

支持 R 中的矢量机
随着 AI 的指数级增长,机器学习正成为最受追捧的领域之一。顾名思义,机器学习是利用各种机器学习算法使机器通过数据进行学习的能力,在本博客中,我们将讨论 SVM 算法的工作原理、SVM 的各种功能以及它在现实世界中的使用方式。
您可能还喜欢:
分类算法简介
机器学习简介
机器学习是让计算机通过向计算机提供数据并让他们自己学习一些技巧来采取行动的科学,而无需显式编程。
机器学习的关键是数据。机器和我们人类一样学习。我们人类需要收集信息和数据来学习。同样,机器也必须提供数据,以便学习和决策。

为了理解机器学习,让我们考虑一个示例。假设您希望机器能够预测股票的价值。在这种情况下,只需向计算机提供相关数据。之后,必须创建用于预测股票价值的模型。
需要记住的一点是,您为机器提供的数据越多,它就越能学到并做出更准确的预测。
显然,ML 不是那么简单。机器要分析和从数据中获得有用的见解,就必须通过运行不同的算法来处理和研究数据。在本博客中,我们将讨论一种使用最广泛的算法,称为 SVM。
机器学习的类型
现在,您已经了解了机器学习的简要概念,让我们来看看机器学习的不同方式。
1. 监督学习
监督意味着监督或指导某项活动,并确保其正确完成。在这种类型的学习中,机器在指导下学习。
在学校,我们的老师指导我们并教导我们,同样在监督学习中,您向模型提供一组称为训练数据的数据,其中包含输入数据和相应的预期输出。培训数据充当教师,向模型教授特定输入的正确输出,以便它以后在提交新数据时能够做出准确的决策无监督学习
不受监督是指在没有任何人的监督或指示的情况下采取行动。
在无监督学习中,模型被指定一个既没有标记也不分类的数据集。该模型探索数据并从数据集中推断,以从未标记的数据中定义隐藏结构。
无监督学习的一个例子是像你和我这样的成年人。我们不需要一个指南来帮助我们的日常活动,我们解决的东西,我们自己的没有任何监督。

3. 强化学习
强化意味着建立或鼓励一种行为模式。假设你被丢在一个孤岛上,你会怎么办?
最初,你会惊慌失措,不确定该做什么,从哪里得到食物,如何生活,等等。但过了一会儿,你必须适应,你必须学会如何在岛上生活,适应不断变化的气候,并学会吃什么,不吃什么。
你遵循的是所谓的试验和错误概念,因为你是这个周围的新人,唯一的学习方法是体验,然后从你的经验中学习。
这就是强化学习。它是一种学习方法,其中代理(您,卡在岛上)通过生成操作并发现错误或奖励与其环境(岛屿)进行交互。
什么是 SVM?
SVM(支持向量机)是一种监督的机器学习算法,主要用于将数据分类到不同的类中。与大多数算法不同,SVM 使用超平面,它的作用类似于不同类之间的决策边界。
SVM 可用于生成多个分离的超平面,以便数据被划分为多个段,并且每个段仅包含一种数据。
 什么是 SVM?
什么是 SVM?
在进一步移动之前,让我们讨论 SVM 的功能:
- SVM 是一种监督式学习算法。这意味着 SVM 在一组标记的数据上进行训练。SVM 研究标记的训练数据,然后根据在培训阶段学到的内容对任何新的输入数据进行分类。
- SVM 的主要优点是可用于分类和回归问题。虽然 SVM 主要以分类著称,但 SVR(支持矢量回归器)用于回归问题。
- SVM 可用于使用内核技巧对非线性数据进行分类。内核技巧意味着将数据转换为另一个维度,该维度在数据类之间具有明确的划分幅度。之后,您可以轻松地在各种数据类别之间绘制超平面。
SVM 如何工作?
为了了解 SVM 的工作原理,让我们考虑一个方案。
一秒钟,假装你拥有一个农场,你有一个问题 – 你需要设置一个围栏,以保护你的兔子免受狼群。但是你在哪里建篱笆呢?
 所以,如果我这样做,并试图在兔子和狼之间划出一个决定边界,它看起来像这样。现在,你可以清楚地沿着这条线建造一道栅栏。
所以,如果我这样做,并试图在兔子和狼之间划出一个决定边界,它看起来像这样。现在,你可以清楚地沿着这条线建造一道栅栏。

简单地说,这正是 SVM 的工作原理。它绘制决策边界,即任意两个类之间的超平面,以便将它们分开或分类。
现在我知道你在想,你怎么知道在哪里画一架超飞机?
SVM 背后的基本原则是绘制一个超级平面,该超平面最好分隔 2 个类。在我们的例子中,这两类是兔子和狼。在进一步移动之前,让我们尝试了解什么是支持向量。
SVM 中什么是支持向量?
因此,首先绘制一个随机超平面,然后检查超平面与每个类中最近数据点之间的距离。这些与超平面最近的数据点称为支持向量。这就是名称的来源,支持向量机。
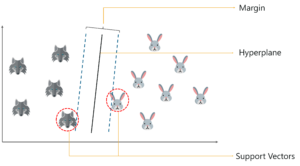 超平面基于这些支持向量绘制,最佳超平面将与每个支持向量具有最大距离。超平面与支撑向量之间的这种距离称为边距。
超平面基于这些支持向量绘制,最佳超平面将与每个支持向量具有最大距离。超平面与支撑向量之间的这种距离称为边距。
综上所述,SVM 用于使用超平面对数据进行分类,以便超平面与支撑向量之间的距离最大。
好吧,现在让我们试着去解决问题。
假设我输入了一个新的数据点,现在我想绘制一个超平面,以便最好地分隔这两个类。

因此,我首先绘制一个超平面,然后检查超平面与支撑向量之间的距离。在这里,我基本上是试图检查是否这个超平面的保证金是最大值。
 但如果我这样画超飞机呢?此超平面的边距明显高于前一个。所以,这是我最好的超平面。
但如果我这样画超飞机呢?此超平面的边距明显高于前一个。所以,这是我最好的超平面。

到目前为止,这已经相当容易了。我们的数据是线性可分离的,这意味着你可以画一条直线来分隔两个类!
但是,如果数据集是这样的,您将做什么?


这是实现非线性 SVM 的地方。
非衬里支持向量机
在本文的早些时候,我提到如何使用内核将数据转换为另一个维度,该维度在数据类之间具有明显的划分幅度。
内核函数为用户提供了将非线性空间转换为线性空间的选项。
在此之前,我们在二维空间上绘制数据。因此,我们只有 2 个变量,x 和 y。
一个简单的技巧是将两个变量x和y转换成一个新的要素空间,涉及一个新的变量z。 基本上,我们在一个三维空间上可视化数据。
将 2D 空间转换为 3D 空间时,可以清楚地看到两个数据类别之间的边距。现在,您可以通过在两个类之间绘制最佳超平面来继续分隔这两个类。
 非线性支持向量机
非线性支持向量机
这总结了非线性 SVM 背后的理念。要了解支持向量机的实际应用,我们来看一个用例。
用例 = SVM
自2000年初以来,SVM作为分类器一直用于癌症分类。
一组专业人士进行了一个实验,使用SVM对结肠癌组织进行分类。该数据集由大约 2000 个跨膜蛋白样本组成,只有大约 50-200 个基因样本输入到 SVM 分类器中。SVM的样本输入同时具有结肠癌组织样本和正常结肠组织。
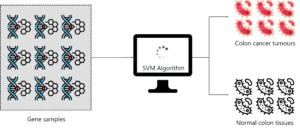
这项研究的主要目的是根据基因样本是否癌变对基因样本进行分类。因此,SVM使用50-200个样本进行训练,以便从肿瘤标本中区分非肿瘤。SVM 分类器的性能对于小型数据集也非常准确,其性能与其他分类算法(如 Naéve Bayes)进行了比较,在每种情况下,SVM 都优于 Naive Bayes。
因此,经过这个实验,SVM 显然可以更有效地对数据进行分类,并且它对小型数据集非常有效。
支持矢量机演示
好了,现在让我们进入实际部分。我们将运行一个演示,以更好地了解如何将 SVM 用作分类器。
很多人有这个问题在心中:
R 中的 SVM 是什么?
答案是,R基本上是一个开源统计,编程语言主要用于数据科学领域。
问题陈述
研究心脏病数据集,并建模分类器,以预测患者是否患有任何心脏病。
在本演示中,我们将使用 caret 包。caret 包也称为分类和回归训练,具有大量有助于构建预测模型的功能。它包含用于数据拆分、预处理、功能选择、调优、无监督学习算法等的工具。
因此,要使用它,我们首先需要使用这个命令来安装它:
install.packages(“caret”)caret 包非常有用,因为它为我们提供了对各种功能的直接访问,以便使用各种机器学习算法(如 KNN、SVM、决策树、线性回归等)来训练模型。
安装后,我们只需要将包加载到我们的控制台中,我们才具有以下代码:
library('caret')我们的下一步是加载数据集。
在本演示中,我们将使用心脏病数据集,该数据集由各种属性组成,如人的年龄、性别、胆固醇水平等。在同一个数据集中,我们将有一个目标变量,用于预测患者是否患有任何心脏病
简而言之,我们将使用 SVM 来分类一个人是否容易患心脏病。
数据集如下所示:
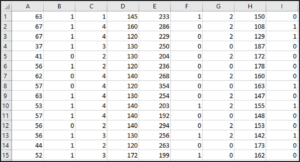 此数据集包含大约 14 个属性,最后一个属性是目标变量,我们将使用 SVM 模型预测该变量。
此数据集包含大约 14 个属性,最后一个属性是目标变量,我们将使用 SVM 模型预测该变量。
现在是时候加载数据集了:
heart <- read.csv("/Users/zulaikha/Desktop/heart_dataset.csv", sep = ',', header = FALSE)在上述代码行中,我们正在读取以 CSV 格式存储的数据集,这就是为什么我们使用 read.csv 函数从指定的路径读取数据集的原因。
“sep”属性表示数据存储在 CSV 或逗号分隔版本中。
导入数据集后,让我们检查数据集的结构:
为了检查数据框的结构,我们可以调用函数 str():
str(heart)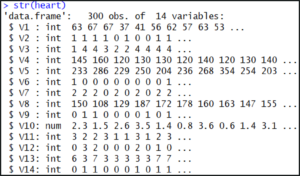
输出显示我们的数据集由 300 个观测值组成,每个观测值包含 14 个属性。
如果要显示数据集的前 5-6 行,请使用 head() 函数:
head(heart)我们将专门使用针对模型构建的训练集和用于评估模型的测试集:
intrain <- createDataPartition(y = heart$V14, p= 0.7, list = FALSE)
training <- heart[intrain,]
testing <- heart[-intrain,]caret 包提供了一个创建DataPartition()的方法,它基本上用于将数据分区到训练和测试集中。
我们向此 createdatapartition() 函数传递了 3 个参数:
- “y”参数取取需要根据哪些数据进行分区的变量值。在我们的例子中,目标变量在V14,所以我们传递心脏$V14
- “p”参数在 0-1 的范围内保存十进制值。它是显示拆分的百分比。我们使用的是 p=0.7。这意味着数据拆分应以 70:30 的比例完成。因此,70% 的数据用于培训,其余 30% 用于测试模型。
- “列表”参数用于是否返回列表或矩阵。我们传递 FALSE 不返回列表
现在,此创建数据分区()方法返回矩阵”在训练”。此训练矩阵具有我们的训练数据集,我们将此数据存储在”训练”变量和其他数据中,即剩余的 30% 数据存储在测试变量中。
接下来,为了检查训练数据框和测试数据框的维度,我们可以使用:
dim(training);
dim(testing);我们的下一步是清理数据,因此,如果有任何缺失值或不一致的值,必须在构建定型模型之前处理它们
我们将使用 anyNA() 方法,该方法检查任何 null 值:
anyNA(heart)运行此项时,我们将返回值作为 false,这意味着我们的数据集中没有缺失值。
接下来,我们使用摘要() 函数检查数据的摘要
summary(heart)例如,V14 变量(作为我们的目标变量)仅包含 2 个值,可以是 0 或 1。
相反,这应该是一个分类变量。要将这些变量转换为分类变量,我们需要将它们分解:
training[["V14"]] = factor(training[["V14"]])上述代码将训练数据框的”V14″列转换为因子变量。
我们的下一步是训练我们的模型。
在训练模型之前,我们将首先实现trainControl()方法。这将控制所有计算开销,以便我们可以使用 caret 包提供的 train() 函数。训练方法将训练我们基于不同算法的数据。
首先,让我们关注一下训练控制()方法:
trctrl <- trainControl(method = "repeatedcv", number = 10, repeats = 3)此处的 trainControl() 方法采用 3 个参数。
- “方法”参数定义了重采样方法,在此演示中,我们将使用重复cv或重复交叉验证方法。
- 下一个是”数字”参数,它基本上保存了重采样迭代的数量。
- “重复”参数包含要计算的重复交叉验证的集。我们使用设置编号 #10 并重复 #3
此训练控制() 方法返回列表。我们将在火车方法上传递这个。
svm_Linear <- train(V14 ~., data = training, method = "svmLinear",
trControl=trctrl,
preProcess = c("center", "scale"),
tuneLength = 10)训练()方法应用”方法”参数作为”svm线性”传递。我们正在传递目标变量 V14。”V14+”表示使用分类器和 V14 中的所有属性作为目标变量的公式。”trControl”参数应随三元控制() 方法的结果一起传递。”预处理”参数用于预处理我们的训练数据。
我们在”预处理”、”中心”和”缩放”参数中传递 2 个值
预处理后,这些将我们的训练数据将平均值转换为近似”0″,标准偏差转换为”1″。”调谐长度”参数包含整数值。这是为了调整我们的算法。
你可以检查我们的火车()方法的结果。我们正在将其结果保存在svm_Linear变量中。
svm_Linear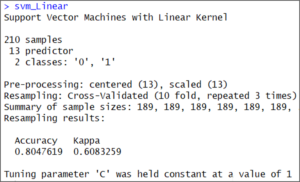 这是一个线性模型。因此,它只需在值”C”^1 处进行测试。
这是一个线性模型。因此,它只需在值”C”^1 处进行测试。
现在,我们的模型被训练为 C 值为 1。我们已准备好预测测试集的类。我们可以使用预测()方法。
caret 包提供预测结果的预测方法。我们正在传递两个参数。它的第一个参数是我们经过训练的模型,第二个参数”新数据”保存着我们的测试数据框。预测() 方法返回一个列表,我们将它保存在test_pred变量中。
test_pred <- predict(svm_Linear, newdata = testing)
test_pred confusionMatrix(table(test_pred, testing$V14))
confusionMatrix(table(test_pred, testing$V14))
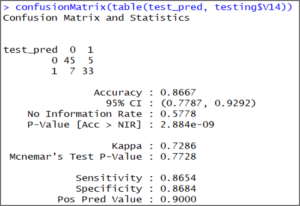 输出表明,测试集的模型精度为86.67%。
输出表明,测试集的模型精度为86.67%。
通过执行上述过程,我们可以构建 svm线性分类器。
在线性分类器中选择 C 值(成本)时,还可以进行一些自定义。这可以通过在网格搜索中输入值来实现。
下一个代码段将向您展示,构建和调整具有不同 C 值的 SVM 分类器。
我们将使用 expand.grid() 将 C 的一些值放入”网格”数据帧中。下一步是使用此数据帧测试特定 C 值的分类器。它需要放在带调谐网格参数的 train() 方法中。
grid <- expand.grid(C = c(0,0.01, 0.05, 0.1, 0.25, 0.5, 0.75, 1, 1.25, 1.5, 1.75, 2,5))
svm_Linear_Grid <- train(V14 ~., data = training, method = "svmLinear",
trControl=trctrl,
preProcess = c("center", "scale"),
tuneGrid = grid,
tuneLength = 10)
svm_Linear_Grid
plot(svm_Linear_Grid)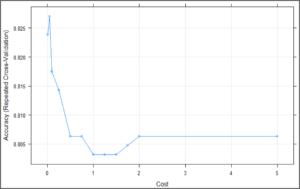 test_pred_grid <- predict(svm_Linear_Grid, newdata = testing)
test_pred_grid
test_pred_grid <- predict(svm_Linear_Grid, newdata = testing)
test_pred_grid
让我们用混淆矩阵来检查它的准确性。
confusionMatrix(table(test_pred_grid, testing$V14))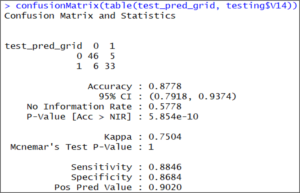
混淆矩阵的结果表明,这次测试集的准确率为87.78%,比之前的结果更准确。
有了这个,我们来到这个博客的结尾。我希望你发现这个信息丰富和有帮助。