

如今,人工智能似乎无处不在。新闻有关于诗歌写作AI的故事,专家认为AI是”新电”,甚至AI威士忌也将很快出现。当你尝试阅读这些文章时,通常会有大量的信息向你走来。模型、神经网络和深度学习等词汇频繁出现。但是,这些概念甚至意味着什么呢?通过这一系列博客文章,我们将解决您曾经提出的关于此主题的所有问题。
在第一部分中,我们将介绍机器学习、神经网络和深度学习的概念。您不需要之前任何有关这些主题的知识来关注本文,所以请安顿下来,继续阅读!
您可能还喜欢:机器学习入门指南:有抱负的数据科学家应该知道的
让您的知识发挥作用
让我们从一个基本概念开始:函数。是的,就像你在数学课上学到的一样。它们获取一个数字,使用它执行一些计算,并生成另一个数字。
y_f(x)
给定f和x,我们计算y。
您可以将所有计算机软件描述为某种功能。它们采用输入值(用户输入的内容)并提供一些输出。然后,此输出将显示在屏幕上、存储在文件中或发送到互联网。您可能听说过程序员编写软件。它通常的意思是,他们编写函数f,对用户输入的输入起作用。
那么,什么是机器学习呢?
在机器学习中,程序员不编写函数f供计算机应用它。相反,由计算机来学习函数 f。
(X,Y)_f
给定X和Y,我们学习将X转换为Y的函数f。
这个过程对计算机来说要困难得多。但它可能非常有用,尤其是当我们知道如何将 X 转换为 Y 时,但我们不知道如何将其描述为函数。
考虑区分猫和狗图片的任务。任何四岁的孩子都能做到,这太容易了。但是很难描述如何做出区分。这两种动物都有眼睛、耳朵、毛皮和尾巴。那么,你怎么能教别人区分猫和狗呢?
你给他们看一些动物的照片,很快他们就能分辨出猫和狗。我们也可以描述这一点,提供X(图片)和Y(各自的分类),让一个人学习f。
许多任务属于此类别。它们通常难以描述,但我们可以根据我们的经验和直觉来做到这一点例如图像分类、翻译、总结、欺诈检测等。
由于提供了函数的目标,因此这种机器学习称为监督学习。相反,当只提供输入 (X) 并且任务是在这些输入中查找结构时,则称为无监督学习。您可以使用具有某种通用性的组或群集进行无监督学习。
让我们开始学习功能
现在我们已经确定学习函数很有用,让我们来看看如何做到这一点。如何学习区分猫和狗图片的功能?还是预测明天的彩票中奖?这些都是棘手的问题。我们可以从将所学函数的范围缩小到更基本形式-线性函数的函数子集开始。
f(x)=wx=b
您始终可以将线性函数减小到以下基本结构:
以输入x为例,将其乘以w权重,然后添加偏置b。
在这里,学习函数f是找出w和b的足够值。这就像求解方程。如果这不是你的强项之一,不用担心,因为那也不是解决办法。当你有精确的解时,求解方程效果很好。在大多数真实数据中,您只有近似的解决方案。因此,您不会尝试在大多数机器学习问题中找到解决方案。相反,你试图找到最适合。
虽然我们可以在大多数真实数据中找到趋势,但数据正好位于趋势线上是不寻常的。
因此,学习我们的线性函数就像学习w和b,提供最适合我们拥有的数据。我们可以迭代,与w和b的小变化,调整我们的功能更接近目标。
机器学习框架(如TensorFlow)可帮助您学习这些线性函数。您可以提供正在学习的函数类型(在本例中为线性)、一些数据和成本函数。成本函数显示f预测的数据与目标相差多远。您可以调整变量 (如w和b) 以最小化成本函数。最小化成本函数可使预测数据更接近目标。
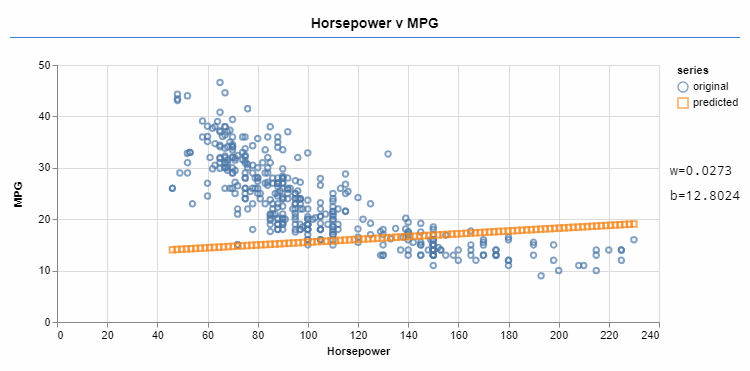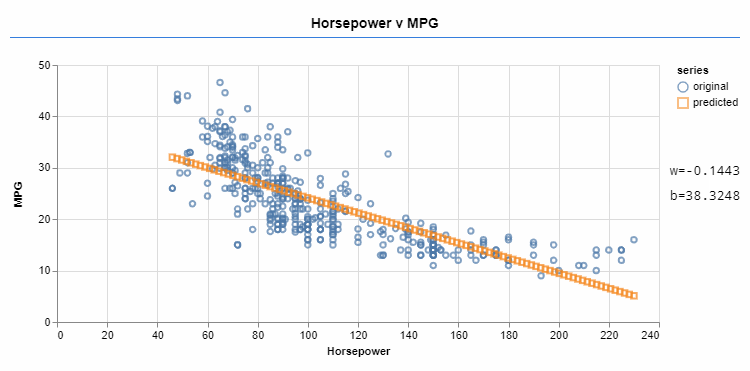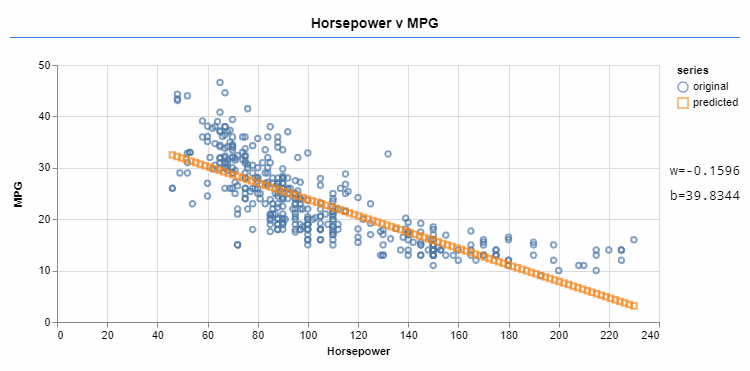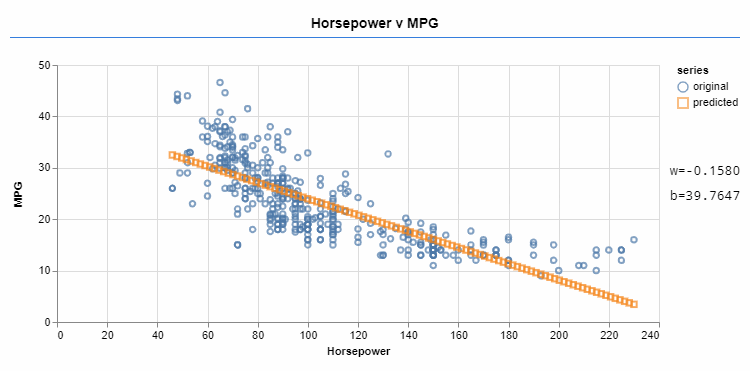
优化器迭代地更改 w 和 b 的值,将函数近似于目标数据。
世界线性的缺失
但是,所有函数都不是线性函数。许多需要解决的现实问题也不是线性的。将线性函数拟合到非线性问题可能会导致解决方案不佳。
优化器迭代地更改函数参数。sigmoid 激活可以更好地适应目标数据。
堆叠一些线性函数会产生另一个线性函数。答案在于用非线性激活(如 sigmoid 函数)堆叠线性函数对。这会产生一个组合的非线性函数,该函数越来越具有表现力。
它越来越冷,与深度学习分层
具有非线性激活的线性函数的堆叠对称为图层。网络的层越多,训练网络就越困难。但是,当涉及到适合您的数据的能力时,它也会变得更加强大。如果我们可视化这些许多图层,网络似乎有深度。因此,在网络中使用多个图层称为深度学习。
这给我们带来了另一个相关的术语,我们听到很多 – 一个模型。模型是迄今为止我们一直引用为f的学习函数。最近,添加更多图层是获取更强大机器学习模型的策略的一部分。
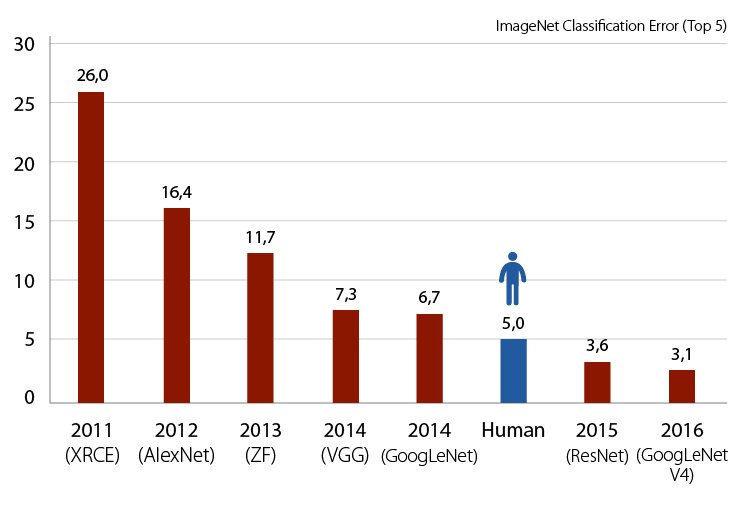
对于 ImageNet,一个众所周知的图像分类基准,通过更深的网络实现了更小的错误率(高达超人性能)。
数字在这里,数字在那里,数字无处不在
我们简化了学习任意函数的问题。我们现在知道,它类似于调整函数中采用数字和输出数字的数字。那么,我们如何从数字到图片和类别呢?
对于计算机来说,图片本质上是数字。图片以像素表示,像素具有颜色强度。因此,我们可以将任何图片分解为与这些强度相对应的数字矩阵。

如果我们得到一个具有正确形状的权重矩阵,并做矩阵乘法,我们可以从像素强度到类别分数。对于识别手写数字等任务,我们需要十个类别(每个数字一个)

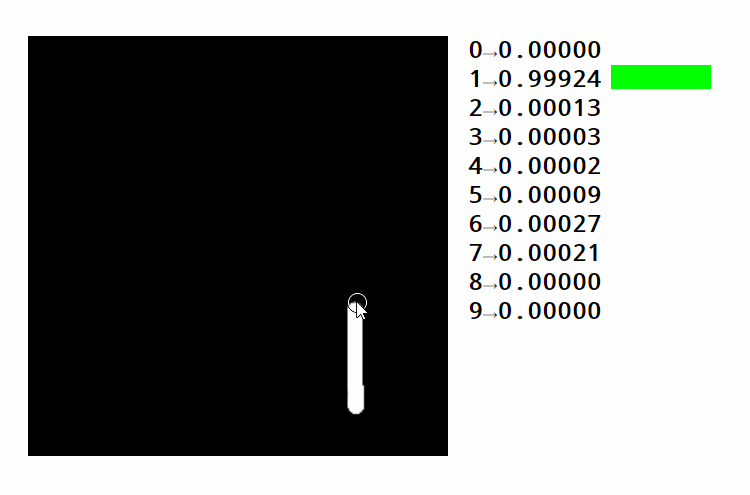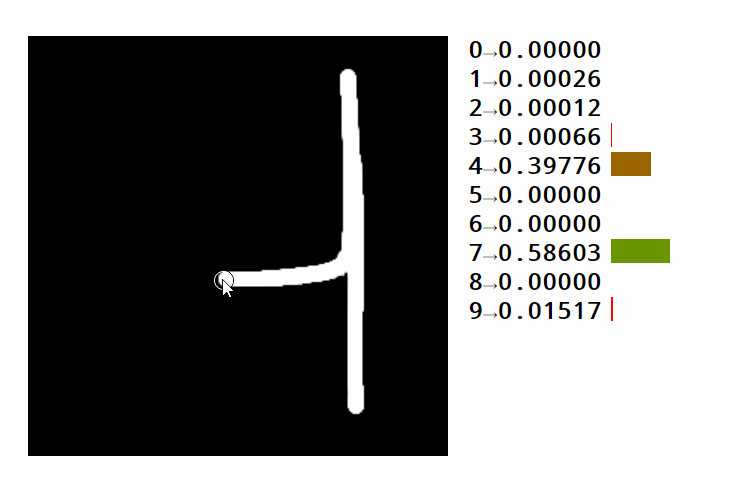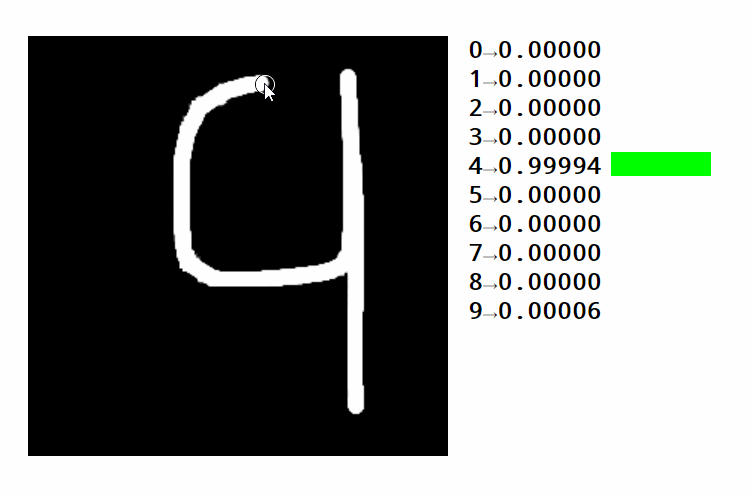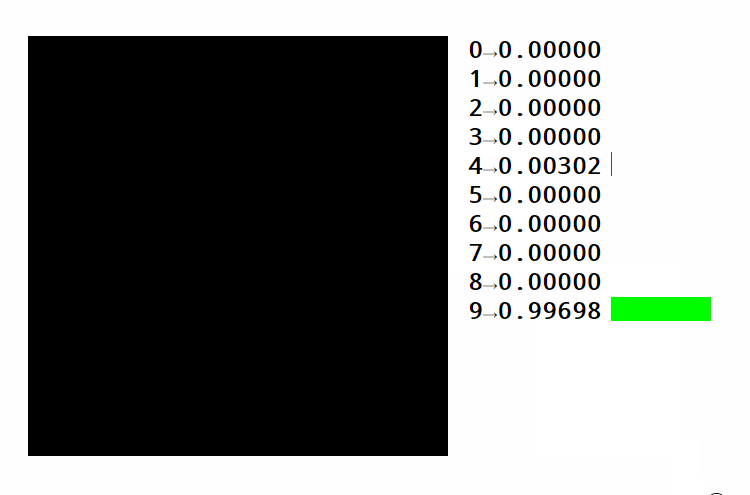
请看此示例。您可以看到不同区域如何激活不同的数字。您还可以了解如何使用相同的数字策略对图像进行分类。在这种情况下,我们将区分 10 个类别以上的手写数字的图片。文本通常使用数字序列进行编码。这些数字表示字典中每个单词的位置或字母表中每个字符的位置。这两种方法都有优点和缺点,我们现在没有进入。
以下是我们到目前为止所谈论的内容:
- 查找函数(类似于查找数字)
- 处理图像和文本(类似于处理数字)
- 对数字最高的结果槽进行分类或选取
神经网络结构:这是一个复杂物质
让我们回到图像识别示例。下图中标记为绿色的区域可能会激活数字 4 的类别。随着顶部空间的缩小,将四个变成九,四分的分数不断下降。

但是,很容易看出,即使输入的微小变化也会使其无法匹配相应的区域。这将导致网络提供错误的结果。

那么这里有什么问题呢?使数字看起来像四的不是图像的特定区域具有墨迹或没有墨迹的事实。这是墨迹线如何相互匹配,与它们在图像中的绝对位置无关。使用单个矩阵乘法,我们不能有图像的独立线条和形状的概念。我们只能根据图像的绝对位置对类别进行评分。
让我们在这里思考一个不同的机制。系统可以首先识别图像中的线和交点。然后,它可以将该信息馈送给第二个系统。然后,该系统将基于线条和交点是如何进行评分的更容易的时间分类。
我们已经使完整图像的矩阵乘法产生一个数字类别。现在,我们可以在图像的一个段上进行较小的矩阵乘法,从而产生有关该段的基本信息。我们不是对数字类别进行评分,而是对线、交点或空数进行评分。
假设我们对多个平铺段执行相同的乘法。然后,我们可以获取一组与原始图像具有空间关系的平铺输出。这些切片将具有一些更丰富的形状信息,而不是像素强度。在不同段上重复相同的操作,并平铺结果称为卷积。使用此策略的神经网络称为卷积神经网络 (CNN)。
在卷积下,同一操作可独立应用于许多图像段。与之前的图层一样,我们还可以堆叠卷积层。然后,每个段的输出将成为下一层的输入这是因为平铺。但是,当它查看线段(而不是单个点)并且切片可能重叠时,堆叠卷积可以使用周围的信息。这使得它们非常适合图像处理。
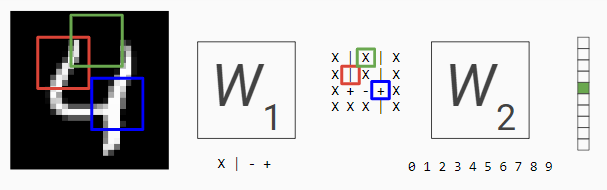
例如,让我们考虑上面的图像。原始图像具有 28×28 元素,具有一个强度维度。它被转换成具有四个强度维度的 4×4 图像。然后,它将转换为具有 10 个强度维度的单个元素,表示我们分类的十个类别。
在传统的卷积中,输入从大量元素(像素)开始。每个元素的信息量保持在较低(只是颜色强度)。当我们遍过这些图层时,元素的数量会减少,而每个元素的信息量也会增加。颜色强度被处理为类别分数。然后,它们被进一步加工为更多的类别。
让我们考虑一下复杂场景中的对象检测。
- 第一个图层将了解组合不同的像素强度如何表示基本形状类别(如线和角)。
- 下一个图层将了解这些基本形状的组合如何产生更复杂的形状(如门或眼睛)。
- 最后一层将学习这些层的组合如何产生更复杂的类别(如面或房子)。
基于 CNN 的体系结构非常适合图像处理问题。所有最先进的图像模型现在都以 CNN 为核心。这是因为体系结构如何接近手头的问题。在处理图像时,我们关注由较简单的形状构成的形状组合。
如果您想了解有关 CNN 的更多详细信息,请查看斯坦福 CS231n 笔记中关于卷积神经网络的精彩章节。
经常性主题
我们用眼睛读文字,用大脑解释每个单词。这是一个复杂的过程。我们设法密切注意我们已经读到的单词。然后,这些单词形成上下文。这个上下文进一步丰富了我们读到的每个新单词,直到它形成整个句子。
处理序列的神经网络可以遵循类似的方案。处理单元从空上下文开始。通过将每个序列元素作为输入,它将生成上下文的新版本。
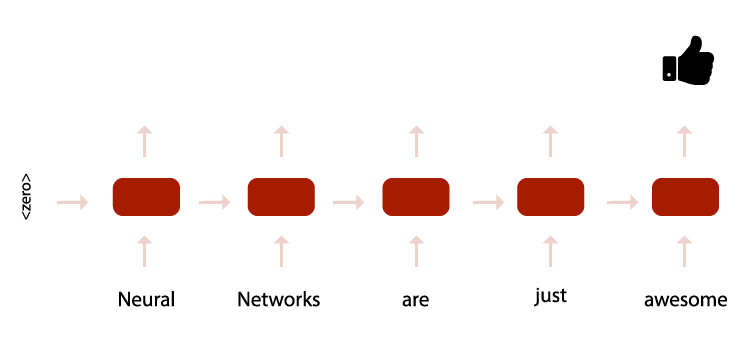 使用 NN 对句子的情绪进行分类 – 每个块处理一个单词,并将上下文传递给下一个句子,直到在末尾完成分类。
使用 NN 对句子的情绪进行分类 – 每个块处理一个单词,并将上下文传递给下一个句子,直到在末尾完成分类。
此处理单元将自己作为一个输出作为输入。因此,它被称为一个循环单位。
经常性网络更难训练。通过将输出作为输入馈送到同一层,我们创建了一个反馈回路,该反馈循环可能会导致小扰动。然后,这些小干扰在循环中被反复放大,导致最终结果发生重大变化。

在 RNN 中,同一块将重用给序列中的所有项
这种不稳定性是为复发付出代价的代价。这些网络在序列处理方面任务非常艰巨,这一事实弥补了这一点。循环神经网络 (RNN) 用于大多数最先进的文本和语音处理模型。它们用于总结、翻译或情感识别等任务。
如果你想了解更多关于RNN是如何工作的,以及它们在分类和生成文本方面的表现如何,我们建议安德烈·卡帕西在这篇很酷的博客文章中介绍循环神经网络的不合理有效性。
要被架构…
到目前为止,我们已经讨论了密集的神经网络。在这里,图层中的所有内容都与前一层中的所有内容相连。这些网络是最简单的。我们已经谈到CNN,以及它们如何有利于图像处理。我们讨论了RNN,以及它们如何有利于序列处理。
在当今世界,神经架构很重要。这些类型的体系结构有很多变化和组合。例如,处理视频(可视为图像序列)似乎是 RNN 的任务。这些RNN,反过来,有使用CNN的经常性单位。关于针对特定任务类型自动定制神经网络体系结构的研究领域也越来越多。
但是,有些数据类型不适合这些体系结构。一个例子是图表。一种称为”图形神经网络”的新型神经网络架构最近应运而生。在本系列的下一部分中,我们将重点介绍这些。
进一步阅读