
这是 的全程指南Apache Doris 用户,尤其是来自金融行业的用户,对数据的安全性和可用性要求很高。如果您不知道如何构建实时数据管道并充分利用 Apache Doris 功能,请从这篇文章开始,读完后您将会受到启发。
这是一家为超过 2500 万家零售商提供服务并处理来自 4000 万家零售商的数据的非银行支付服务提供商的最佳实践终端设备。数据源包括MySQL、Oracle、MongoDB。他们使用 Apache Hive 作为离线数据仓库,但感觉需要添加实时数据处理管道。 引入 Apache Doris 后,他们的数据摄取速度提高了 2~5 倍,ETL 性能提高了 3~12 倍,查询执行速度提高了 10~15 倍。
在这篇文章中,您将学习如何将 Apache Doris 集成到您的数据架构中,包括如何在 Doris 内排列数据,如何将数据摄入其中,以及如何实现高效的数据更新。此外,您还将了解 Apache Doris 提供的企业功能,以保证数据安全、系统稳定性和服务可用性。
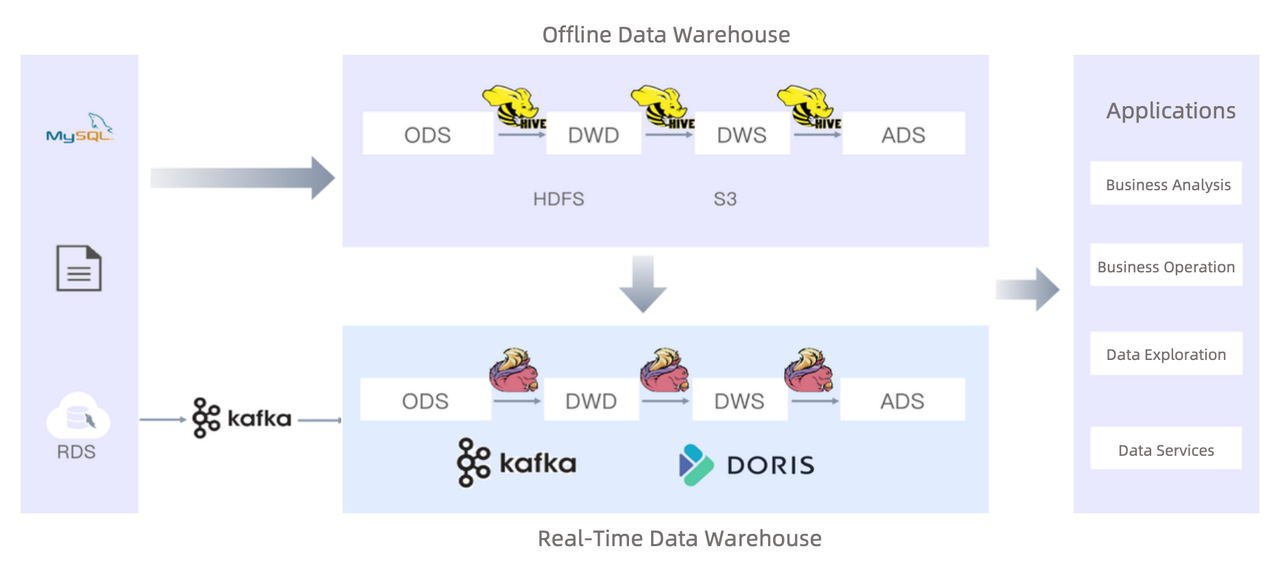
使用 Apache Doris 构建实时数据仓库
数据模型的选择
Apache Doris 使用三种数据模型来排列数据。这些模型之间的主要区别在于它们是否或如何聚合数据。
金融用户在不同数据仓库层采用不同的数据模型:
分区和分桶策略
分区和分桶的思想是将数据“切割”成更小的块以提高数据处理速度。关键是设置合适数量的数据分区和桶。根据他们的用例,用户为每个表定制分桶字段和桶编号。例如,他们经常需要从零售商平面表中查询不同零售商的维度数据,因此他们指定零售商ID列作为分桶字段,并列出各种数据大小的推荐桶数。
多源数据迁移
在采用 Apache Doris 时,用户必须将所有本地数据从其分支机构迁移到 Doris,此时他们发现自己的分支机构正在使用不同的数据库并且拥有数据文件格式非常不同,因此迁移可能会很混乱。

幸运的是,Apache Doris 支持丰富的数据集成方法,可用于实时数据流和离线数据导入。
完整数据摄取和增量数据摄取
为保证业务连续性和数据准确性,用户采用以下方式获取全量数据和增量数据:
ALTER TABLE t1 REPLACE WITH TABLE t2 语句用于用临时表原子替换常规表。此方法可以防止前端查询中断。
更改表 ${DB_NAME}.${TBL_NAME} 删除分区 IF EXISTS p${P_DOWN_DATE};
更改表 ${DB_NAME}.${TBL_NAME} 如果不存在则添加分区 p${P_DOWN_DATE} 值 [('${P_DOWN_DATE}'), ('${P_UP_DATE}'));
加载标签 ${TBL_NAME}_${load_timestamp} ...- 增量数据提取:创建新的数据分区以容纳增量数据。
离线数据处理
用户已将部分离线数据处理工作负载转移到 Apache Doris,从而执行速度提高了五倍。
- 之前:旧的基于Hive的离线数据仓库使用TEZ执行引擎每天处理3000万条新数据记录,2TB计算资源,整个管道耗时2.5小时。
- 之后:Apache Doris 只需 30 分钟即可完成相同的任务,仅消耗 1TB,脚本执行只需 10 秒而不是 8 分钟。
面向金融参与者的企业功能
多租户资源隔离
这是必需的,因为经常会发生多个团队或业务系统请求同一份数据的情况。这些任务可能会导致资源抢占,从而导致性能下降和系统不稳定。
不同工作负载的资源限制
用户将其分析工作负载分为四种类型,并为每种类型设置资源限制。特别是,他们有四种不同类型的Doris账户,并为每种类型的账户设置了CPU和内存资源的限制。
这样,当一个租户需要过多的资源时,只会损害自身的效率,而不会影响其他租户。
基于资源标签的隔离
为了母子公司层级下的数据安全,用户为子公司设置了隔离的资源组。各子公司的数据以3个副本存储在自己的资源组中,而母公司的数据以4个副本存储:3个在母公司资源组,1个在子公司资源组。因此,当子公司的员工向母公司请求数据时,查询将仅在子公司资源组中执行。具体来说,他们采取以下步骤:
工作负载组
基于资源标签的隔离方案保证了物理层面的隔离,但作为Apache Doris开发者,我们希望进一步优化资源利用率,追求更细粒度的资源隔离。为此,我们在 Apache Doris 2.0。
工作负载组机制将查询与工作负载组相关联,这限制了查询可以使用的后端节点的 CPU 和内存资源份额。当集群资源短缺时,最大的查询将停止执行。相反,当集群可用资源充足且某个工作负载组需要的资源超过限制时,将按比例分配空闲资源。
用户正在积极规划向工作负载组计划的过渡,并利用任务优先级机制和查询队列功能来组织执行顺序。
细粒度的用户权限管理
出于监管和合规原因,该支付服务提供商实施严格的权限控制,以确保每个人只能访问他们应该访问的内容。他们是这样做的:
ROW POLICY 机制使这些操作变得简单。
集群稳定性保证
跨集群复制
灾难恢复对于金融业至关重要。用户利用跨集群复制(CCR)能力构建双集群解决方案。在主集群承担全部查询的同时,主要业务数据也同步到备份集群并实时更新,以便在主集群出现服务故障时,备份集群能够快速接管,保证业务连续性。
结论
我们感谢用户一路以来与我们的积极沟通并很高兴看到这么多 Apache Doris 功能满足他们的需求。他们还计划利用 Apache Doris 探索联合查询、计算存储分离和自动维护。我们期待他们提供更多最佳实践和反馈。
