
关于Flink流式计算节省资源方面你必须知道的技巧

小米在流式计算方面经历了Storm、Spark Streaming和Flink的发展历程;从2019年1月接触Flink到现在,已经过去了大半年的时间了。
对Flink的接触越深,越能感受到它在流式计算方面的强大能力;无论是实时性、时间语义还是对状态计算的支持等,都让很多之前需要复杂业务逻辑实现的功能转变成了简洁的API调用。还有不断完善的Flink SQL功能也让人充满期待,相信实时数据分析的门槛会越来越低,更多的业务能够挖掘出数据更实时更深入的价值。
在这期间,我们逐步完善了稳定性、作业管理、日志和监控收集展示等关系到用户易用性和运维能力的特性,帮助越来越多的业务接入到了Flink。
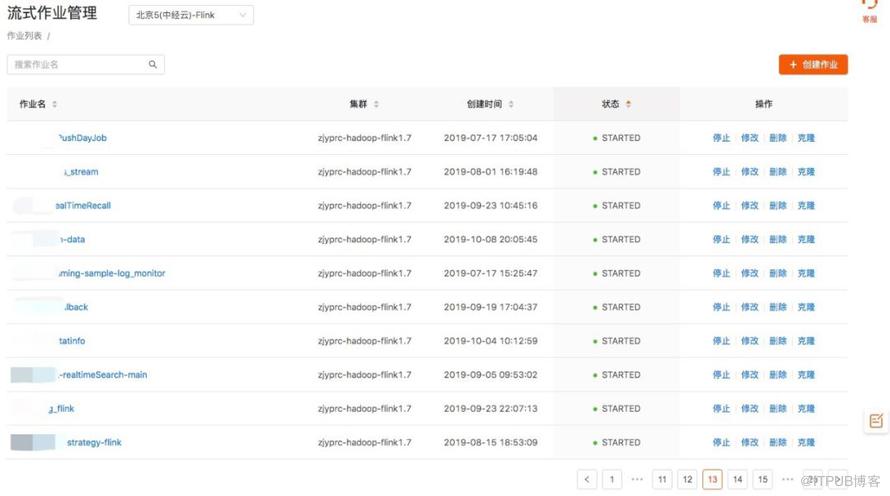
流式作业管理服务的界面:
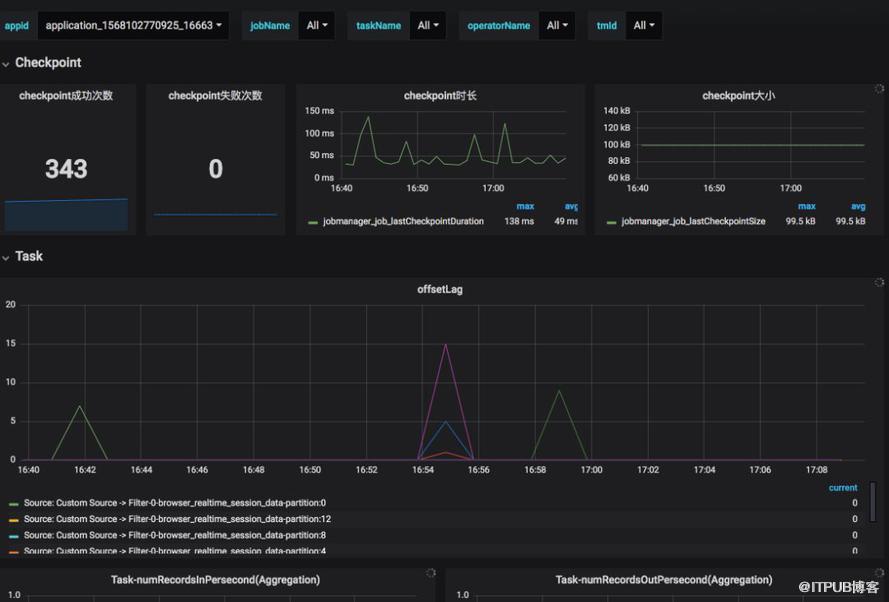
Flink作业的监控指标收集展示:
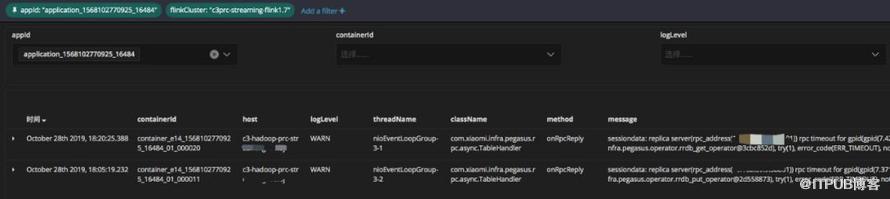
Flink作业异常日志的收集展示:
Spark Streaming 迁移到Flink的效果小结
在业务从Spark Streaming迁移到Flink的过程中,我们也一直在关注着一些指标的变化,比如数据处理的延迟、资源使用的变化、作业的稳定性等。其中有一些指标的变化是在预期之中的,比如数据处理延迟大大降低了,一些状态相关计算的“准确率”提升了;但是有一项指标的变化是超出我们预期的,那就是节省的资源。
信息流推荐业务是小米从Spark Streaming迁移到Flink流式计算最早也是使用Flink最深的业务之一,在经过一段时间的合作优化后,对方同学给我们提供了一些使用效果小结,其中有几个关键点:
- 对于无状态作业,数据处理的延迟由之前Spark Streaming的16129ms降低到Flink的926ms,有94.2%的显著提升(有状态作业也有提升,但是和具体业务逻辑有关,不做介绍);
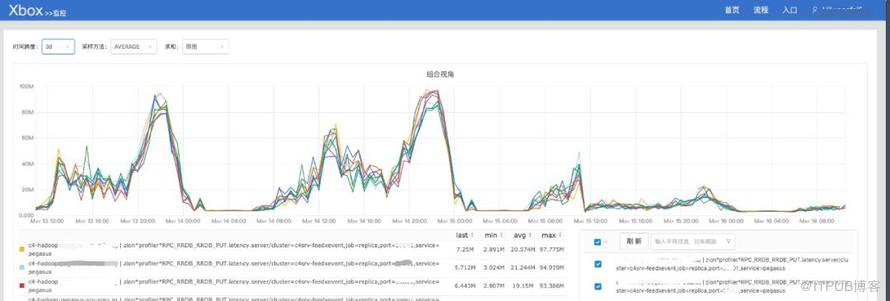
- 对后端存储系统的写入延迟从80ms降低到了20ms左右,如下图(这是因为Spark Streaming的mini batch模式会在batch最后有批量写存储系统的操作,从而造成写请求尖峰,Flink则没有类似问题):
- 对于简单的从消息队列Talos到存储系统HDFS的数据清洗作业(ETL),由之前Spark Streaming的占用210个CPU Core降到了Flink的32个CPU Core,资源利用率提高了84.8%;
其中前两点优化效果是比较容易理解的,主要是第三点我们觉得有点超出预期。为了验证这一点,信息流推荐的同学帮助我们做了一些测试,尝试把之前的Spark Streaming作业由210个CPU Core降低到64个,但是测试结果是作业出现了数据拥堵。这个Spark Streaming测试作业的batch interval 是10s,大部分batch能够在8s左右运行完,偶尔抖动的话会有十几秒,但是当晚高峰流量上涨之后,这个Spark Streaming作业就会开始拥堵了,而Flink使用32个CPU Core却没有遇到拥堵问题。
很显然,更低的资源占用帮助业务更好的节省了成本,节省出来的计算资源则可以让更多其他的业务使用;为了让节省成本能够得到“理论”上的支撑,我们尝试从几个方面研究并对比了Spark Streaming和Flink的一些区别:
调度计算VS调度数据
对于任何一个分布式计算框架而言,如果“数据”和“计算”不在同一个节点上,那么它们中必须有一个需要移动到另一个所在的节点。如果把计算调度到数据所在的节点,那就是“调度计算”,反之则是“调度数据”;在这一点上Spark Streaming和Flink的实现是不同的。
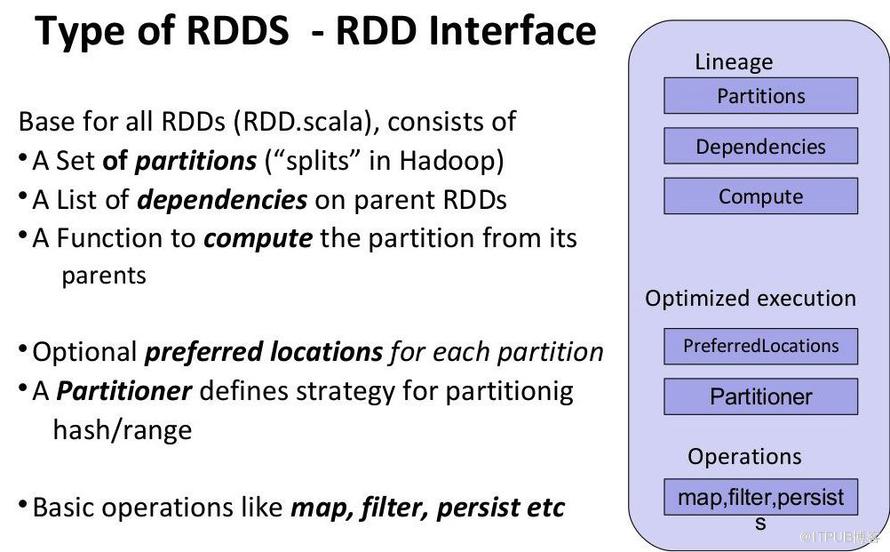
Spark的核心数据结构RDD包含了几个关键信息,包括数据的分片(partitions)、依赖(dependencies)等,其中还有一个用于优化执行的信息,就是分片的“preferred locations”
// RDD
/**
* Optionally overridden by subclasses to specify placement preferences.
*/
protected def getPreferredLocations(split: Partition): Seq[String] = Nil”调度计算”的方法在批处理中有很大的优势,因为“计算”相比于“数据”来讲一般信息量比较小,如果“计算”可以在“数据”所在的节点执行的话,会省去大量网络传输,节省带宽的同时提高了计算效率。但是在流式计算中,以Spark Streaming的调度方法为例,由于需要频繁的调度”计算“,则会有一些效率上的损
耗。首先,每次”计算“的调度都是要消耗一些时间的,比如“计算”信息的序列化 → 传输 → 反序列化 → 初始化相关资源 → 计算执行→执行完的清理和结果上报等,这些都是一些“损耗”。
另外,用户的计算中一般会有一些资源的初始化逻辑,比如初始化外部系统的客户端(类似于Kafka Producer或Consumer);每次计算的重复调度容易导致这些资源的重复初始化,需要用户对执行逻辑有一定的理解,才能合理地初始化资源,避免资源的重复创建;这就提高了使用门槛,容易埋下隐患;通过业务支持发现,在实际生产过程中,经常会遇到大并发的Spark Streaming作业给Kafka或HBase等存储系统带来巨大连接压力的情况,就是因为用户在计算逻辑中一直重复创建连接。
Spark在官方文档提供了一些避免重复创建网络连接的示例代码,其核心思想就是通过连接池来复用连接:
这个信息提供了该分片数据的位置信息,即所在的节点;Spark在调度该分片的计算的时候,会尽量把该分片的计算调度到数据所在的节点,从而提高计算效率。比如对于KafkaRDD,该方法返回的就是topic partition的leader节点信息:
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}需要指出的是,即使用户代码层面合理的使用了连接池,由于同一个“计算”逻辑不一定调度到同一个计算节点,还是可能会出现在不同计算节点上重新创建连接的情况。
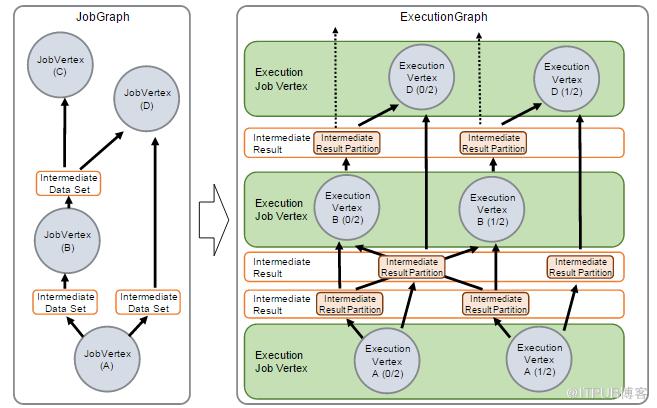
Flink和Storm类似,都是通过“调度数据”来完成计算的,也就是“计算逻辑”初始化并启动后,如果没有异常会一直执行,源源不断地消费上游的数据,处理后发送到下游;有点像工厂里的流水线,货物在传送带上一直传递,每个工人专注完成自己的处理逻辑即可。
虽然“调度数据”和“调度计算”有各自的优势,但是在流式计算的实际生产场景中,“调度计算”很可能“有力使不出来”;比如一般流式计算都是消费消息队列Kafka或Talos的数据进行处理,而实际生产环境中为了保证消息队列的低延迟和易维护,一般不会和计算节点(比如Yarn服务的节点)混布,而是有各自的机器(不过很多时候是在同一机房);所以无论是Spark还是Flink,都无法避免消息队列数据的跨网络传输。所以从实际使用体验上讲,Flink的调度数据模式,显然更容易减少损耗,提高计算效率,同时在使用上更符合用户“直觉”,不易出现重复创建资源的情况。
不过这里不得不提的一点是,Spark Streaming的“调度计算”模式,对于处理计算系统中的“慢节点”或“异常节点”有天然的优势。比如如果Yarn集群中有一台节点磁盘存在异常,导致计算不停地失败,Spark可以通过blacklist机制停止调度计算到该节点,从而保证整个作业的稳定性。或者有一台计算节点的CPU Load偏高,导致处理比较慢,Spark也可以通过speculation机制及时把同一计算调度到其他节点,避免慢节点拖慢整个作业;而以上特性在Flink中都是缺失的。
Mini batch vs streaming
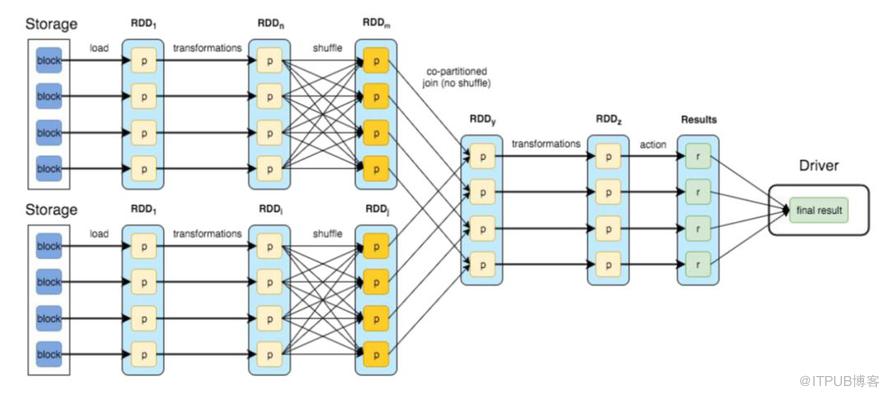
Spark Streaming并不是真正意义上的流式计算,而是从批处理衍生出来的mini batch计算。如图所示,Spark根据RDD依赖关系中的shuffle dependency进行作业的Stage划分,每个Stage根据RDD的partition信息切分成不同的分片;在实际执行的时候,只有当每个分片对应的计算结束之后,整个个Stage才算计算完成。
这种模式容易出现“长尾效应”,比如如果某个分片数据量偏大,那么其他分片也必须等这个分片计算完成后,才能进行下一轮的计算(Spark speculation对这种情况也没有好的作用,因为这个是由于分片数据不均匀导致的),这样既增加了其他分片的数据处理延迟,也浪费了资源。
而Flink则是为真正的流式计算而设计的(并且把批处理抽象成有限流的数据计算),上游数据是持续发送到下游的,这样就避免了某个长尾分片导致其他分片计算“空闲”的情况,而是持续在处理数据,这在一定程度上提高了计算资源的利用率,降低了延迟。
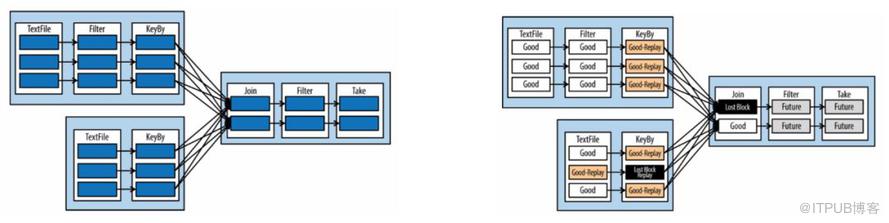
当然,这里又要说一下mini batch的优点了,那就在异常恢复的时候,可以以比较低的代价把缺失的分片数据恢复过来,这个主要归功于RDD的依赖关系抽象;如上图所示,如果黑色块表示的数据丢失(比如节点异常),Spark仅需要通过重放“Good-Replay”表示的数据分片就可以把丢失的数据恢复,这个恢复效率是很高的。
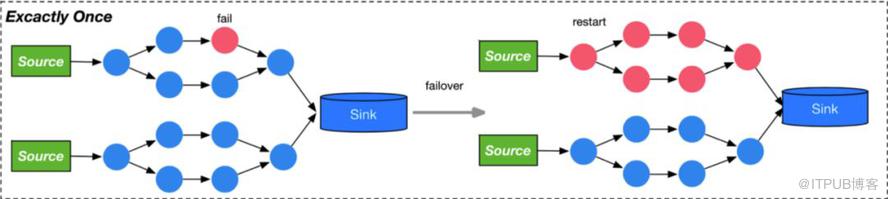
而Flink的话则需要停止整个“流水线”上的算子,并从Checkpoint恢复和重放数据;虽然Flink对这一点有一些优化,比如可以配置failover strategy为region来减少受影响的算子,不过相比于Spark只需要从上个Stage的数据恢复受影响的分片来讲,代价还是有点大。
总之,通过对比可以看出,Flink的streaming模式对于低延迟处理数据比较友好,Spark的mini batch模式则于异常恢复比较友好;如果在大部分情况下作业运行稳定的话,Flink在资源利用率和数据处理效率上确实更占优势一些。
数据序列化
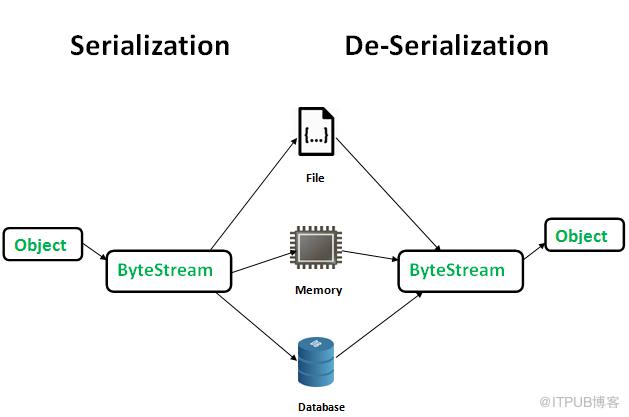
简单来说,数据的序列化是指把一个object转化为byte stream,反序列化则相反。序列化主要用于对象的持久化或者网络传输。
常见的序列化格式有binary、json、xml、yaml等;常见的序列化框架有Java原生序列化、Kryo、Thrift、Protobuf、Avro等。
对于分布式计算来讲,数据的传输效率非常重要。好的序列化框架可以通过较低 的序列化时间和较低的内存占用大大提高计算效率和作业稳定性。在数据序列化上,Flink和Spark采用了不同的方式;Spark对于所有数据默认采用Java原生序列化方式,用户也可以配置使用Kryo;而Flink则是自己实现了一套高效率的序列化方法。
首先说一下Java原生的序列化方式,这种方式的好处是比较简单通用,只要对象实现了Serializable接口即可;缺点就是效率比较低,而且如果用户没有指定serialVersionUID的话,很容易出现作业重新编译后,之前的数据无法反序列化出来的情况(这也是Spark Streaming Checkpoint的一个痛点,在业务使用中经常出现修改了代码之后,无法从Checkpoint恢复的问题);当然Java原生序列化还有一些其他弊端,这里不做深入讨论。
有意思的是,Flink官方文档里对于不要使用Java原生序列化强调了三遍,甚至网上有传言Oracle要抛弃Java原生序列化:


相比于Java原生序列化方式,无论是在序列化效率还是序列化结果的内存占用上,Kryo则更好一些(Spark声称一般Kryo会比Java原生节省10x内存占用);Spark文档中表示它们之所以没有把Kryo设置为默认序列化框架的唯一原因是因为Kryo需要用户自己注册需要序列化的类,并且建议用户通过配置开启Kryo。
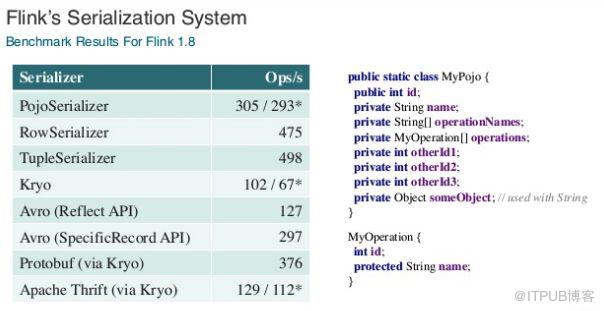
虽然如此,根据Flink的测试,Kryo依然比Flink自己实现的序列化方式效率要低一些;如图所示是Flink序列化器(PojoSerializer、RowSerializer、TupleSerializer)和Kryo等其他序列化框架的对比,可以看出Flink序列化器还是比较占优势的:
那么Flink到底是怎么做的呢?网上关于Flink序列化的文章已经很多了,这里我简单地说一下我的理解。
像Kryo这种序列化方式,在序列化数据的时候,除了数据中的“值”信息本身,还需要把一些数据的meta信息也写进去(比如对象的Class信息;如果是已经注册过的Class,则写一个更节省内存的ID)。
但是在Flink场景中则完全不需要这样,因为在一个Flink作业DAG中,上游和下游之间传输的数据类型是固定且已知的,所以在序列化的时候只需要按照一定的排列规则把“值”信息写入即可(当然还有一些其他信息,比如是否为null)。
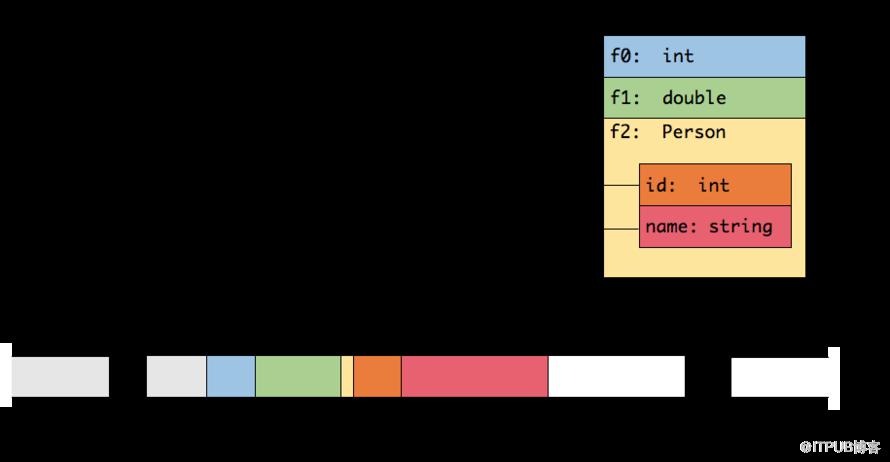
如图所示是一个内嵌POJO的Tuple3类型的序列化形式,可以看出这种序列化方式非常地“紧凑”,大大地节省了内存并提高了效率。另外,Flink自己实现的序列化方式还有一些其他优势,比如直接操作二进制数据等。
凡事都有两面性,自己实现序列化方式也是有一些劣势,比如状态数据的格式兼容性(State Schema Evolution);如果你使用Flink自带的序列化框架序进行状态保存,那么修改状态数据的类信息后,可能在恢复状态时出现不兼容问题(目前Flink仅支持POJO和Avro的格式兼容升级)。
另外,用户为了保证数据能使用Flink自带的序列化器,有时候不得不自己再重写一个POJO类,把外部系统中数据的值再“映射”到这个POJO类中;而根据开发人员对POJO的理解不同,写出来的效果可能不一样,比如之前有个用户很肯定地说自己是按照POJO的规范来定义的类,我查看后发现原来他不小心多加了个logger,这从侧面说明还是有一定的用户使用门槛的。
// Not a POJO demo.public class Person { private Logger logger = LoggerFactory.getLogger(Person.class); public String name; public int age;}
针对这一情况我们做了一些优化尝试,由于在小米内部很多业务是通过Thrfit定义的数据,正常情况下Thrift类是通过Kryo的默认序列化器进行序列化和反序列化的,效率比较低。虽然官方提供了优化文档,可以通过如下方式进行优化,但是对业务来讲也是存在一定使用门槛;
// KafkaRDD
override def getPreferredLocations(thePart: Partition): Seq[String] = {
val part = thePart.asInstanceOf[KafkaRDDPartition]
Seq(part.host)
// host: preferred kafka host, i.e. the leader at the time the rdd was created
}于是我们通过修改Flink中Kryo序列化器的相关逻辑,实现了对Thrfit类默认使用Thrift自己序列化器的优化,在大大提高了数据序列化效率的同时,也降低了业务的使用门槛。
总之,通过自己定制序列化器的方式,确实让Flink在数据处理效率上更有优势,这样作业就可以通过占用更低的带宽和更少的计算资源完成计算了。
本文小结
Flink和Spark Streaming有非常大的差别,也有各自的优势,这里我只是简单介绍了一下自己浅薄的理解,不是很深入。不过从实际应用效果来看,Flink确实通过高效的数据处理和资源利用,实现了成本上的优化;希望能有更多业务可以了解并试用Flink,后续我们也会通过Flink SQL为更多业务提供简单易用的流式计算支持,谢谢!
参考文献
{1}《Deep Dive on Apache Flink State》 – Seth Wiesmanhttps://www.slideshare.net/dataArtisans/webinar-deep-dive-on-apache-flink-state-seth-wiesman
{2}Flink 原理与实现:内存管理https://ververica.cn/developers/flink-principle-memory-management
{3}Batch Processing — Apache Sparkhttps://blog.k2datascience.com/batch-processing-apache-spark-a67016008167