BERT 和 LLM 共享多层 Transformer 结构。 LLM 用户仍然可以从 BERT 训练结果中获得有价值的见解。
DataDirect Networks (DDN)、Nutanix、Weka 和阿贡国家实验室 (ANL) 等领先的高性能存储供应商发布了 MLPerf 测试结果作为行业参考。我们还使用高性能分布式文件系统JuiceFS企业版进行了测试,让用户了解其在模型训练方面的表现。
测试中最直观的指标是 GPU 利用率。 90%以上为及格,说明存储系统能够满足训练任务的性能要求。在 UNet3D 500 卡规模的测试中,JuiceFS 保持 GPU 利用率超过 97%;千卡规模的BERT,GPU利用率保持在98%以上。
测试准备
JuiceFS 企业版是基于对象存储的并行文件系统,与社区版相比,提供更强大的元数据引擎和缓存管理功能< /a>.下图展示了其架构: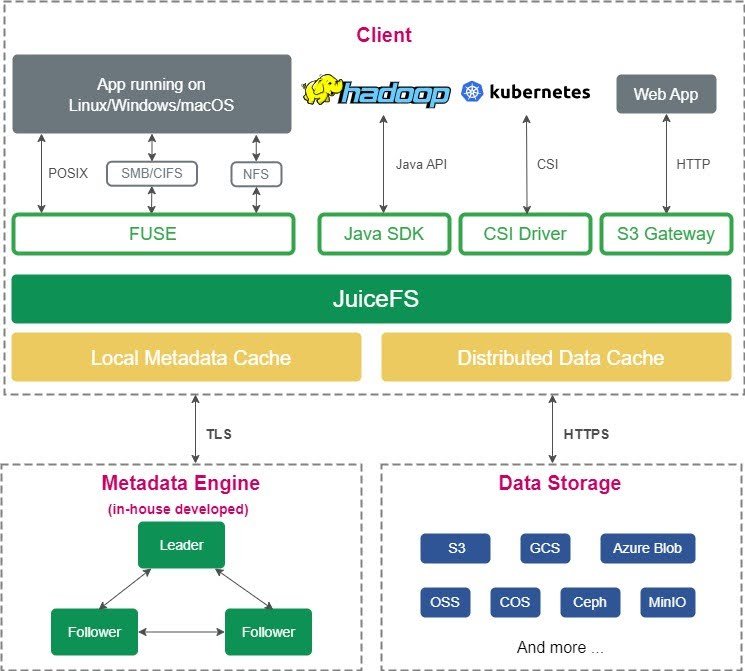
<图>
我们在云端部署了 JuiceFS 企业版文件系统。我们使用对象存储作为数据持久层,具有三个节点的元数据集群和多个节点的分布式缓存集群。硬件规格包括:
- 元数据节点:8vCPU | 64GiB
- 对象存储:带宽限制 300 Gb/s
- 客户端节点:64vCPU | 256 GiB |本地SSD 2*1, 600 GiB |网络带宽 25 Gbps(以太网)
设置文件系统后,我们使用 mlperf 脚本生成后续模拟训练所需的数据集,并将批量大小和步骤设置为默认值。目前仅支持 NVIDIA v100 GPU 模拟,本文后面提到的所有 GPU 均为模拟 v100。
BERT模型
MLPerf 为 BERT 模型生成数据集时,每个数据集文件包含 313,532 个样本,每个样本大小为 2.5 KB。在训练期间,每个模拟 v100 GPU 每秒可以处理 50 个样本。这意味着每个 GPU 的 I/O 吞吐量要求为 125 KB/s。大多数存储系统都可以轻松满足模型训练需求,其中JuiceFS可以支持千卡规模的训练需求。
下图中,我们收集了 MLPerf 的公开结果,包括来自 ANL、DDN 和 Weka 的结果,并添加了 JuiceFS 的测试结果。
<图>
从图中我们可以看出:
- JuiceFS 在 1,000 个 GPU 规模下保持 GPU 利用率高于 98%。
- ANL 的成绩非常出色。考虑到其高带宽、低延迟的 Slingshot 网络条件,取得这样的结果是意料之中的。
UNet3D模型
UNet3D 模型训练需要比 BERT 模型更高的带宽。
无缓存测试
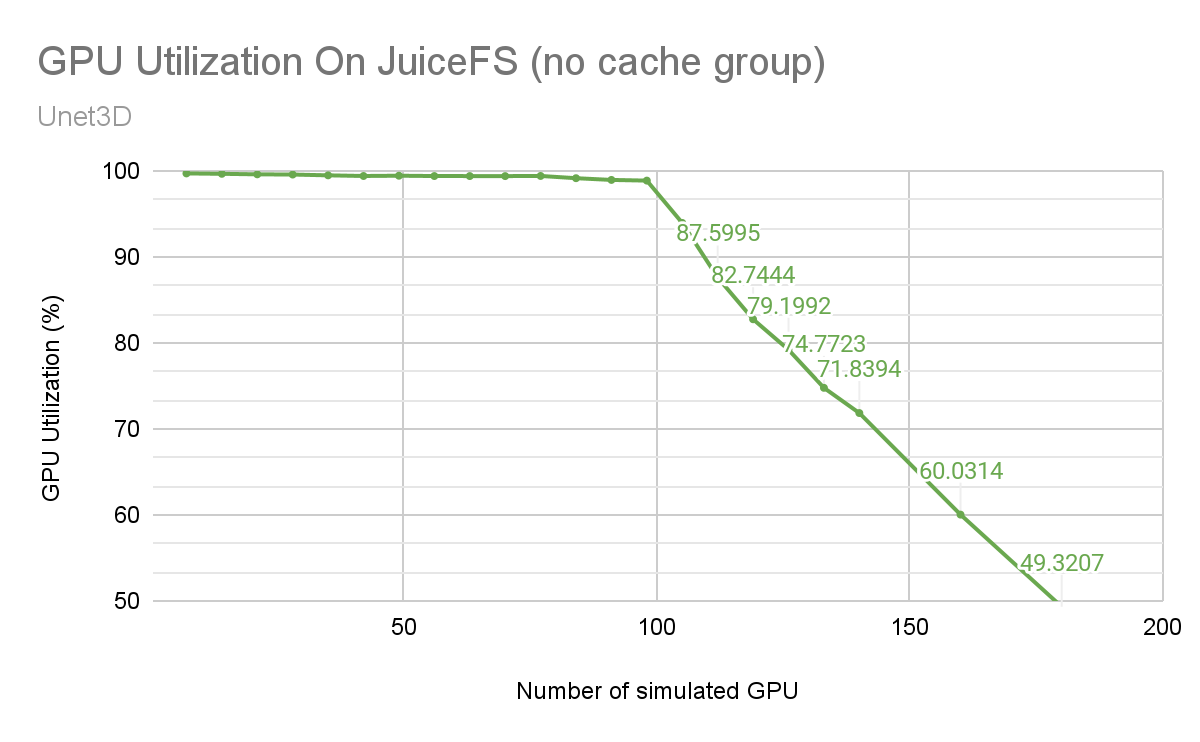
最初,我们在没有任何缓存的情况下测试了 UNet3D 模型训练,包括分布式缓存和本地缓存。在此设置中,JuiceFS 客户端直接从对象存储读取数据。
如下所示,随着节点数量的增加,GPU 利用率(以绿线表示)缓慢下降。在 98 个卡处,出现了一个明显的拐点,随后随着节点的增加,GPU 利用率急剧下降。
<图>
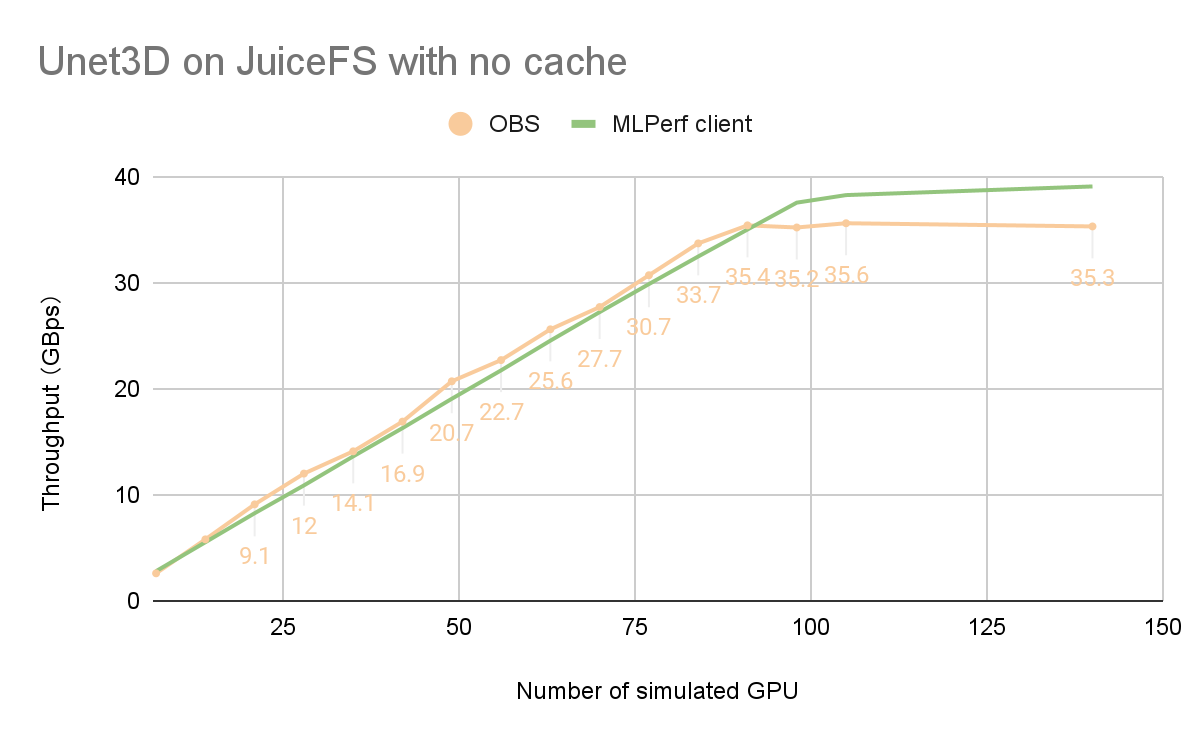
下图是基于OBS监控数据和MLPerf结果:
<图>
我们可以看到,超过98卡和更大规模的训练,OBS带宽并没有增加,成为性能瓶颈。
因此,在没有缓存的情况下,OBS 300 Gb/s 的带宽已经在 98 个卡上满载进行同时训练。根据MLPerf的90%直通标准,最多可支持UNet3D模型同时训练110张卡。
在对大型数据集进行多服务器多卡训练时,由于空间限制,独立缓存只能缓存一小部分数据集。另外,由于训练过程中数据访问的随机性,导致缓存命中率较低。因此,在这种情况下,独立缓存对整体 I/O 性能的贡献是有限的。如上图中绿线所示,独立的内核缓存可以提高读取带宽;虽然内核缓存空间达到了200GB,但提升效果有限。因此,我们没有针对独立缓存进行测试。
启用分布式缓存进行测试
JuiceFS 的分布式缓存架构
与本地缓存相比,分布式缓存可以提供更大的缓存容量,支持更大的训练集和更高的缓存命中率。这样可以增强整个JuiceFS集群的读取带宽。
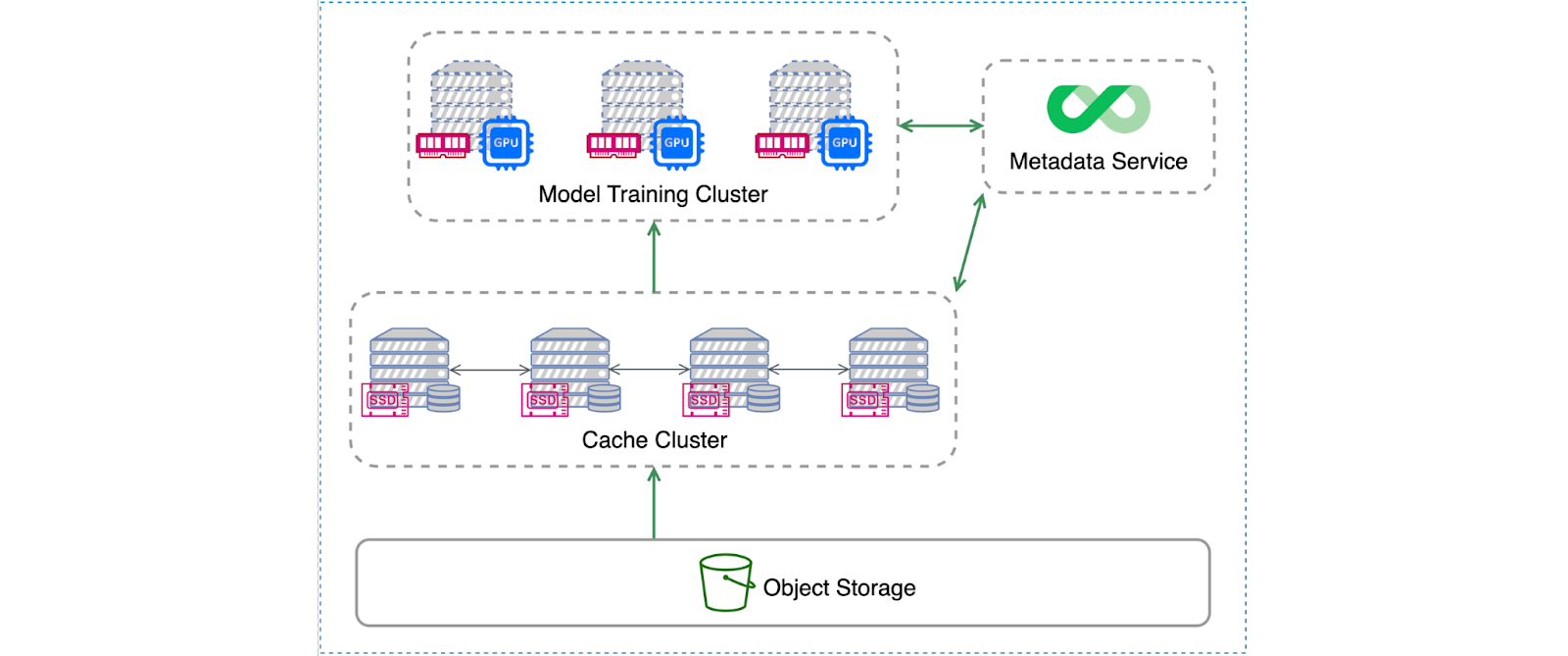
下图展示了JuiceFS的分布式缓存架构:
<图>
这种架构允许机器学习训练集群和缓存集群成为通过高速网络连接的两组独立的机器。两个集群都挂载 JuiceFS 客户端。训练任务通过本地挂载点的 JuiceFS 访问数据。当本地挂载点需要数据时,首先向缓存集群请求数据。如果缓存集群没有所需的数据,系统会从对象存储中检索数据并将其更新到缓存中。如果训练集群中的GPU节点配备了足够的SSD存储,则可以直接用作JuiceFS缓存盘,形成一个缓存集群,而不需要单独的缓存集群。
此配置有效地合并了训练集群和缓存集群的功能。在本次测试中,我们采用了这种混合部署方式。
分布式缓存及其对 GPU 利用率的影响
之前的测试表明,在没有缓存的情况下,110 张卡时 GPU 利用率低于 90%。为了直观地展示分布式缓存对性能的影响,我们对 JuiceFS 进行了进一步的测试。我们选择了180个GPU的集群进行测试,以评估缓存命中率和GPU利用率之间的关系。
下图中,横轴表示缓存空间与数据集大小的比例,纵轴表示缓存命中率和GPU利用率。
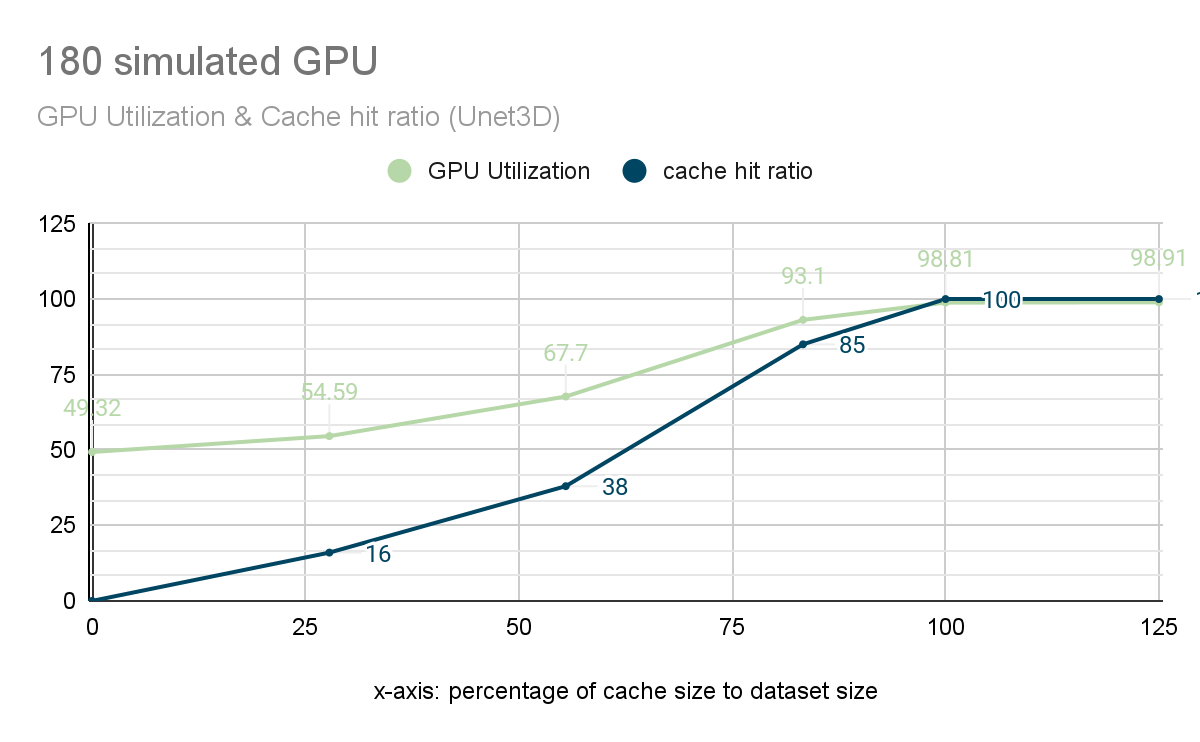 GPU 利用率和缓存命中率
GPU 利用率和缓存命中率
从图中可以看出:
- 没有缓存时,GPU 利用率仅为 49%。
- 随着缓存空间比例的增加,缓存命中率(蓝线)逐渐上升,从而带动 GPU 利用率(绿线)上升。
- 当缓存命中率达到85%时,GPU利用率达到93.1%,满足180张卡的训练需求。
- 当缓存命中率达到 100% 时,GPU 利用率达到峰值 98.8%,几乎满载。
为了验证JuiceFS缓存系统的可扩展性,我们根据数据集的大小调整缓存集群的容量,保证缓存命中率达到100%。这样,训练所需的所有数据都可以直接从缓存中读取,而不需要从速度较慢的对象存储中读取。在此配置中,我们测试了多达约 500 个卡片规模的训练任务。随着测试规模的增大,GPU利用率的变化如下图所示:
<图>
DDN和Weka公布的数据中最大的模拟GPU总数不足200个。
ANL 在 512 卡规模上保持没有明显下降,GPU 利用率达到 99.5%。 ANL的读/写带宽为650 GBps,理论上支持UNet3D多达1,500张卡的训练。其出色的性能表现与充足的硬件配置密切相关。有关详细信息,请参阅 ANL 的文章。
JuiceFS 的 GPU 利用率随着集群规模变大而缓慢线性下降,在 500 卡规模下保持超过 97% 的利用率。 JuiceFS的性能瓶颈主要来自于缓存节点的网络带宽。由于缓存节点型号和网络带宽有限,本次测试最大规模为483卡。在此规模下,JuiceFS集群的总带宽为1.7Tb,而ANL集群的带宽为5.2Tb。
结论
我们的测试结果包括以下亮点:
- 在 BERT 测试中,JuiceFS 在 1,000 个 GPU 规模的训练中保持了 98% 以上的 GPU 利用率。
- 在 UNet3D 测试中,随着集群规模的增加,JuiceFS 在接近 500 个 GPU 的训练中保持了 97% 以上的 GPU 利用率。如果云服务提供商能够提供更高的网络带宽或者更多的服务器,这个规模还可以进一步扩大。
- 分布式缓存的优势在于其强大的可扩展性。它可以在更多的节点上使用SSD存储来聚合更大的缓存空间,以提高整个存储系统的读取带宽。当然,这也引入了一些CPU开销,但在AI训练场景中,利用空闲的CPU资源来提高系统带宽是有价值的,甚至是必要的。
- 在云端进行机器学习训练时,高性能 GPU 模型通常会配备高性能 SSD 和高带宽网卡,同时也可以作为分布式缓存节点。因此,与专用的高性能存储产品相比,使用 JuiceFS 更具成本效益且更易于扩展。
大规模AI训练场景通常需要专用的高性能存储或基于全闪存架构和内核模式的并行文件系统来满足性能要求。但随着计算负载的增加和集群的增长,全闪存的高成本和内核客户端的运维复杂性将成为用户面临的重大挑战。 JuiceFS作为完全用户态的云原生分布式文件系统,采用分布式缓存,大大提高了系统的I/O吞吐量。它使用廉价的对象存储来存储数据。这更适合大规模AI应用的整体需求。
关于 MLPerf
MLPerf 是一个基准套件,用于评估本地和云平台上的机器学习训练和推理性能。它为软件框架、硬件平台、机器学习云平台提供了独立、客观的性能评估标准。该套件包括测量机器学习模型训练所需时间以达到目标准确性的测试以及神经网络对新数据执行推理任务的速度。该套件由 30 多个与 AI 相关的组织创建。有关详细信息,请参阅 MLPerf:行业标准基准套件机器学习性能。
