

当今的应用用户需要最好的用户体验。他们习惯于从所有设备(计算机、手机、平板电脑等)访问他们的应用程序。随着平台不断过渡到软件即服务 (SaaS),开发人员不断使用功能强大的工具进行协作,这些工具可承受每秒处理数千个请求的范围。这就是Apache Kafka,一个以处理高度紧张的环境而闻名的坚固工具。
在这篇文章中,我们将向您介绍Apache Kafka的基础知识,并着手使用Java和Kafka构建一个安全、可扩展的消息应用程序。
先决条件:Java8+,互联网连接,和免费的Okta开发者帐户。
阿帕奇·卡夫卡简介
Apache Kafka 是一个分布式流式处理平台,利用发布/订阅消息模式与应用程序进行交互;它旨在创建持久消息。
让我们更详细地细分这些概念。
分布式流式处理平台
当您想要运行 Kafka 时,您需要启动其代理:Kafka 在计算机上运行的简单实例,就像任何其他服务器一样。代理负责将消息发送、接收和存储到磁盘中。
单个代理不足以确保 Kafka 能够处理高吞吐量的消息。这一目标是通过许多经纪人同时合作、相互沟通和协调来实现的。
卡夫卡集群将一个或多个经纪人组合在一起。应用程序连接到群集,用于管理所有分布式详细信息,而不是连接到单个节点。
您可能还喜欢:
卡夫卡教程为大家,不管你在发展阶段。
使用持久消息发布/订阅消息系统
发布/订阅是分布式系统中的常见模式。下图说明了 Kafka 中此模式的基本结构:
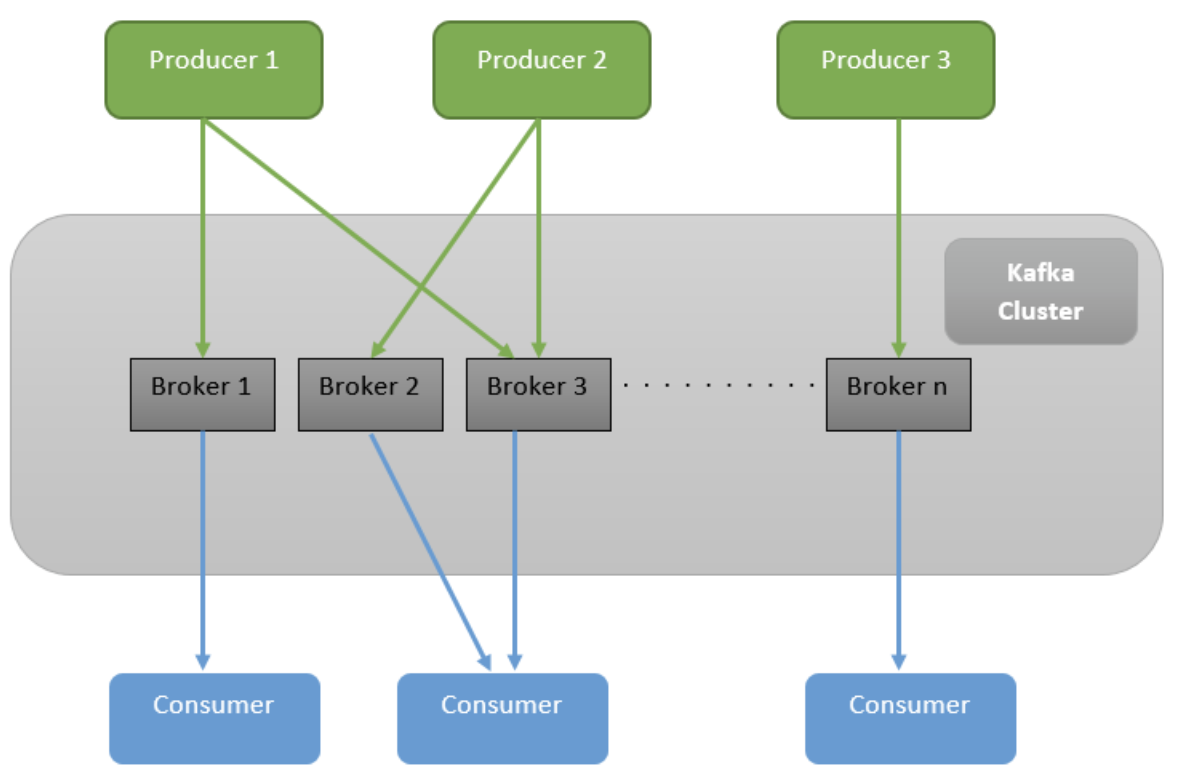
该图像包括两个到目前为止未提及的组件:生产者和消费者。
生产者是向群集发送消息的应用程序。在此示例中,生产者 1、2 和 3 正在发送消息。然后,群集选择应存储它们的经纪人并将其发送到选定的代理使用者是连接到群集并接收来自生产者发布的消息的应用程序。任何对使用生产者发送的消息感兴趣的应用程序都必须连接到 Kafka 使用者。
由于 Kafka 存储消息的时间很长(默认值为 7 天),因此,即使许多使用者在发送消息时不在那里,也可以让许多使用者接收相同的消息!
卡夫卡主题
当您向Kafka 代理发送消息时,您需要通过指定主题来指定消息的发送位置。主题是使用者可以订阅的消息类别。此机制可确保使用者只接收与其相关的消息,而不是接收发布到群集的每个消息。
现在您已经了解了 Kafka 的基本体系结构,让我们下载并安装它。
安装并运行卡夫卡
要下载卡夫卡,请访问卡夫卡网站。将此压缩文件的内容提取到您首选项的文件夹中。
在 Kafka 目录中,转到 bin 该文件夹。在这里,你会发现许多bash脚本,将可用于运行Kafka应用程序。如果使用 Windows,则文件夹中也具有相同的脚本 windows 。本教程使用 Linux 命令,但如果您运行的是 Microsoft 操作系统,则只需使用等效的 Windows 版本。
启动动物园管理员来管理您的卡夫卡集群
Apache Kafka 始终作为分布式应用程序运行。这意味着群集必须在此过程中处理一些分布式挑战,例如同步配置或选择领导者来处理群集。
卡夫卡使用动物园管理员来跟踪这些细节。不过,不要担心下载它。卡夫卡已经与动物园管理员一起发货,让你快速起床和跑步。
让我们开始一个动物园管理员的例子!在 bin Kafka 目录中的文件夹中,运行以下命令:
默认情况下,此命令在端口 2181 上启动 Zoo 管理员服务器。动物园管理员负责协调集群内的卡夫卡经纪人。本教程将使用 Kafka 项目中的默认配置,但始终可以根据需要更改这些值。
运行卡夫卡经纪人
下一步是运行代理本身。从另一个终端运行以下命令: bin
xxxxxxxxx
./kafka-server-start.sh . . ./配置/服务器.属性
您可能已经猜到,此命令运行 Kafka 服务器时默认端口 9092 上具有默认配置。
创建卡夫卡主题
现在,您已经运行了代理和 Zoo 管理员,您可以指定一个主题以开始从创建者发送消息。您将在文件夹中运行一个命令 bin ,就像在前面的步骤中所做的那样:
xxxxxxxxx
--创建--主题- 管理员|
--复制因子1-- 分区1
此命令创建一个名为指向 myTopic 您从第一个命令开始的 Zoostos 实例的主题。还必须指定两个不同的参数: replication-factor 和 partitions 。现在不要担心他们;它们用于控制与卡夫卡分布式系统相关的特定方面。在运行简单设置时,可以为这两个参数指定”1″。
现在,您已经启动并运行了所有内容,您可以开始将 Kafka 与 Java 应用程序集成!
创建 Java 和 Kafka 应用程序
让我们从项目结构开始,使用弹簧初始化程序创建应用程序。
转到https://start.spring.io并填写以下信息:
- 项目:马文项目
com.okta.javakafkakafka-java- 春季网。
- 阿帕奇·卡夫卡的春天
您还可以使用命令行生成项目。在终端中粘贴以下命令,它将下载具有上述相同配置的项目:
xxxxxxxxx
卷曲-d语言[java ]
-d依赖项 =Web,卡夫卡 |
-d包名称@com.okta.javakaka |
5
-d类型=maven 项目 |
-o卡夫卡-贾瓦.zip
本教程使用 Maven,但如果您愿意,您可以轻松地使用 Gradle 遵循它。
就是这样!现在,您的 Java 项目结构已创建,您可以开始开发应用。
在 Java 应用程序中将消息推送到 Kafka 主题
创建可以推送消息的创建器的第一步是在 Java 应用程序中配置创建者。让我们创建一个配置类来做到这一点。
创建一个 src/main/java/com/okta/javakafka/configuration 文件夹,并在其中创建一个 ProducerConfiguration 类:
xxxxxxxxx
导入组织.阿帕奇.卡夫卡.客户端。生产者。制作人康菲;
导入组织.阿帕奇.卡夫卡.常见。序列化.字符串序列器;
导入组织.弹簧框架。上下文。注释。豆豆;
导入组织.弹簧框架。上下文。注释。配置;
导入组织.弹簧框架。卡夫卡.核心.默认卡夫卡生产者工厂;
导入组织.弹簧框架。卡夫卡.核心.卡夫卡模板;
导入组织.弹簧框架。卡夫卡
生产商工厂;
导入java。乌蒂尔.哈希地图;
导入java。乌蒂尔.地图;
公共类生产者配置|
私人静态最终字符串KAFKA_BROKER="本地主机:9092";
19
返回新的DefaultKafkaProducerFactory<>(生产者配置));
}
公共映射<字符串对象>生产者配置() |
映射<字符串对象>配置=新的哈希Map<> (;
配置。put(生产者 Config.BOOTSTRAP_SERVERS_CONFIGKAFKA_BROKER);
配置
KEY_SERIALIZER_CLASS_CONFIG,字符串序列器.类);
配置。put(生产者 Config.VALUE_SERIALIZER_CLASS_CONFIG字符串序列器。类);
返回配置;
}
公共KafkaTemplate<字符串>kafkaTemplate() |
返回新的KafkaTemplate<>(生产商工厂());
}
}
此类创建 一 ProducerFactory 个 ,它知道如何根据您提供的配置创建生产者。您还指定连接到本地 Kafka 代理,并使用 序列化密钥和值 String 。
您还宣布了一个 KafkaTemplate Bean,用于对您的生产者执行高级操作。换句话说,模板能够执行诸如向主题发送消息和有效地隐藏隐藏隐藏细节等操作。
下一步是创建终结点以将消息发送到生产者。在 src/main/java/com/okta/javakafka/controller 包中,创建以下类:
导入组织
卡夫卡.核心.卡夫卡模板;
导入组织.弹簧框架。网络.绑定。注释。获取映射;
导入组织.弹簧框架。网络.绑定。注释。请求Param;
导入组织.弹簧框架。网络.绑定。注释。休息控制器;
导入java。乌蒂尔.列表;
公共类卡夫卡控制器|
公共卡夫卡控制器(卡夫卡模板<字符串,字符串> 模板) ]14这个.模板=模板;15}1617("/卡夫卡/生产")18公共无效产生(字符串消息) |19模板。发送("myTopic"消息);20}21注意:由于您要发送要处理的数据,
produce()因此该方法确实应该是 POST正如您所看到的,此终结点非常简单。它较早地注入配置的 ,
KafkaTemplate并在向myTopic发出请求时向 发送消息GET/kafka/produce。让我们测试一下是否一切按预期工作。
main在类中运行方法JavaKafkaApplication。要从命令行运行,请执行以下命令:壳
xxxxxxxxx11./mvnw 弹簧启动:运行您的服务器应在端口 8080 上运行,并且您已经可以针对它发出 API 请求!
转到您的 Web 浏览器并访问http://localhost:8080/kafka/produce?message=This是我的消息。
使用上述命令进行调用时,应用程序将执行
/kafka/produce终结点,该终结点向myTopicKafka 内的主题发送消息。但是,您如何知道该命令已成功向主题发送消息?现在,您不会使用应用内的消息,这意味着您无法确定!
幸运的是,有一个简单的方法来创建一个消费者来直接测试。在
binKafka 目录的文件夹中,运行以下命令:壳
xxxxxxxxxx11--引导服务器--主题我的专题访问http://localhost:8080/kafka/produce?message=This是我在运行 Kafka 使用者的终端中再次看到以下消息的消息:
壳
xxxxxxxxxx11这是我的信息干得好!您可以立即停止此命令。
让我们添加一些 Java 代码来使用应用内的消息,而不是从终端执行。
在 Java 应用程序中使用来自 Kafka 主题的消息
与生产者一样,您需要添加配置以使使用者能够找到 Kafka Broker。
在
src/main/java/com/okta/javakafka/configuration中创建以下类:Java
xxxxxxxxx1421导入组织.阿帕奇.卡夫卡.客户端。消费者。消费者协会;2导入组织.阿帕奇.卡夫卡.常见。序列化.字符串反序列化器;3导入组织.弹簧框架。上下文。注释。豆豆;4导入组织.弹簧框架。上下文。注释。配置;5导入组织.弹簧框架。卡夫卡.config.并发卡夫卡接收容器工厂;6导入组织.弹簧框架。卡夫卡.核心.消费工厂;7导入组织.弹簧框架。卡夫卡默认卡夫卡消费者工厂;
89导入java。乌蒂尔.哈希地图;10导入java。乌蒂尔.地图;1112公共类消费者配置|1415私人静态最终字符串KAFKA_BROKER="本地主机:9092";16私人静态最终字符串GROUP_ID="卡夫卡-沙盒";17@Bean19公共消费工厂<字符串>消费工厂() |20返回新的DefaultKafka 消费者工厂<>(消费者配置));21}2223公共映射<字符串对象>使用者配置() |25映射<字符串对象>配置=新的哈希Map<> (;2627put(消费者Config. BOOTSTRAP_SERVERS_CONFIG,KAFKA_BROKER”28配置。put(消费者Config.GROUP_ID_CONFIGGROUP_ID);29配置。put(消费者Config.KEY_DESERIALIZER_CLASS_CONFIG字符串反序列化器。类);30配置。put(消费者Config.VALUE_DESERIALIZER_CLASS_CONFIG字符串反序列化器。类);3132返回配置;33}3435并发 Kafka Listener 容器工厂<字符串>工厂=新并发 Kafka Listener 容器工厂<> (;38工厂。集消费者工厂(消费者工厂());39返回工厂;40}4142}上面的代码创建一个工厂,知道如何连接到本地代理。它还会将使用者配置为对
String键和值进行反序列化,与生产者配置匹配。组 ID 是强制性的,Kafka 使用组 ID 来允许并行数据消耗。
ConcurrentKafkaListenerContainerFactoryBean 允许你的应用在多个线程中使用消息。现在,您的 Java 应用已配置为在 Kafka 代理中查找使用者,让我们开始收听发送到主题的消息。
创建一个
src/main/java/com/okta/javakafka/consumer目录,并在其中创建以下类: