

大数据文摘出品编译:Luciana、小七、宁静“剪刀石头布”是我们小时候经常玩的游戏,日常生活中做一些纠结的决策,有时候也常常使用这种规则得出最后的选择,我们人眼能很轻松地认知这些手势,“石头”呈握拳状,“布”掌心摊开,“剪刀”食指和中指分叉,如何让机器识别这些手势呢?在没有使用TensorFlow.js库之前,如果让我写一个算法,要求可以根据手势的图像来确定它代表剪刀、石头、布中的哪一个,这是计算机视觉领域(CV)典型的图像分类任务,我可能需要经过谨慎思考,并花费很长的时间来完成算法编写,其中包括数据图像的采集、模型的训练、参数的调整,最终结果可能得经过分类模型(如:VGG、ResNet、ShuffleNet等)的卷积层、全连接层,最终以概率的方式呈现,预期效果是达到了,在时间的花销上有点大。现在,给我10分钟,还你一个训练好的识别模型!在浏览器上基于TensorFlow.js可以很快完成这项需求。

摄像头将通过快照功能将拍摄图像转换为64×64图像并显示辨别结果。
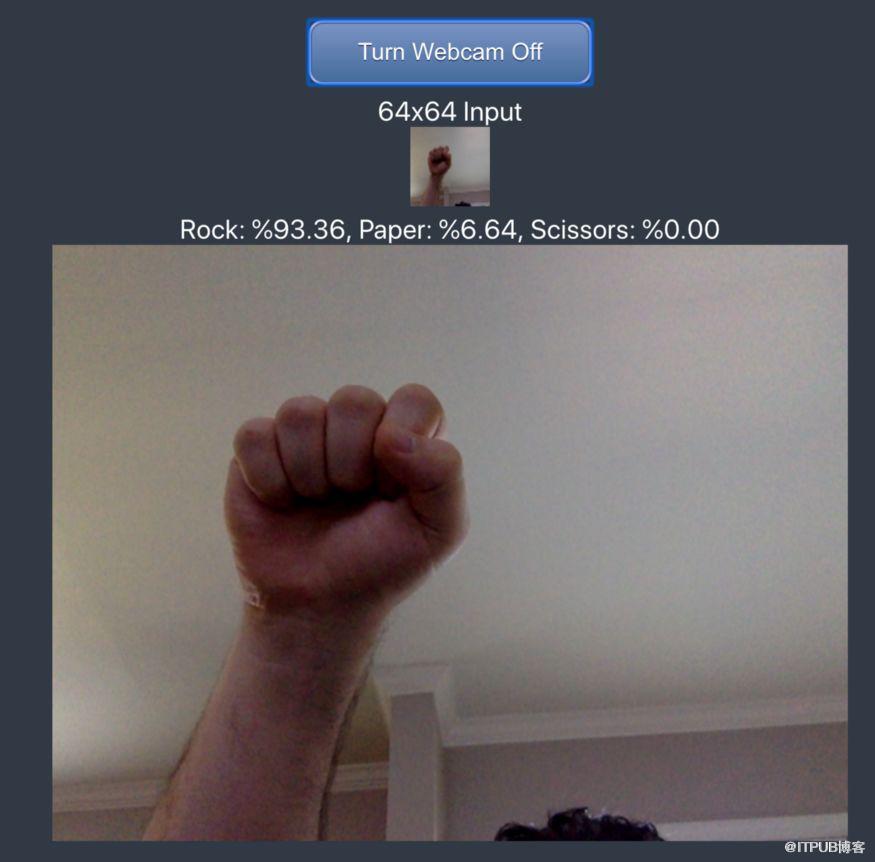
在线演示链接:
https://rps-tfjs.netlify.com/完整代码地址:https://github.com/GantMan/rps_tfjs_demo基于TensorFlow.js实现的算法与正常的机器学习算法有什么不同?又在哪些方面节省了时间?下面教学时间正式开始。
利用好这个网站
首先安利一个网站,可以节省很多时间,减轻一部分工作量。这个网站可以在自己电脑上使用浏览器访问,它的运行速度取决于你所使用的计算机性能,与此同时,由于它使用了TensorFlow.js库,这使得所有繁重的工作都可以在浏览器中用JavaScript来实现。网站链接:https://rps-tfjs.netlify.com/

针对数据的操作
机器学习需要数据及用于训练数据的模型架构, 经过一段时间的训练后,模型可以智能识别出新的代表剪刀、石头、布手势的图像,基于TensorFlow.js库的方法也需要数据做训练,有了网站这个“利器”,数据从哪来呢?
数据从哪儿来?
这里我们也需要一些代表剪刀、石头、布手势的图像作为训练数据,Laurence Moroney提供了大量的优秀数据,我们只需要选择其中一部分数据,不需要所有数据,使用它我们可以训练一个基本模型。
数据集链接地址:http://www.laurencemoroney.com/rock-paper-scissors-dataset/
破解浏览器加载图像的难题
在正常的机器学习工作流程中,我们只需要访问文件可以实现提供数据的流程,也可以使用简单的glob模块抓取文件夹,相比之下,如果在浏览器中加载一个10MB大小的手势图像就会很困难。幸好我们可以使用经典技巧将一组图像传输到浏览器,那就是使用精灵表单(spritesheet):将一组图像粘合成一个图像,此时,图像中每个像素都变成1像素高清图像,我们将它们堆叠创建一个保存所有图像的10MB大小的大图像。

将2D图像放大为1D高清图像的视觉化效果Python源代码保存在对应项目的spritemaker(精灵编辑器)文件夹中,因此,如果数据集不同而操作类似,则可以创建各自的精灵表单。此时所有内容都合并为一个图像,我们可以将图像切片进行训练和验证。在编写完自己的精灵表单生成器并在“剪刀石头布”数据集上运行,实现过程展示如下:

可以看到生成结果十分符合预期,经过转换后的采集结果如下:

图像收缩为64*64大小每个,共有2520个图象,即成像为4096*2520像素
点击按钮-获取浏览器训练样本
图像数据集的处理到此已经完成,按下网站上的按钮,信息将填充到TFVIS即TensorFlow ,它基本上是一个小的幻灯片菜单,可以帮助我们显示训练信息。

历时一秒钟加载生成的大图像并解析通过使用TensorFlow Visor,我们可以随机展示来自数据集的42个手势图像,并将其作为测试数据。数据虽然是RGB格式,但是通过使用constants.js模块,可以将通道数减少到1并且选择黑白显示。

TensorFlow Visor中随机显示的42个手势图像
选择模型开始训练
此外,侧菜单还显示了模型层、未经训练样本的结果、训练样本的统计数据和训练样本的结果。接下来的两个按钮,你可以选择建立模型的类型了,建立简单模型还是复杂模型?

简单还是复杂?正如“To be or not to be?”这个哲学问题一样,模型的选择也是一大难题,你可能会想:“应该优先选择最先进的模型”,这是一个常见陷阱。如果选择高级模型,首先,它需要花更长的时间训练样本甚至结果也没有预想的那么好用。此外,如果训练时间过长,高级模型会出现过拟合数据的问题。(注:过拟合是模型在对训练数据进行预测时变得非常完美,由于模型对于训练数据过于符合,因此对于新数据而言反而并不适用)一个好的机器学习模型可以概括为下图:

使用一个复杂方程进行过拟合我选择建立了一个非常适合简单数据的简单模型,以及另一个对于来自多角度和复杂背景的手势真实照片更有用的高级模型。
训练过程在训练模型时,我们会获得每批次更新的图表,包括512个图像,以及每个时期更新的另一张图表,包括所有的2100个训练图像,一个健康的训练迭代应具有损失减少,准确性提高等特征。
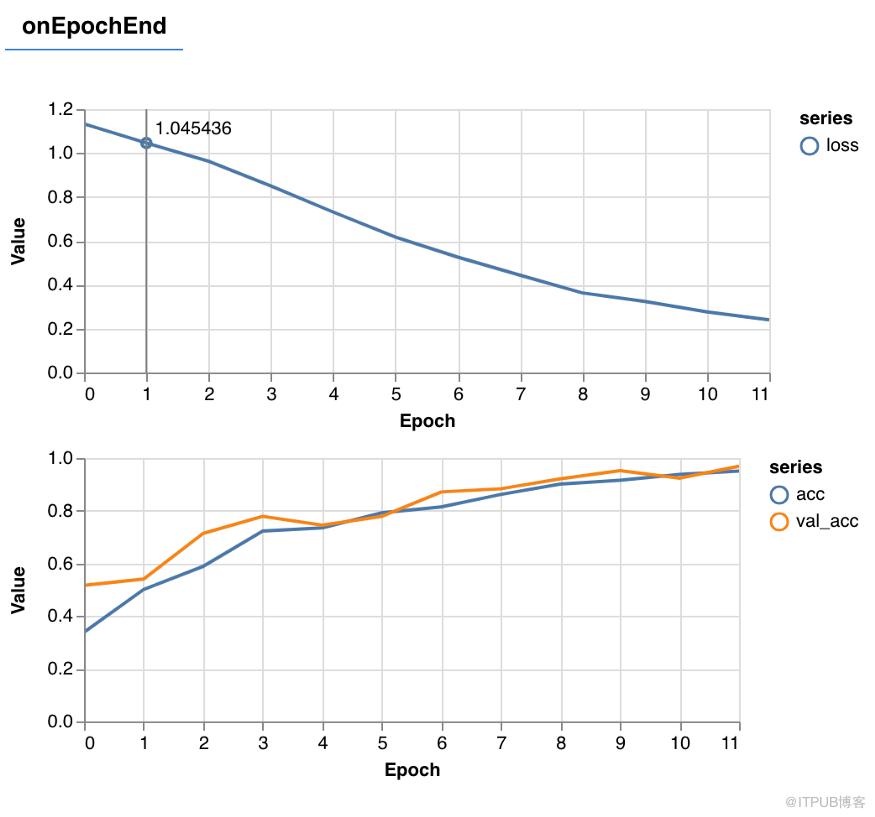
精度图中的橙色线表示验证数据的准确度,即用训练模型去预测剩余的420个未训练图像时的准确度。我发现代表验证数据的橙色线与训练数据精度几乎重合,这说明建立的模型可以广泛推广(只要新图像的复杂性和风格与已知图像相似)。
训练结果点击“检查训练模型”,可以得到与预期相符结果如下:
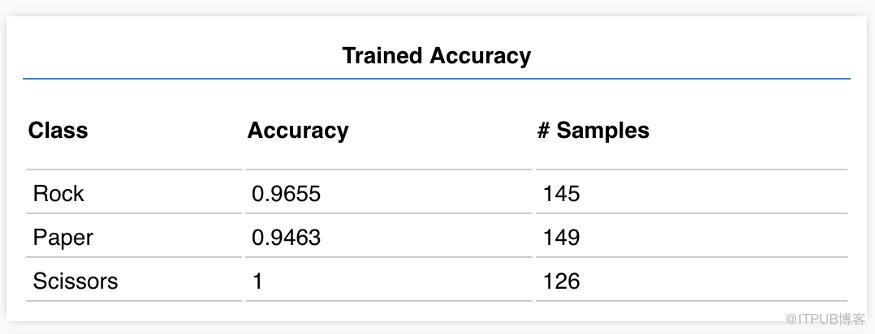
上表显示,代表剪刀手势图像的辨别十分准确,辨别准确性最低的是代表布的手势图像,其准确度只有95%,你的结果可能和本文结果略有不同,这是由初始训练数据的随机性导致的。为进一步挖掘具体原因,我做出如下混淆矩阵:
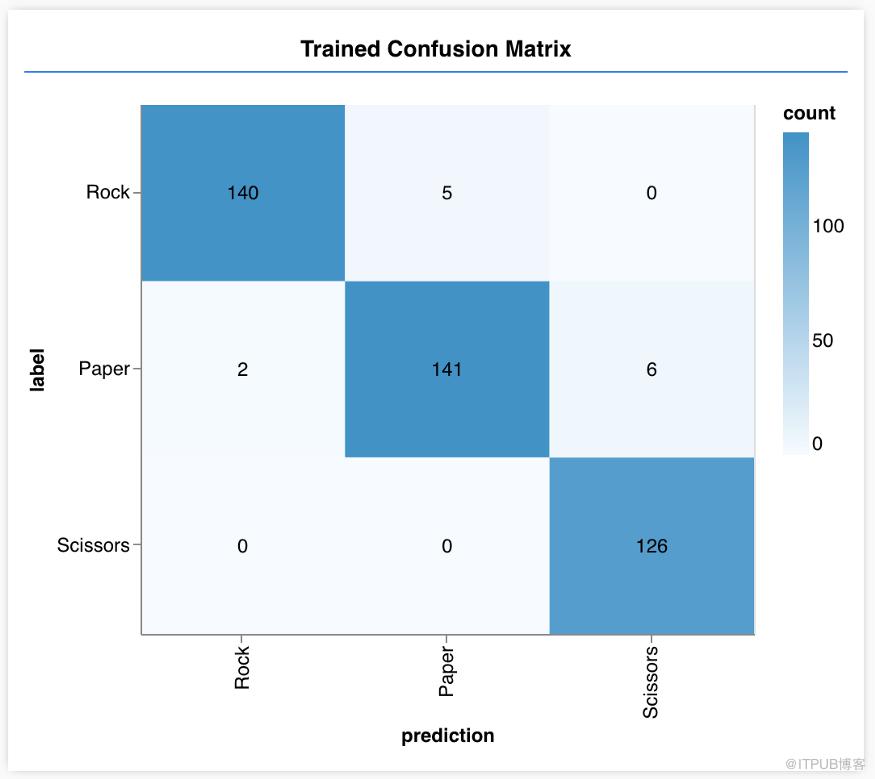
与预期相符的混淆矩阵从图中我们可以发现代表布的手势被错误地辨别为代表剪刀的手势6次,这种错误很容易理解,因为代表布的手势有时候看起来与代表剪刀的手势很像,我们可以选择接受这种错误或训练更多样本来改进错误,上述混淆矩阵可以帮助我们找出需要改进的错误所在。
模型测试
现在终于可以在现实世界中测试我们的模型了,我们使用网络摄像头检查自己做出的代表石头剪刀布的手势图像。需要注意的是我们的手势图像应与训练图像类似,没有旋转角度且背景为白色,便于模型进行识别。到这儿你已经可以在浏览器中训练模型并进行了验证,并进一步实现了现场测试,现在请把手举到顶,并缓缓张开五指,你可以给自己放一个烟花了,恭喜你完成了所有的步骤。

相关报道:https://heartbeat.fritz.ai/using-tensorflow-js-to-train-a-rock-paper-scissors-model-b5f393b548eb