
在快速发展的大型语言模型世界中 (LLM),一个新的挑战者已经出现,声称其表现优于卫冕冠军 OpenAI 的 GPT-4。 Anthropic 是人工智能领域相对较新的参与者,最近宣布了 Claude 3 发布,这是一个强大的语言模型,具有三种不同的大小:Haiku、Sonnet 和 Opus。
与以前的模型相比,新的 Claude 3 模型显示出增强的上下文理解,最终导致拒绝更少(如上图所示)。该公司声称 Claude 3 Opus 模型可以媲美甚至超越GPT-4 考虑各种基准测试的性能。专家们就 Claude 3 作为市场上卓越的语言模型是否优于 GPT-4 进行了热烈的辩论。
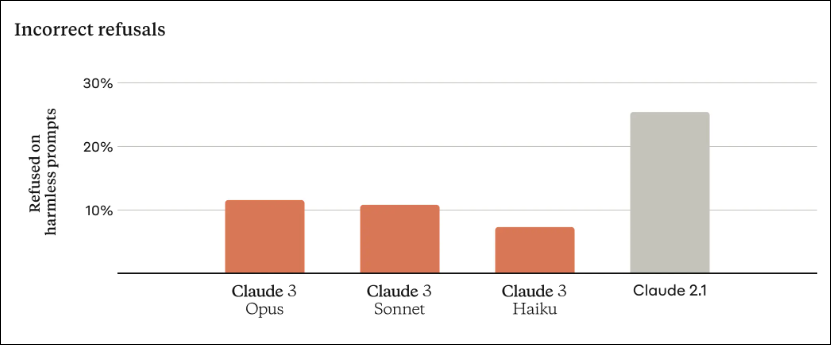
这种全面的分析涉及两种模型的优势、局限性以及跨不同基准的实际应用。
性能:仔细观察
基准和分数
Anthropic 引用基准分数来支持其声称 Claude 3 Opus 模型优于 GPT-4。 Anthropic 引用基准分数来支持其说法,即 Claude 3 Opus 模型优于 GPT-4。例如,在评估语言模型理解和推理自然语言能力的 GSM8K 基准测试中,Claude 3 Opus 模型的表现明显优于 GPT-4,得分为 95.0%,而 GPT-4 的得分为 92.0%。
但是,需要注意的是,此比较是针对默认的 GPT-4 模型,而不是高级 GPT-4 Turbo 变体。当将 GPT-4 Turbo 纳入等式时,情况发生了变化:在相同的 GSM8K 测试中,GPT-4 Turbo 的得分高达 95.3%,令人印象深刻,超越了 Claude 3 Opus 模型。
与 GPT-4V 类似,Claude 3 也带有 Vision 支持,并且还创建了跨语言理解、推理等基准。 Claude 3 系列包含三种型号:即 Claude 3 Opus、Claude 3 Sonnet 和 Claude 3 Haiku。 Sonnet 是 Anthropic 发布的三个纯文本版本的多模态模型之一,对于大多数工作负载来说,其速度是 Claude 2 模型的 2 倍。 Claude 3 Haiku 是最快、最便宜的模型,可以在 3 秒内轻松处理 10,000 个标记的研究论文,而 Opus 在 GPQA、MMLU 和 MMMU 等评估中提供了惊人的结果,在人类水平的理解等最困难的任务上表现出流畅性。
输入/输出种类
GPT-4 拥有明显优势的一个领域是它能够处理各种输入和输出格式。 GPT-4 的功能包括理解各种形式的数据,包括文本、代码、视觉效果和音频输入。它通过理解和组合这些不同的信息来生成精确的输出。此外,GPT-4V 变体可以通过分析文本或视觉提示来生成新颖且独特的图像,使其成为需要视觉内容创建的领域的专业人士的多功能工具。
相比之下,Claude 3 模型仅限于处理文本和视觉输入,仅生成文本输出。虽然它可以从图像中提取见解并读取图形和图表,但它无法像 GPT-4V 那样产生视觉输出。此外,Claude 3 Sonnet模型虽然比GPT-3.5更先进,但在整体能力上仍然弱于GPT-4。
提示关注并完成任务
两种模型在遵循提示和完成任务时都展示了令人印象深刻的功能,但略有差异。 Claude 3 Opus 模型比 GPT-4 具有更先进的提示跟随技能,通过跟随给定的提示生成 10 个逻辑输出,而 GPT-4 只能生成 9 个。然而,Claude 3 Sonnet 模型滞后,仅生成 7 个逻辑句子在同一个测试中。
这表明,虽然顶级 Claude 3 Opus 在提示跟随方面表现出色,但与 GPT-4 相比,更易于访问的 Sonnet 模型存在不足。此外,GPT-4 在任务完成和推理方面的表现可能会因具体任务和上下文的不同而有所不同。
可访问性和费用
在可访问性和成本方面,GPT-4 比 Claude 3 稍有优势。虽然 OpenAI 提供对 GPT-3.5 模型的免费访问,但访问 GPT-4 需要订阅 OpenAI Plus,这涉及到每个模型的成本。月。此订阅允许用户访问 GPT-4 模型及其高级功能,例如自定义 GPT 和网络搜索功能。
另一方面,要体验 Claude 3 Sonnet 模型,用户只需在 Anthropic 的官方网络聊天机器人界面上创建一个帐户,该界面可在 159 个国家/地区使用。但是,要访问更强大的 Claude 3 Opus 模型,用户必须订阅 Anthropic 的付费 Claude Pro。
结论:细致入微的比较
Anthropic 的 Claude 3 Opus 模型和 OpenAI 的 GPT-4 是具有独特优势的强大语言模型。虽然 Anthropic 声称 Claude 3 Opus 在某些任务中优于 GPT-4,但 GPT-4 Turbo 的引入使比较变得复杂。 GPT-4 Turbo 似乎具有整体优势,在 GSM8K 等基准测试中得分更高。然而,Claude 3 Opus 擅长遵循提示,在给出提示时生成更多逻辑输出。两种型号之间的选择还可能取决于可访问性和成本因素,Claude 3 提供了更实惠的选择来访问其较低层的型号。
就整体性能而言,GPT-4 Turbo 似乎比 Claude 3 Opus 稍有优势。它在多个旨在测试语言模型在各种任务中的能力的基准测试中取得了更高的分数。这些基准评估连贯性、事实准确性和推理能力等因素。然而,值得注意的是,没有一个基准可以提供模型性能的完整情况,并且不同的基准可能有不同的优势。
另一方面,Claude 3 Opus 的突出之处在于它能够更严格地遵循提示并生成与给定指令在逻辑上更加一致的输出。这在精确遵守提示至关重要的场景中尤其有价值,例如在特定于任务的应用程序中。
最终,Claude 3 和 GPT-4 之间的决定将取决于用户的具体需求和优先级。
语言模型的未来
随着人工智能领域不断快速发展,这些强大的语言模型之间的竞争可能会加剧。虽然 Claude 3 无疑已强势进入市场,但 GPT-4 的多功能性和性能使其成为强大的对手。
语言模型和人工智能助手的不断进步为用户带来了巨大的优势。随着这些技术变得越来越广泛,它们有能力改变各个部门并赋予个人和企业权力。
无论哪种模型最终处于领先地位,有一个确定性仍然存在:大型语言模型的时代已经到来,它们对我们日常生活和职业生涯的影响只会增强。
结论
Claude 3 和 GPT-4 之间的战斗只是一场持续的军备竞赛的开始,这场竞赛的目的是开发日益复杂和强大的大型语言模型。随着 Anthropic 和 OpenAI 等公司带来创新,人工智能世界正在不断发展。然而,做出明确的比较或优越性主张需要仔细考虑。虽然基准测试提供了有价值的见解,但现实世界的应用程序可能会揭示这些指标无法完全捕获的复杂性。此外,随着 GPT-4 Turbo 等新进步迅速改变竞争环境,情况也在迅速变化。在评估这些复杂的语言模型时,平衡的视角至关重要。

