
大家好,机器学习爱好者们!
在担任数据工程师几年后,我开始了新的旅程,深入研究机器学习的各个领域。这篇文章标志着我通过旨在学习和理解这个迷人领域的各种项目进行探索的开始。虽然我可能会从大型语言模型(LLM)开始,但我将其视为点燃我对这项新努力的热情和动力的第一步。和我一起进入机器学习的世界,渴望扩展我的知识和技能。
让我们一起踏上这段旅程!
简介
在过去的几周里,我注册了 ActiveLoop 的课程(感谢迭戈推荐)来深入了解大型语言模型 (LLM) 并更好地了解这个新兴领域。
本质上,大型语言模型是一种先进的人工智能系统,旨在理解和生成类似人类的文本。
完成课程后,我深入研究了有关构建 歌曲推荐系统。我发现它是从头开始开发类似系统的绝佳起点。
其概念是利用 DeepLake 和 LangChain 技术。 DeepLake作为一个为LLM应用程序量身定制的向量存储,其目标是通过利用LLM功能而不是直接查询嵌入文档来提高推荐准确性,从而完善推荐过程。
让我们分解一下创建 EmotiTuneOT(可能不是最好的名字)网络应用程序的整个过程根据用户输入的情绪推荐歌曲。我们的目标很简单:了解用户的心情并提供与该情绪产生共鸣的歌曲推荐。
让我们开始演出吧!
基本概念
矢量嵌入 是连续向量空间内各种实体(例如对象、文档、图像、音频文件等)的数字表示。这种数学表示旨在捕获这些实体的语义含义。向量的“维数”表示编码的特征或属性的总数。同时,向量的位置反映了向量空间中与其他实体的关系。嵌入通常由人工智能模型生成。
为了有效比较这些嵌入并寻找它们之间的相似性,搜索算法发挥着至关重要的作用。其中,余弦相似度是一个特别重要的概念。 余弦相似性使用两个向量在向量空间中之间的角度来确定两个向量在方向上的相似或不同程度。通过使用余弦相似度,系统可以执行相似度搜索,这是推荐系统的基础。
矢量数据库利用这些嵌入来有效地存储和组织数据。通过将数据表示为向量,向量数据库使机器学习模型能够轻松访问和操作数据以执行各种任务,例如相似性搜索、推荐系统和文本生成。存储在矢量数据库中的嵌入作为原始数据的紧凑且有意义的表示,有助于机器学习算法更快、更准确的处理。
数据收集
今年,我和我的妻子一直热衷于观看西班牙音乐真人秀节目“Operación Triunfo”。我决定利用他们的歌词作为我们项目的数据集,选择与最初考虑的迪士尼歌词相比更具文化相关性的来源。我使用了 Spotify 中的以下列表,其中包含所有内容与今年版本相关的歌曲。
我使用了两个主要库来从播放列表中抓取所有歌曲:
- Spotify:用于提取元数据,例如歌曲名称、艺术家、歌词、Spotify URL 等。
- LyricsGenius:Genius.com 的 Python 客户端API,托管所有歌词。
该过程很简单:使用 Spotify 从播放列表中检索所有曲目,然后使用 Genius API 获取所有歌词。
结果如下 json。< /p>
{
"name":"Histtorias Por Contar",
"spotify_track_url":"https://open.spotify.com/track/7HmviR8ziPMKDWBmdYWIFA",
"spotify_api_track_url":"https://api.spotify.com/v1/tracks/7HmviR8ziPMKDWBmdYWIFA",
“人气”:66,
"uri":"spotify:track:7HmviR8ziPMKDWBmdYWIFA",
"release_date":"2024-02-19",
“歌词”:“Solo hace falta creer Y que se caiga el mundo Solo hace falta sentir Hasta quedarnos mudos (Oh) Ya no hace falta decirnos nada Si me locuentas con la mirada Donde sea que est\u00e9 Yo te Guardo un caf\ Que nos haga recordar Que como agua de mar Somos la ola que suena al chocar (Oh-oh) Ll\u00e1malo Casualidad Pero esto se convirti\u00f3 en un hogar (Nuestro hogar) Y en las paredes quedar\u00e1n nuestros nombres En los声音声纳\u00e1n我们的声音Y el resto son historias por contar Explotamos de emoci\u00f3n Hasta quedarnos sin heavento P\u0435rdiendo noci\u00f3n de todo De c\u00f3mo pasaba \u0435l tiempo S\u00edrvame una ronda m\u00e1s不重要你可能还喜欢 哦,哦,哦,哦,哦,哦,哦 Que ma\u00f1ana empieza todo Que ma\u00f1ana empieza todo Que como agua de mar Somos la ola que suena al chocar (Al chocar, al chocar) Ll\u00e1malo Casualidad Pero esto se convirti\u00f3 en un hogar (Nuestro hogar) Y en las paredes quedar\u00e1n nuestros nombres En los rincones sonar\u00e1n nuestras voces (Uh) Y el Resto son historias por contar Y el Resto son historias por contar Que como agua de mar Somos la ola que suena al chocar (Al chocar, al chocar, oh, oh) Ll\u00e1malo Casualidad Pero esto se convirti\u00f3 en un hogar (Nuestro hogar) Y en las paredes quedar\u00e1n nuestros nombres En los rincones声纳\u00e1n nuestras voces (Nuestras voces) Y el resto son historias por contar Y el resto son historias por Y el resto son historias por contarEmbed"
}
向量嵌入策略
一旦我们获得了所有音乐数据,议程上的下一件事情就是找出表示这些数据以构建音乐推荐系统的最佳策略。
文章详细介绍了实现这些嵌入的各种方法。以下是概要:
歌词相似性搜索
第一种方法为歌词和用户输入生成嵌入,旨在基于余弦相似度进行匹配。虽然简单,但这种方法产生的结果并不理想。推荐歌曲的相似度得分始终低于 0.735,表明与预期结果明显脱节。
情感嵌入的相似性搜索
为了克服基于歌词的方法的缺点,该方法采用了更精细的策略。它使用 ChatGPT 将歌词转换为一组八种情感,然后针对这些情感配置文件执行相似性搜索。这种方法带来了更精确且与上下文相关的歌曲推荐。利用自定义 ChatGPT 提示将歌曲和用户输入显着转化为情感描述符提高了比赛质量。相似度得分有所上升,平均在0.83左右,更好地满足了用户的情感需求。
这些策略说明了从简单的歌词相似性搜索到更复杂的基于情感的匹配系统的进展,展示了细致入微的分析在提高推荐准确性方面的重要性。
基于这些见解,我们对基于情感的方法进行了批判性观察。用于代表歌曲的情感通常包括来自同一首歌的派生术语,例如“背叛”和“被背叛”。新方法涉及在从歌词中提取情感时传递每次迭代中已提取的情感列表。
通过这样做,我们可以避免添加任何修改后的术语,并确保情感表示的一致性。此调整旨在通过微调每首歌曲捕获的情感背景来提高歌曲推荐的准确性和相关性。
具体来说,我们将情感集从最初的 258 种减少到 108 种。这一减少代表着显着的改进,导致歌曲中使用的情感数量显着减少了约 58.14%分类。
因此,使用这种新策略检索的歌曲表现出显着的改进。值得注意的是,一些以前在最初方法中被忽视的歌曲现在出现在推荐中。这种增强归功于精细的情感表达,从而产生了更准确的结果。
此外,我们对箱线图的分析显示相似度分数显着增加,表明对合适歌曲的选择更加精细。这一改进凸显了我们更新的策略在增强推荐流程方面的有效性。

现在我们已经拥有了所有数据和嵌入策略,是时候深入构建推荐系统了。
推荐系统
首先,让我们存储数据。如前所述,我们正在利用 DeepLake 作为这些向量嵌入的首选向量存储。感谢 Langchain,有一个方便的 DeepLake 实现,可以让我们插入嵌入模型作为参数。这种设置使得生成嵌入变得超级简单和直观。您所要做的就是提供特征,然后瞧——您的数据集将全部设置完毕,嵌入整齐地存储在矢量存储中。
计划是处理文本并利用其他属性作为元数据。为此,我在 LangChain,特别是“text-embedding-ada-002”。此选择受到其在提供的示例中的使用的影响。展望未来,我热衷于在未来的文章中探索各种嵌入技术。
正如我们的嵌入策略中所述,我们计划通过嵌入捕捉歌词中的情感。为了实现这一目标,我们将使用 ChatGPT 和自定义提示。此外,在每次迭代中,我们都会识别并提取之前使用的情感,并将其合并到提示中。此步骤确保我们避开任何派生术语,保持我们的情感提取精确且相关。
这是使用的提示:
认为您是从歌词和名称翻译情感的专家。
这些歌曲将是西班牙语和英语,但情感应该只用英语。
给出以下歌曲{name}及其歌词:
{歌词}
请提供八种可以描述歌曲的情感,用逗号分隔,全部较低且没有任何其他特殊字符。
这些情感已经被用于一些歌曲中,请避免使用它们的派生术语,例如“背叛或背叛”
{情绪_使用}
80 年代的标志性歌曲《I Love Rock’N’Roll》具有以下情感
“兴奋、激情、赋权、喜悦、渴望、团结、期待、爱”。
下图描述了存储歌词的完整处理过程。
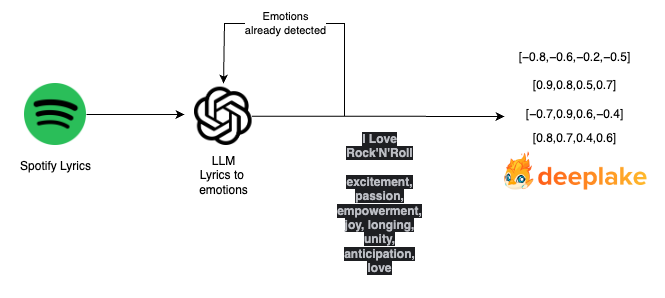 现在,我们必须将用户的句子转换为一组可以覆盖表示的情感。我们使用另一个自定义提示来执行此操作:
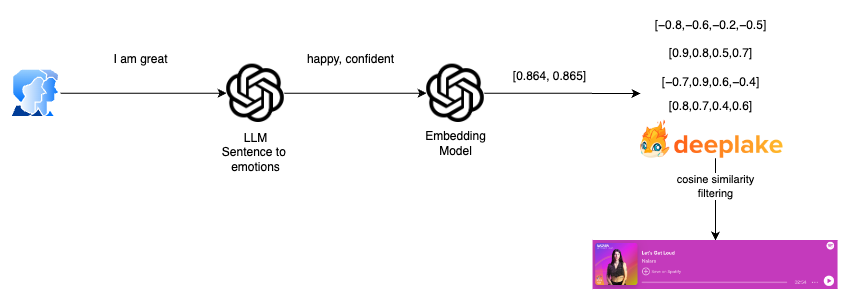
现在,我们必须将用户的句子转换为一组可以覆盖表示的情感。我们使用另一个自定义提示来执行此操作:
对于歌曲检索阶段,我们的系统采用两步过滤过程,以确保向用户呈现的歌曲不仅符合他们的情感输入,而且还可能吸引他们的音乐品味。最初,我们过滤掉未能满足预定义相似度阈值的歌曲。这个阈值至关重要,因为它有助于我们保持高相关性标准,确保只考虑与用户输入产生强烈情感共鸣的歌曲。
一旦我们获得了情感共鸣歌曲的过滤列表,我们就会进入选择过程的下一步,其中涉及利用 Spotify 的“流行度”指标。该指标由 Spotify API 提供,可衡量平台上当前曲目的受欢迎程度,同时考虑播放次数和收听行为的最新趋势等因素。
通过按“流行度”对情感匹配的歌曲进行排序,我们的目标不仅是使推荐与用户的情感状态保持一致,而且还确保这些歌曲属于当前更广泛的受众所喜爱的歌曲。
这种方法在情感准确性和音乐相关性之间取得了平衡,为用户提供既情感契合又广受赞赏的歌曲。
结论
在此过程中,我们探索了各种方法和方法来提高歌曲建议的准确性和相关性。机器学习领域广阔且不断扩展,为创新和进步提供了无限的机会。通过拥抱法学硕士和其他新兴技术带来的可能性,我们可以继续突破可能的界限,为未来创造更智能、直观和有影响力的解决方案。
期待开始新项目!