水涨船高,法学硕士的最新进展也不例外。在这篇博文中,我们将探讨知识图谱如何从法学硕士中受益,反之亦然。

特别是,知识图可以使用 Graph RAG 将 LLM 与事实结合起来,这比 Vector RAG 更便宜。我们将查看 LlamaIndex 中的 10 行代码示例,看看它是多么容易启动。法学硕士可以帮助构建自动化知识图谱,这在过去一直是一个瓶颈。图表可以为您的领域专家提供一个界面来监督您的人工智能系统。
Spacy IRL 2019 的记忆之旅
我从事自然语言处理工作已经有几年了,我已经看到了大型语言模型的兴起。我的 NLP 和图工作开始可以追溯到 2018 年,当时我在德国柏林的一家足球媒体公司 OneFootball 担任机器学习工程师,并将其应用于体育媒体领域。
作为一名从业者,我对那段时光记忆犹新,因为那是 NLP 领域发生巨大变革的时期。我们正在从基于规则的系统和词嵌入时代转向深度学习时代,从 LSTM 转向基于 Transformer 架构的 Elmo 或 ULMfit 等一系列模型。我是少数能够参加在柏林举行的 Spacy IRL 2019 会议的幸运者之一。随后举办了企业培训研讨会,讨论了变形金刚、对话式人工智能助手以及 NLP 在金融或媒体领域的应用。
在主题演讲NLP 中缺失的元素 (spaCy IRL 2019) 中,Yoav Goldberg 预测下一个大的发展将是让非专家也能使用 NLP。他是对的。他认为我们可以通过人类在深度学习的帮助下编写规则来实现这一目标,从而产生透明且可调试的模型。他错了。我们通过聊天达到了这一点,现在我们的模型透明度和可调试性都较差。我们在他的图表上进一步向右和向下移动(见下文),到达比深度学习更深的地方。我们是否可以转向适用于非专家且数据很少的更透明的模型,目前尚无定论。
在我当时的雇主 OneFootball 的背景下,OneFootball 是一家拥有 12 种语言、每月拥有 1000 万活跃用户的足球媒体,我们使用 NLP 来协助我们的新闻编辑室并解锁新产品功能。我构建了从足球文章中提取实体和关系、标记新闻并向用户推荐文章的系统。我在柏林 NLP 聚会的之前的演讲中分享了其中的一些工作。我们有中等数据,但不是很多。我们有“重新标记”形式的部分标签。我们也无法支付太多的计算费用。所以我们必须要有创意。这是应用 NLP 的领域。
就是在那里,我偶然发现了图谱的美丽世界,特别是我现在的朋友 Paco Nathan 及其图书馆的伟大作品 pytextrank。图(以及基于规则的匹配器、弱监督和我多年来应用的其他 NLP 技巧)帮助我处理少量带注释的数据,并结合领域专家的声明性知识,同时构建一个可由非专家使用和维护的系统,具有一定程度的人机协作。我们提供了更好的标签系统和新的推荐系统,我被迷住了。
如今,随着法学硕士的兴起,我看到了将图谱和法学硕士这两个世界结合起来的巨大潜力,我想与您分享。
1。使用图 RAG 进行事实基础
1.1 微调与检索增强生成
图表和法学硕士的第一个交汇点是事实基础领域。法学硕士面临着幻觉、知识切断、偏见和缺乏控制等问题。为了规避这些问题,人们转向了可用的域数据。特别是,出现了两种方法:微调和检索增强生成(RAG)。
首席科学家 Waleed Kadous 博士在 3 个月前的 AI 大会上生产中的法学硕士演讲中在 AnyScale 上,对两种方法之间的权衡提供了一些启示。 “微调是为了形式,而不是事实,”他说 。 “RAG 代表事实”。
微调将变得更容易、更便宜。开源库,例如 OpenAccess-AI-Collective/axolotl 和 OpenAccess-AI-Collective/axolotl com/huggingface/trl”>huggingface/trl 已经使这个过程变得更容易。但是,它仍然是资源密集型的,并且需要更多的 NLP 成熟度作为一项业务。另一方面,RAG 更容易访问。
根据 2 个月前的黑客新闻帖子,询问 HN:如何在我的计算机上训练自定义 LLM/ChatGPT 2023年12月的文件?,绝大多数从业者确实在使用RAG而不是微调。
1.2 矢量 RAG 与图 RAG
当人们说RAG时,他们通常指的是Vector RAG,它是一个基于向量数据库的检索系统。在他们的博客文章和随附的笔记本教程,NebulaGraph 引入了一种称为 Graph RAG 的替代方案,这是一个基于图数据库的检索系统(免责声明:他们是图数据库供应商)。他们表明,RAG 系统检索的事实将根据所选架构的不同而有所不同。
它们还显示在单独的教程部分中LlamaIndex 文档指出,Graph RAG 更简洁,因此在代币方面比 Vector RAG 更便宜。
1.3 RAG动物园
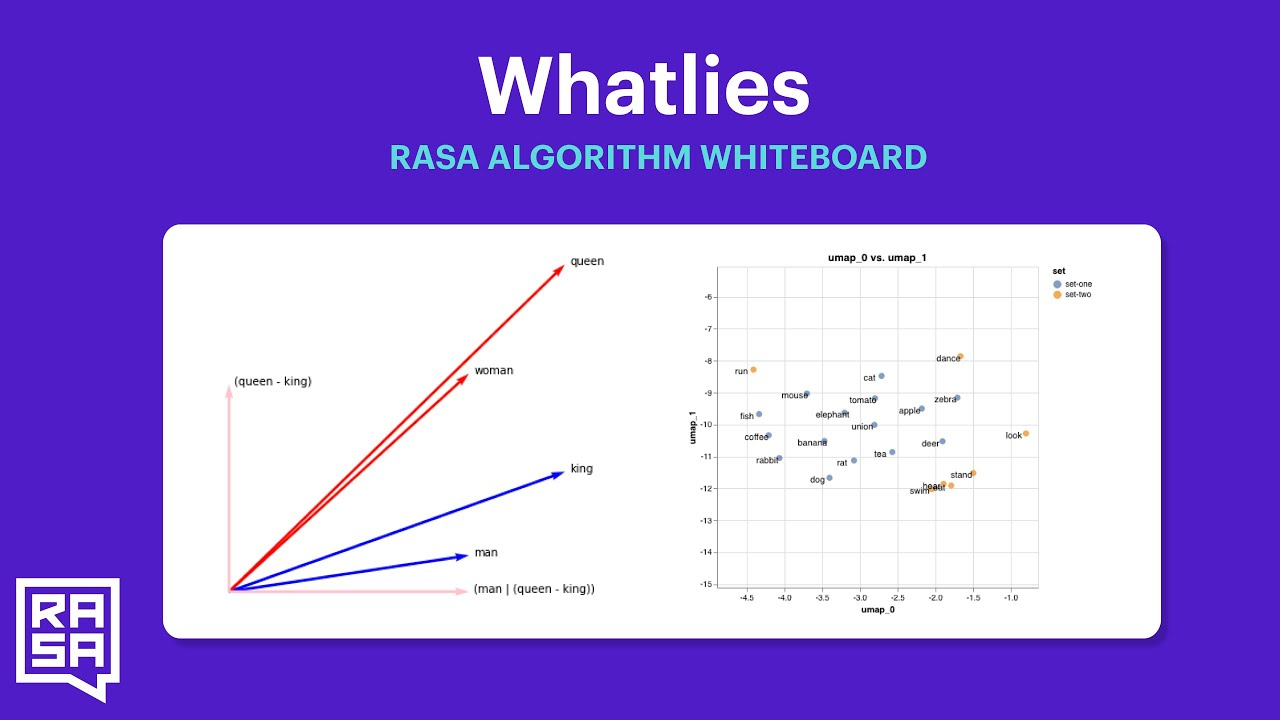
为了理解不同的 RAG 架构,请考虑我创建的以下图表:
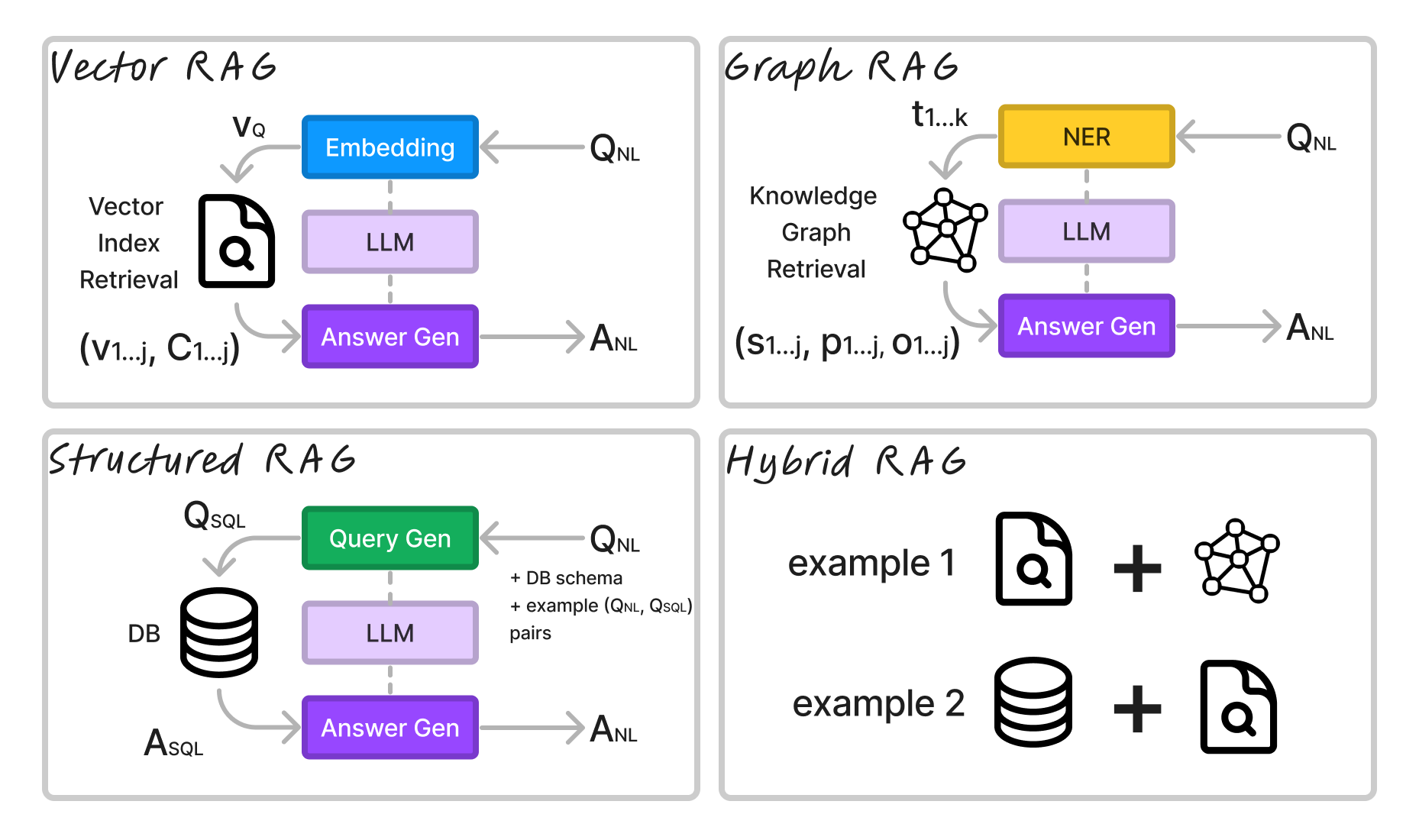
在所有情况下,我们都用自然语言 QNL 提出问题,并用自然语言 ANL 得到答案。在所有情况下,都有某种从问题中提取结构的编码模型,再加上某种生成答案的生成器模型(“答案生成器”)。
Vector RAG 嵌入查询(通常使用比 LLM 更小的模型;例如 FlagEmbeddings 或 Huggingface Embeddings Leaderboard)到向量嵌入 vQ 中。然后,它从向量数据库中检索最接近 vQ 的前 k 个文档块,并将它们作为向量和块返回 (vj, Cj< /子>)。这些内容与 QNL 作为上下文一起传递给 LLM,生成答案 ANL。
Graph RAG 从查询中提取关键字 ki 并从图中检索与关键字匹配的三元组。然后将三元组 (sj, pj, oj) 与 QNL 一起传递给 LLM ,生成答案 ANL。
结构化 RAG 使用生成器模型(LLM 或更小的微调模型)以数据库的查询语言生成查询。它可以生成 RDBMS 的 SQL 查询或 Graph DB 的 Cypher 查询。例如,假设我们查询 RDBMS:模型将生成 QSQL,然后将其传递到数据库以检索答案。我们记下答案 ASQL,但这些是在数据库中运行 QSQL 产生的数据记录。答案 ASQL 以及 QNL 被传递到 LLM 以生成 ANL。
在混合 RAG 的情况下,系统使用上述的组合。除了本文之外,还有多种混合技术。简单的想法是,您将更多上下文传递给 LLM 的 Answer Gen,然后让它利用其总结能力来生成答案。
1.4 LlamaIndex 中的图 RAG 实现
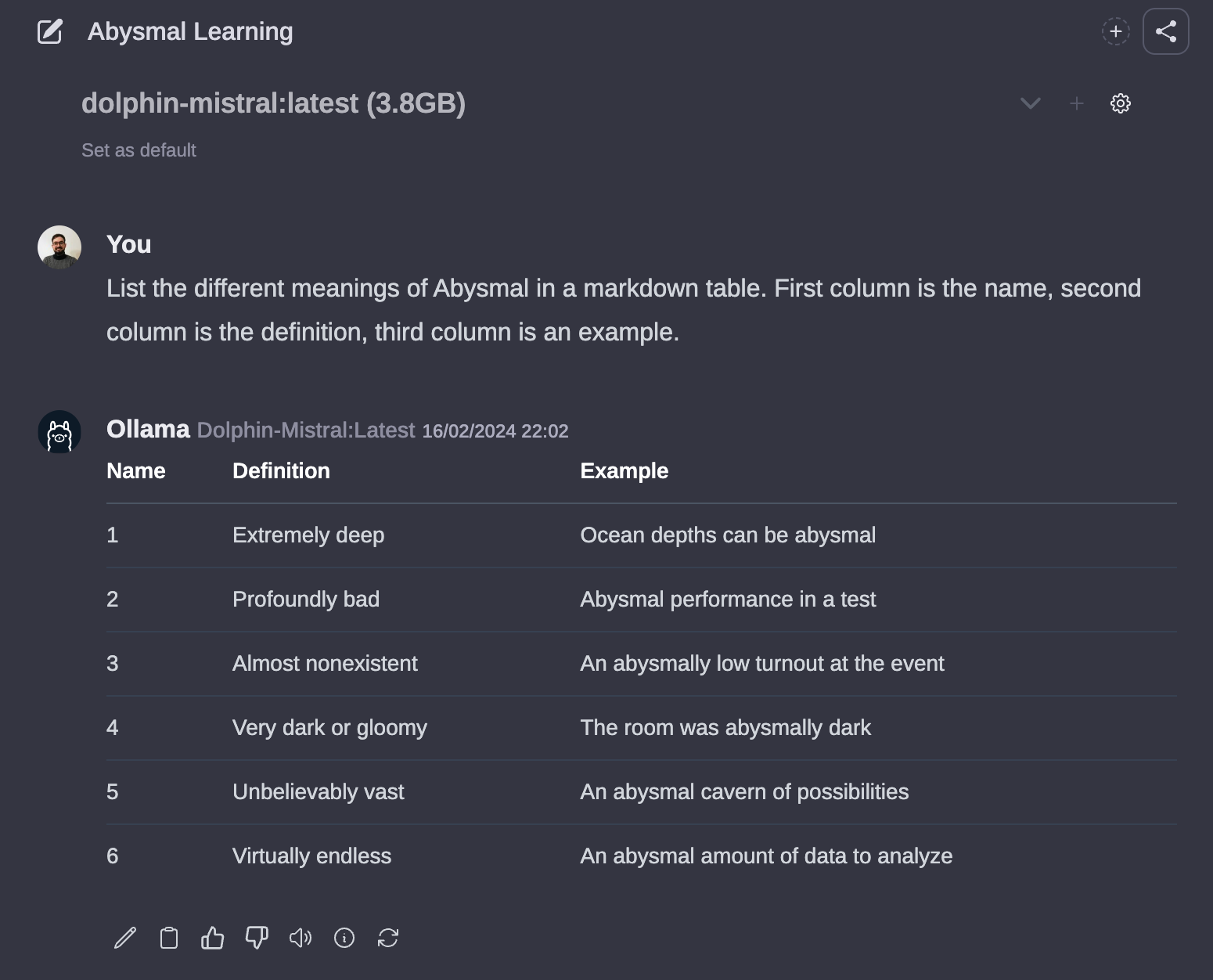
现在的代码,使用当前的框架,我们可以用 10 行 Python 构建一个 Graph RAG 系统。
“`” data-lang=”text/x-python”>
```python
从 llama_index.llms 导入 Ollama
从 llama_index 导入 ServiceContext、KnowledgeGraphIndex
从 llama_index.retrievers 导入 KGTableRetriever
从 llama_index.graph_stores 导入 NebulaGraphStore
从 llama_index.storage.storage_context 导入 StorageContext
从 llama_index.query_engine 导入 RetrieverQueryEngine
从 llama_index.data_structs.data_structs 导入 KG
从 IPython.display 导入 Markdown,显示
llm = Ollama(model='mistral', base_url="http://localhost:11434")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local:BAAI/bge-small-en")
graph_store = NebulaGraphStore(space_name="维基百科", edge_types=["关系"], rel_prop_names=["关系"], 标签=["实体"])
storage_context = StorageContext.from_defaults(graph_store=graph_store)
kg_index = KnowledgeGraphIndex(index_struct=KG(index_id="向量"), service_context=service_context, storage_context=storage_context)
graph_rag_retriever = KGTableRetriever(索引= kg_index,retriever_mode =“关键字”)
kg_rag_query_engine = RetrieverQueryEngine.from_args(retriever=graph_rag_retriever, service_context=service_context)
response_graph_rag = kg_rag_query_engine.query("告诉我关于彼得·奎尔的事。")
显示(Markdown(f"{response_graph_rag}"))
```此代码段假设您有 Ollama 提供 mistral 模型和本地运行的 Nebula 实例。它还假设您的 Nebula 数据库中加载了知识图,但如果没有,我们将在下一节中介绍如何构建知识图。
星云入门详细信息
您可以使用 Docker 桌面 Nebula 扩展启动 Nebula 实例。
运行 Nebula 后,您需要进行首次设置:
```密码
添加主机“存储0”:9779,“存储1”:9779,“存储2”:9779
```那么在使用之前需要先创建索引:
```密码
创建空间维基百科(vid_type = FIXED_STRING(256),partition_num = 1,replica_factor = 1);
```和:
```密码
使用维基百科;
创建标签实体(名称字符串);
创建边缘关系(关系字符串);
创建标签索引实体索引实体(名称(256));
```在进行推理之前,您需要在向量数据库或图形数据库中对数据建立索引。
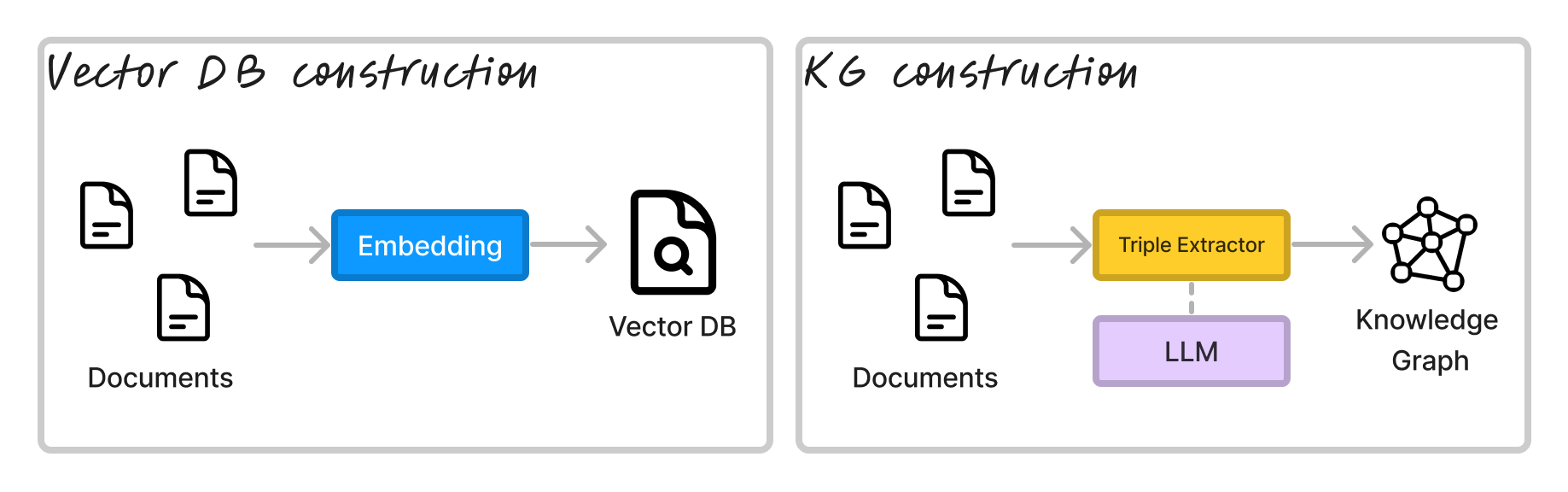
RAG 的索引架构 Vector RAG 的分块和嵌入文档相当于为 Graph RAG 提取三元组。三元组的形式为 (s, p, o),其中 s 是主语,p 是谓语,o 是宾语。主语和宾语是实体,谓语是关系。
有几种方法可以从文本中提取三元组,但最常见的方法是使用命名实体识别器 (NER) 和关系提取器 (RE) 的组合。 NER 将提取诸如“Peter Quill”和“Guardians of the Galaxy Vol 3”之类的实体,而 RE 将提取诸如“plays role in”和“directed by”之类的关系。
有专门针对 RE 的微调模型,例如 REBEL,但人们开始使用 LLM 来提取三元组。这是 LlamaIndex for RE 的默认提示链:
```jinja
下面提供了一些文字。给定文本,提取最多
{max_knowledge_triplets}
形式为(主语、谓语、宾语)的知识三元组。避免停用词。
--------------------
例子:
文本:爱丽丝是鲍勃的母亲。
三胞胎:(爱丽丝,是鲍勃的母亲)
文字:Philz 是一家于 1982 年在伯克利成立的咖啡店。
三胞胎:
(Philz,是,咖啡店)
(菲尔兹,创立于伯克利)
(菲尔兹,成立于 1982 年)
--------------------
文本:{文本}
三胞胎:
```这种方法的问题在于,首先您必须使用正则表达式解析聊天输出,其次您无法控制提取的实体或关系的质量。
2.2 LlamaIndex中的KG构建实现
但是,使用 LlamaIndex,您可以使用以下代码片段在 10 行 Python 中构建知识图谱:
```python
从 llama_index.llms 导入 Ollama
从 llama_index 导入 ServiceContext、KnowledgeGraphIndex
从 llama_index.graph_stores 导入 NebulaGraphStore
从 llama_index.storage.storage_context 导入 StorageContext
从 llama_index 导入 download_loader
llm = Ollama(model='mistral', base_url="http://localhost:11434")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local:BAAI/bge-small-en")
graph_store = NebulaGraphStore(space_name="维基百科", edge_types=["关系"], rel_prop_names=["关系"], 标签=["实体"])
storage_context = StorageContext.from_defaults(graph_store=graph_store)
loader = download_loader("WikipediaReader")()
文档 = loader.load_data(pages=['银河护卫队第 3 卷'], auto_suggest=False)
kg_index = KnowledgeGraphIndex.from_documents(
文件,
存储上下文=存储上下文,
服务上下文=服务上下文,
max_triplets_per_chunk=5,
include_embeddings=真,
kg_triplet_extract_fn=无,
kg_triple_extract_template=无,
space_name=“维基百科”,
edge_types=["关系"],
rel_prop_names=["关系"],
标签=[“实体”],
)
```2.3 基于LLM的KG构建的失败模式示例
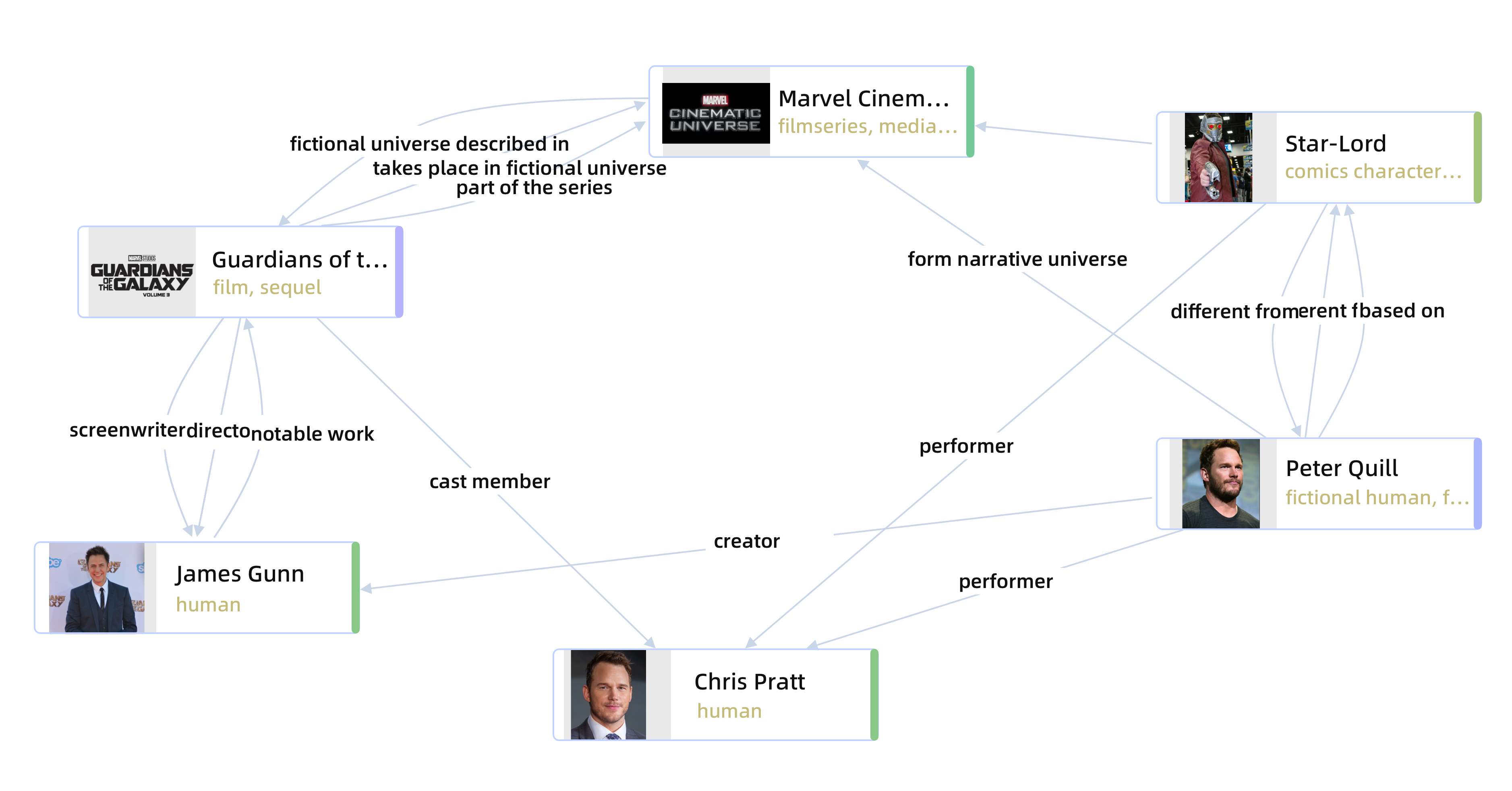
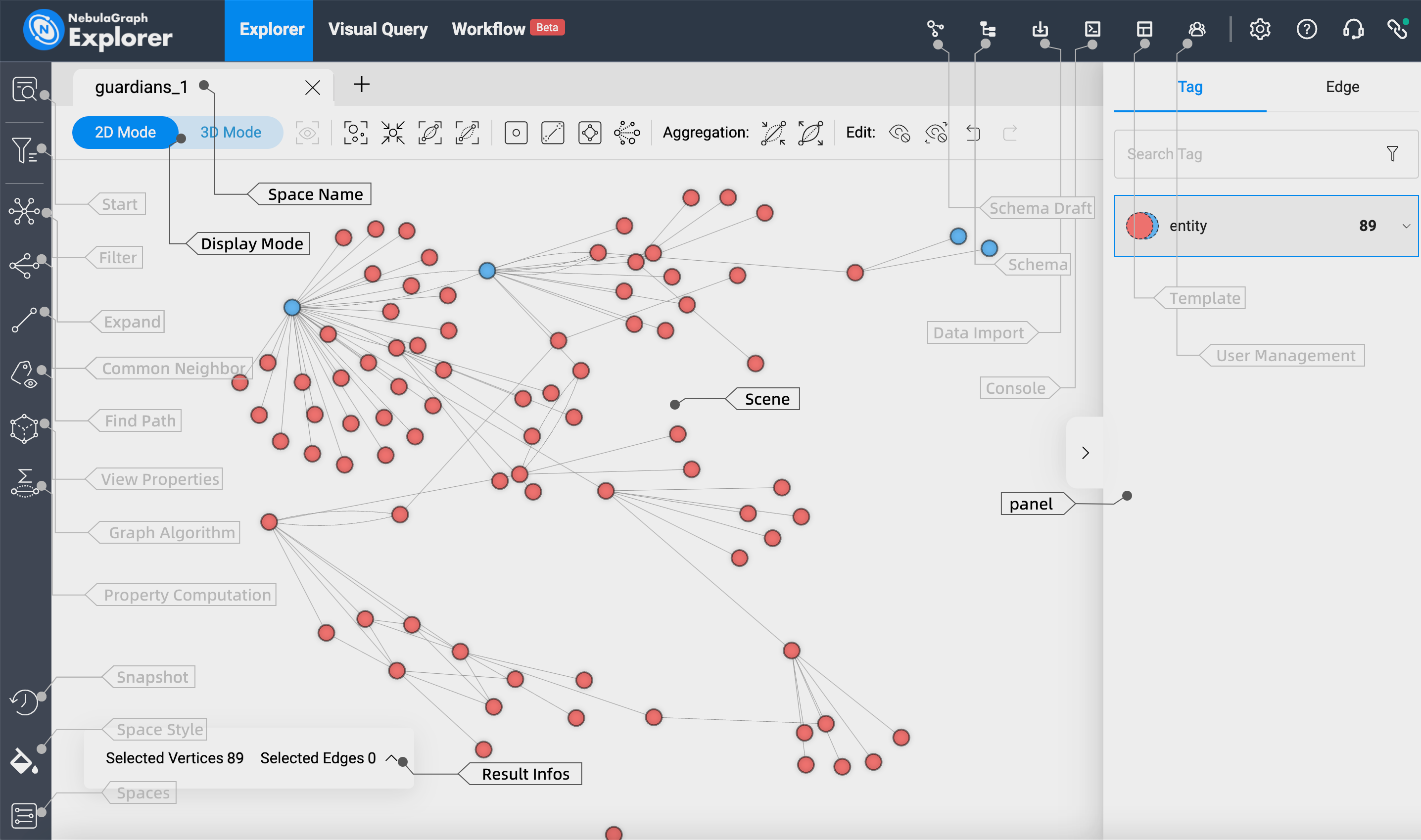
但是,如果我们查看电影“银河护卫队第 3 卷”的最终 KG,我们可以注意到一些问题。
以下是问题的表格概述
| # | 观察到 | 预期 | 评论 |
| 1。 | “Peter Quill / star-lord” vs “Quill” 或 “Guardians of the Galaxy” vs “Vol. 3” 是独立的实体 | 不同的同义词仍应消除同一实体的歧义 | 实体链接系统用于通过收集的“表面形式”消除实体的歧义 |
| 2。 | “扮演角色”和“是演员阵容的一部分”是不同的关系,但含义相同 | 关系应该一致,或者更好的是,与提供的受控词汇表相匹配 | 关系提取系统用于提取标准化关系 |
| 3。 | 三元组(Quill,在《银河护卫队》中使用未经审查的语言)和(James Gunn,无法想象,《银河护卫队》)不精确 | 如果找到三元组,它应该解析为最重要的信息。在这种情况下(奎尔,出现在《银河护卫队》中)或(詹姆斯·冈恩,执导过《银河护卫队》) | 可以通过对关系使用受控词汇来缓解 |
 项目和
项目和